Deep Residual Learning for Image Recognition 논문정리
1. introduction
1.1 도입 배경
- 2014 VGG NET 및 googlenet에서 레이어를 증가 시킬수 있는 모델에 대한 아이디어를 통해 Layer를 늘릴려고 하는 시도를 많이 했음
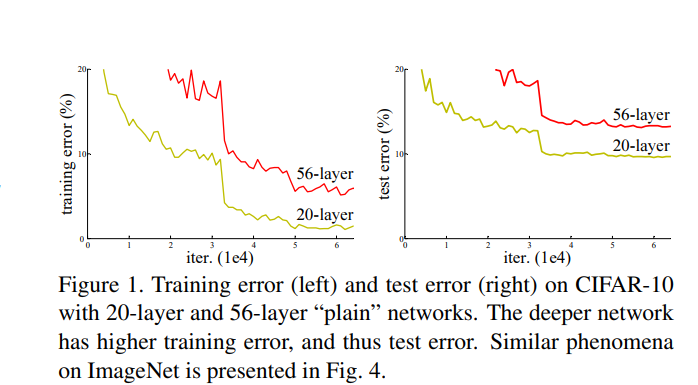
- 하지만 Deep learning 특성상 레이어가 높아 질수록 모델이 과학습이 되는 문제가 발생하여 추가적인 학습률 개선이 어려움이 있음
- 이를 해결 하기 위해 CNN 연산 후 초기 입력값을 추가로 입력으로 넣어 최소한의 기울기를 보장하는 Resnet이라는 모델을 도입하여 레이어층을 110층 까지 늘림
2. Residual block
2.1 Basic Residual block
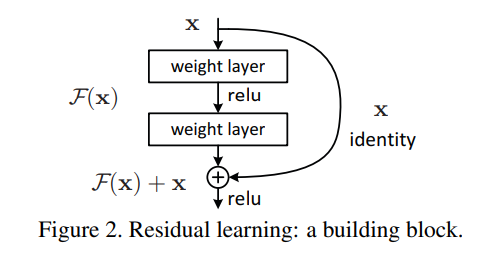
- 입력을 , weight layer에 대항하는 함수를 각각 Residual block 는 다음과 같이 표현이 가능함Residual 항 를 추가함으로 2가지 장점이 발생하게 되는데
- weight layer 함수 F(x)가 0에 근접하게 되어도 출력함수는 x로 근사하게 표현이 가능하여 최소한의 출력값을 유지할수 있도록 해줌
- 인 상황에서 비선형 함수인 를 학습하게 됨으로 학습난이도가 낮아 지게 됨, 즉 학습이 필요한 레이어를 제한함으로 Gradient vanishing이 되는것을 방지해준다.
2.2 Identity Mapping by Shortcut
- 만약 입력 와 출력 의 차원이 다르게 된다면 이에 대해서 맞춰줄 필요가 있음정방행렬 를 추가하여 의 차원과 의 행렬크기 및 채널수를 맞춰줄 수 있다. 이를 통해서 행렬 크기에 제한되지 않고 유연하게 학습을 할 수 있음
- 추가로 논문에서는 2,3개의 weight layer가 있어야 Residual block에서 이점이 있다고 주장
3.3 Network archtecture
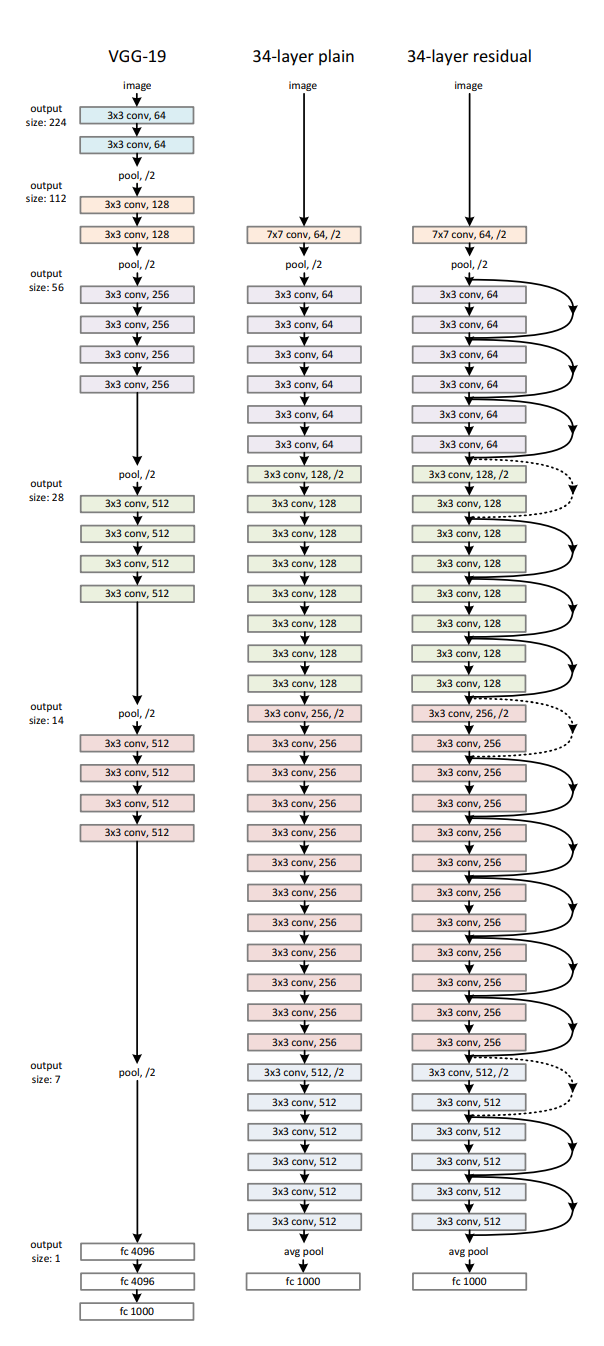
- Resnet 모델과 비교하기 위해 동일한 CNN구조로 VGG넷을 추가로 구현, 상세 레이어 구조는 아래 표에서 참고 하면 됨
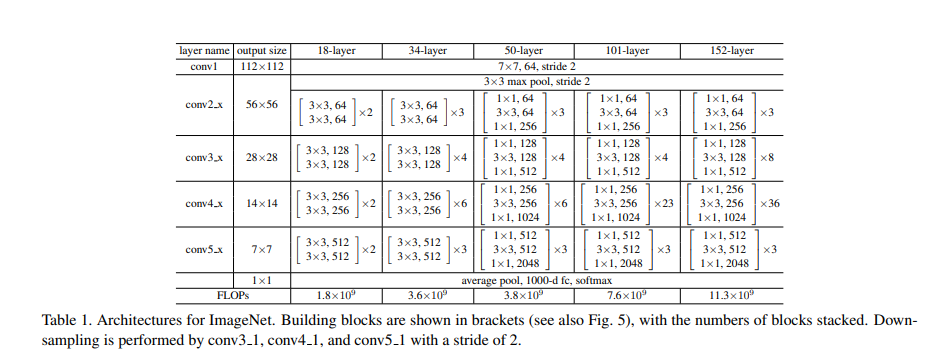
2.4 bottle neck
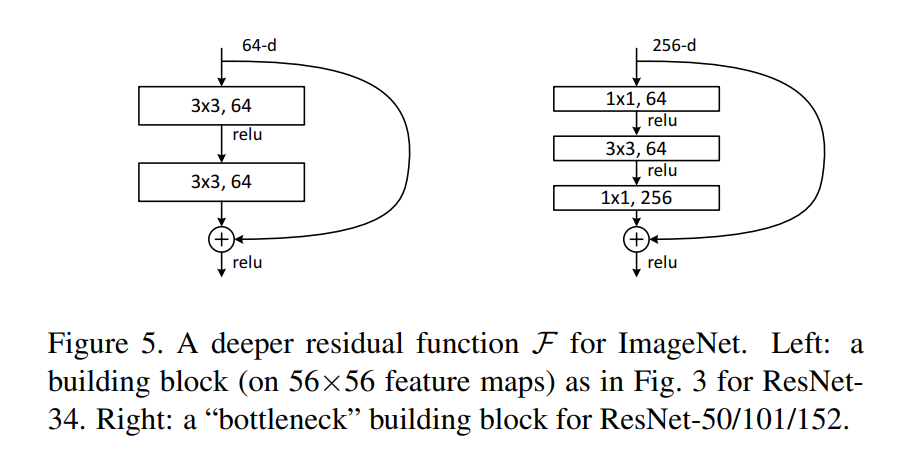
- Bottle neck 구조는 Deep resnet 구조를 구현하기 위해서 등장한 기법중 하나다. 채널이 많아질수록 커널사이즈에 비레해 연산량이 증가 되는 문제가 있다.
- 1*1 Kernel 을 사용한 CNN을 사용해 채널의 수를 줄여 3 kenel CNN에서 학습을 한뒤 원래 채널로 원복을 시켜주는 방법
- 논문을 작성할 당시의 컴퓨팅 성능을 고려하면 50-layer부터 적용이 된것을 확인가능
3. Experience
3.1 VGG net과 Resnet의 비교

- Resnet은 VGG넷에 비해 layer가 높아지는것에 비례하여 학습률이 개선된것을 확인이 가능함

- 하지만 110 Layer 까지는 레이어 수에 비례하여 학습률이 개선 되는것이 확인 되지만(중앙), 그이상으로 넘어가면 overfit이 되어 error(%)가 되려 높아지는것을 확인할 수 있다(우측).

imageprocessing and Data science