Loss calculation of image segmentation
-
기본적으로 semantic segmantation의 평가 방법은 분류 모델과 Loss 계산 방법이 유사하다. Cross entropy를 기반으로 하여 계산을 한다는 점에서 공통점을 보인다. 하지만 똑같은 크기의 이미지를 입력을 가진다고 하지만 분류모델의 출력은 벡터로 나오고, 세그멘테이션 모델은 동일한 크기의 이미지와 동일한 (W * H) 를 가지는 3차원 텐서로 출력이 나올것이다.
즉 한장의 이미지를 학습하더라도 결과로 나오는 라벨의 갯수의 차이가 엄청나게 발생하게 되는데 이부분에 대해서 주목할 필요가 있음1. Focal loss
-
Focal loss를 이해하기 전에 우선 cross entropy 공식을 보면 의 값을 주목해야 될 필요가 있는데, N개의 클래스에서 특정 클래스의 라벨이 Ground Truth에 많이 있다면 해당 라벨만 과도하게 학습되는 image imblance 문제가 발생할 가능성이 높다.
: 실제 레이블을 나타내는 one hot 벡터
: : 모델의 예측결과를 나타내는 벡터
- 이 문제를 해결하기 위해서 Focal loss는 기존 공식에서 가중치를 추가하여, 분류가 어려운 모델에서 가중치를 더 많이 주도록 가중치를 추가한다.
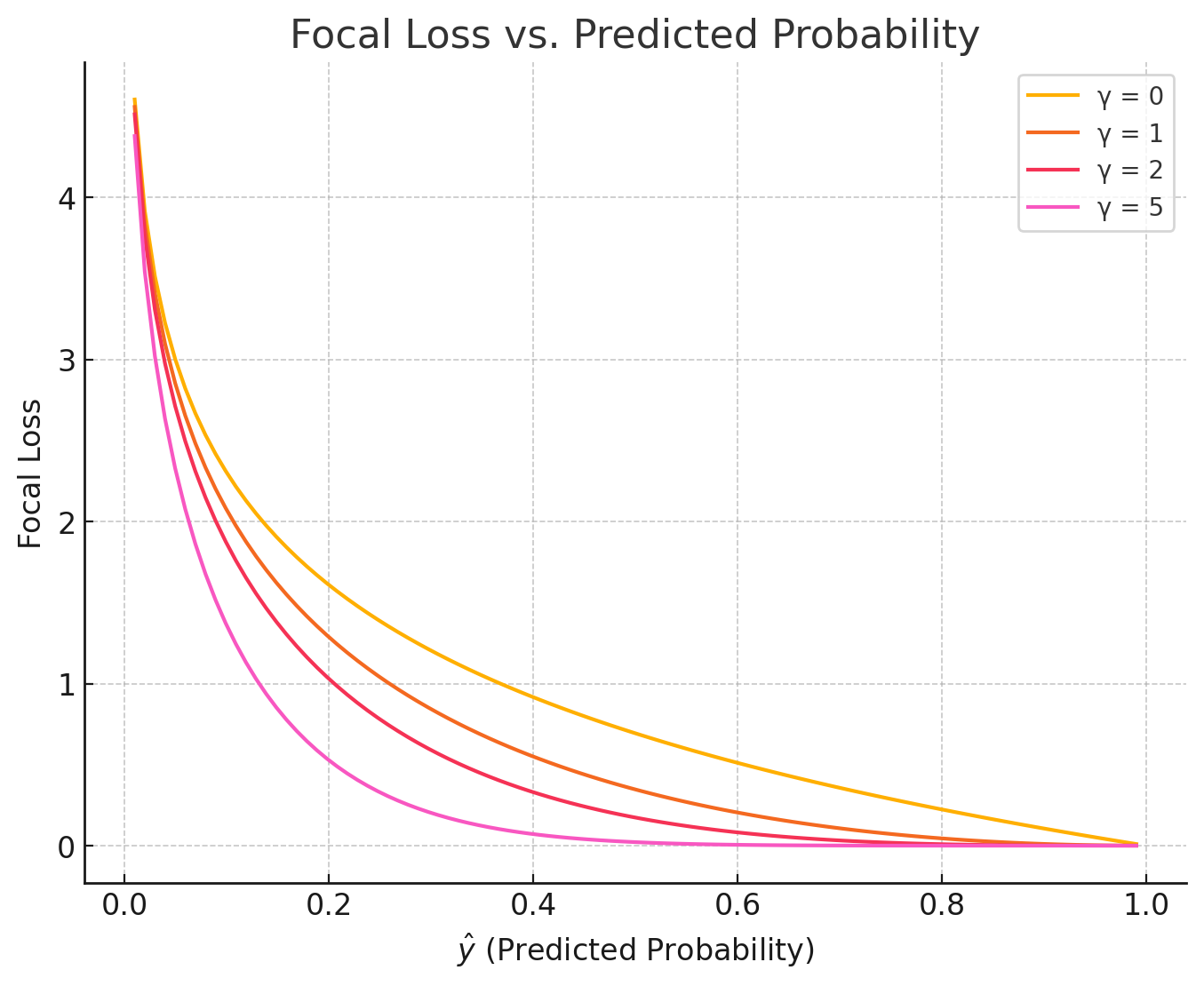
- 그래프를 보게 되면 Y() 값이 커질수록 낮은 확률의 클래스에 가중치가 집중되는것을 확인이 할 수 있다. 즉 몇 %의 확률 을 기준으로하여 가중을 줄지 결정 한다.
- 일 때, 값의 변화에 따른 분포를 보면 아래와 같다. gamma로 확률의 기준점이 정해진 상태에서 소수 클래스를 얼마나 강조할 것인지 결정하는 파라미터. 0에 가까워 질수록 클래스간 가중치 차이가 적어지게 되고, 1에 가까워 질수록 확률이 낮은 클래스에 많은 가중치가 부여 된다.
2. Soft-dice Loss
- Focal Loss는 픽셀 분류에서 불균형을 해결하기 위해서 등장한 방법이지만 segmentation 역시 detection과 동일하게 얼마나 Ground Truth와 매칭이 되는지 평가하는것이 중요하다.

출처 : https://learnopencv.com/intersection-over-union-iou-in-object-detection-and-segmentation/
- 즉 위의 이미지와 같이 예측된 마스크와 GT 마스크가 얼마나 똑같은지 평가를 하는것이 중요하다. 이를 평가하기 위해서 등장한 방법이 Soft-Dice Loss이다.
- : i번째 위치에서 클래스가 참일 확률
- : i번째 위치에서 실제 마스크의 참/거짓 여부
- 여기서 특이 한점이 있다면 Confusion matrix의 지표를 쓰는 Iou스코어와 달리 확률값을 통해서 계산하기 때문에 Loss계산이 가능하다는 점이 있어서 실제 Loss 계산에서 활용 되는점이 강점이다.

imageprocessing and Data science