🤔 항상 알고리즘을 풀다보면 stream 을 이용한 경우가 있었다. stream을 이용하여
int[] 형의 배열에 Set<Integer> 로 중복되지 않도록 저장하였던 것 같다.
문제 : https://school.programmers.co.kr/learn/courses/30/lessons/68644
package Programmers_nbc;
import java.util.*;
public class Pr_49 {
static class Solution {
public static int[] solution(int[] numbers) {
Set<Integer> productSet = new HashSet<>();
for (int i = 0; i < numbers.length - 1; i++) {
for (int j = i + 1; j < numbers.length; j++) {
int product = numbers[i] + numbers[j];
productSet.add(product);
}
}
int[] answer = productSet.stream().mapToInt(Integer::intValue).toArray();
Arrays.sort(answer);
return answer;
}
}
public static void main(String[] args) {
int[] numbers = {2, 1, 3, 4, 1};
System.out.println(Arrays.toString(Solution.solution(numbers)));
}
}
input 값으로 주어진 정수배열에서 2개의 정수를 합하여 만들 수 있는 정수를 중복없이 배열에 저장해서 output(결과)로 주라는 문제였다.
중복없이라는 말이 나와 바로 Set 을 이용하였다.
처음에 Set 을 생각해서 그 값을 저장하는 것 까지는 어렵지 않게 구현할 수 있었다. 하지만 주어진 함수에서 원하는 return 의 형태는 int[] 형태였기에 여러가지 생각으 해보았다.
처음에는 toArray()를 사용하여 Set을 배열로 변경하려고 했지만 이 메서드는 반환형이 Object[] 형태이고 이를 아래와 같이 Integer[] 형태로 변경하여 사용할 수 있다.
Integer[] tmp = (Integer[]) productSet.toArray();
int[] answer = new int[tmp.length];
// Integer[]의 각 요소를 int로 변환하여 intArray에 저장
for (int i = 0; i < tmp.length; i++) {
answer[i] = tmp[i];
}=> 나는 처음에 이런식으로 해도 좋겠다는 생각을 했으나 뭔가 for 문을 사용하기엔 너무 복잡하고 일일히 하나씩 집어 넣는 것은 좋지 않다고 생각을 하던 찰나 다른 사람의 답을 보니 맨 처음 코드와 같이 stream 을 이용한 경우를 찾아 볼 수 있었다
하지만 stream을 통해 본 코드는 나에게는 거의 처음 보는 코드인 것 처럼 매우 낯선 것이었고 이를 계기로 stream 에 대해서 한번 찾아 보고 공부해야 겠다는 생각을 했다.
- Java Stream
- 일단 java stream 이라는 것에 대해 알아보기 전에 이것을 사용하는 이유를 찾아 보았다. 위처럼 for 문을 사용하여 해결 할 수도 있는데 구지 stream 을 사용하는 이유가 있을 것 같았다.
이유 :
1) 가독성 향상
프로그램을 코딩 시 어떻게 할지를 하나하나 기술하는
명령형이 아니라 무엇을 하고싶다는선언형으로 코딩이 가능하다는 장점이 있다. 또한 연속적으로 필터링, 매핑, 정렬을 할 수 있다는 장점이 있다. (체이닝)
예시 : 사람의 이름으로 구성된 ArrayList 데이터에서 'A'로 시작하고 글자수가 4개 이상인 이름을 찾아서 ArrayList로 넣고 출력하는 경우
- 단순한 반복문으로 처리하는 방식
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");
// 4개의 이름이 들어간 List 생성
List<String> filteredAndSortedNames = new ArrayList<>();
for(String name : names) {
if(name.startsWith("A") && name.length() >= 4){
filteredAndSortedNames.add(name);
// name 값 추가
}
}
}
Collections.sort(filteredAndSortedNames); // 리스트 정렬
for(String name : filteredAndSortedNames){
System.out.println(name);
}
- stream 을 이용하는 방식
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");
// 4개의 이름이 들어간 List 생성
names.stream()
.filter(name -> name.startsWith("A") && name.length() >=4)
.sorted()
.forEach(System.out::println);=> 확실히 steam 쪽이 람다 함수를 이용하여 코드도 간결하고 직관적으로 볼 수 있다. (물론 어떤 식으로 동작하는지 안다는 가정 하에)
2) 유지보수성 향상
간결하고 명확한 코드로 데이터를 처리할 수 있어 가독성 및 유지 보수성이 향상된다.
3) 병렬처리 지원
Stream 은 병럴처리를 지원하여 데이터의 흐름을 나누어서 멀티 스레드로 병렬로 처리하고 처리 후에 합치는 과정을 통해 대량의 데이터를 빠르고 쉽게 처리 할 수 있다는 장점이 있다.
대략적인 stream의 과정 (생성 -> 가공 -> 소비)
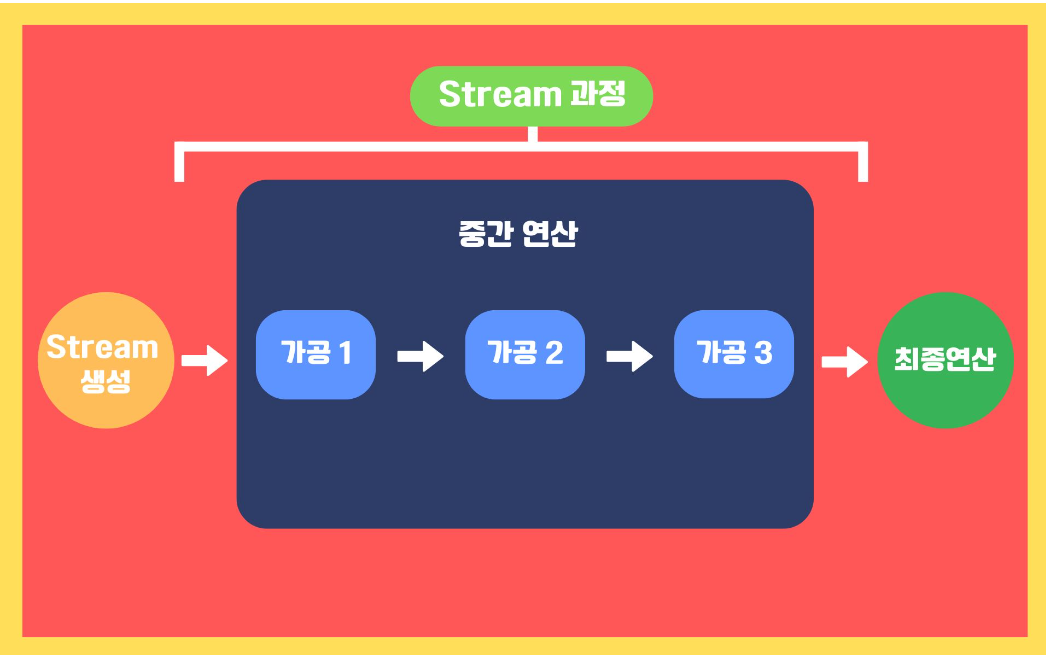
1. Stream 생성
데이터의 컬렉션(집합)을 Stream 으로 변환하는 과정으로 stream을 만들어 내는 것을 의미, Stream API를 사용하기 위해 최소 1번 수행되어야 한다. 생성 단계에서는 특징은 모든 데이터가 한번에 메모리에 로드되지 않고 필요 시에만 로드된다.
예시 코드 :
1) 컬렉션 스트림
List<String>list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
// 리스트 생성
Stream<String> stream = list.stream();
// ArrayList로 부터 Stream 생성
2) 배열 스트림
String[] array={"Apple", "Banana", "Orange"};
// 배열 생성
Stream<String>stream = Arrays.stream(array);
Stream<String>stream2 = Stream.of(array);
// 배열로 부터 Stream 생성하는 위 두가지 방법3) generate(), iterate()로 생성하기
Stream<String> stream = Stream.generate(()->"Hello").limit(5);
// "Hello" 문자열을 반복적으로 생성하는 Stream 생성 후, 처음 5개만 가져오도록 제한
Stream<Integer> stream2 = Stream.iterate(1,n->n*2).limit(5);
// 초기 값이 1이고, 다음 요소는 이전 요소에 2를 곱한 Stream 생성 후, 5개만 가져옴
4) java.util.stream 패키지에서 제공하는 클래스 이용하기
IntStream stream = IntStream.rangeClosed(1,100);
// 1부터 100까지 연속된 값의 Stream을 만드는 예시
Stream<Integer> stream2 = Stream.iterate(1, n->n+1).limit(100);
//위 두 코드는 동일5) 1~100 범위의 10개 난수 만들기
Random random = new Random();
Stream<Integer>randomStream = Stream.generate(()->random.nextInt(100) + 1).limit(10);
// 1~100 까지
IntStream randomStream2 = random.ints(1,101).limit(10);
// 101은 포함되지 않는다.
2. 가공
가공은 소스의 데이터 집합을 원하는 형태로 가공하는 것으로 중간 처리를 의미. 필터(filter), 변형(map), 정렬(sort) 등의 가공을 말한다. 입력값은 Stream, 결과물도 Stream이다. (중간연산을 계속해서 할 수 있는 이유)
예시 코드 :
1) 필터 (filter)
IntStream.rangeClosed(1,100).fliter(n->n%2==0);
// 1부터 100까지의 숫자 중에서 짝수만 걸러내는 연산2) 변환 (map)
IntStream.rangeClosed(1,100).map(n->n*n);
// 1부터 100까지의 숫자를 제곱하여 변환하는 연산3) 정렬 (sort)
IntStream.rangeClosed(1,100).sorted();
// 1부터 100까지의 숫자를 정렬4) peak (중간 연산 중간에 처리 내용 살펴보는 용도)
IntStream.rangeClosed(1,100).map(n->n%100).peak(n->System.out.println(n);
// 1부어 100까지의 숫자 중에서 10으로 나눈 나머지 값을 출력5) 중복제거 (distinct)
IntStream.rangeClosed(1,100).map(n->n%10).distinct();
// 1부터 100까지의 숫자를 10으로 나눈 나머지값 중에서 중복을 제거6) limit (개수 제한)
IntStream.rangeClosed(1,100).limit(10);
// 1부터 100까지의 숫자 중에서 처음 10개의 숫자만 사용=> 이러한 중간 연산을 거치면 새로운 데이터의 stream 이 만들어 진다.
3. 소비 (최종 연산)
Stream에 대한 최종 연산을 수행한다. 최종적인 목적물을 얻는 처리과정으로서 데이터의 컬렉션(집합)이나 하나의 값(예, 합계)으로 결과값이 반환된 결과물을 얻을 수 있고 1번만 수행 할 수 있다. 이후 Stream은 닫혀서 더이상의 연산 처리 불가능하다. (이럴땐 새로운 Stream 을 생성해서 작업해야한다.)
예시 :
1) 요소 출력 : forEach() : stream 의 각 요소를 순회하면서 출력 등의 처리를 위해 사용.
2) 요소의 소모 : reduce() : stream의 요소를 줄여나가면서 연산 수행. 처음 두 요소를 가지고 연산한 결과를 가지고 다음 요소와 연산해서 최종적인 값을 구하기 위해 사용
3) 요소의 검색 : findFirst(), findAny() : 특정 조건에 맞는 요소를 찾기위해 사용. 각각 시퀀셜처리와 병렬처리에 사용된다.
4) 요소의 검사 : anyMatch(), allMatch(), noneMatch() : 조건에 맞는지 확인을 위해 사용됨
5) 요소의 통계 : count(), min(), max() : 요소의 개수, 최소, 최대를 구하기 위해 사용
6) 요소의 연산 : sum(), average() : 합계, 평균을 구하기 위해 사용
7) 요소의 수집 : collect() : stream의 요소를 수집하여 원하는 형태로 변환하기 위해서 사용, Java Collector 인터페이스를 매개변수로 호출하며, Java에서 제공하는 Collectors 클래스에서 이미 만들어둔 method를 이용해서 요소를 변환해서 사용

소비 예시 코드
1) forEach 각각의 요소에 특정 작업을 수행
IntStream.rangeClosed(1,100).forEach(System.out::println);
// 1~100 까지 숫자를 각각 프린트2)
long count = IntStream.rangeClosed(1,100).count();
int sum = IntStream.rangeClosed(1,100).sum();
OptionalInt min = IntStream.rangeClosed(1,100).min();
OptionalInt max = IntStream.rangeClosed(1,100).max();
OptionalDouble average = IntStream.rangeClosed(1,100).average();
// 1~100 까지의 개수, 합계, 최소, 최대, 평균 예시
// Optional 은 해당 값이 있을 수도 있고 없을 수도 있는 경우 사용한다.3) reduce stream 의 각 요소를 결합하여 하나의 결괏값 생성
OptionalInt result = IntStream.rangeClosed(1,100).reduce((x,y) -> x+y);
// 1~100 까지의 숫자를 합하는 예시 (2) 예시의 .sum() 과 같다.4) collection stream을 컬렉션으로 변환
List<Integer> collectedList = IntStream.rangeClosed(1,100).boxed().collect(Collectors.toList());
//1~100의 Stream을 컬렉션으로 변환
// boxed() : int -> Integer 로 박싱
//.collect() : stream의 요소를 모아서 원하는 형태의 결과로 변환=> 위 예시들과 같이 최종 연산이 종료되면 Stream 소비가 완려되어 더이상 Stream 처리가 불가능하다.

(스트림 소비 완료 관련 에러 예시)
-Stream 의 특징
지연 평가 (Lazy Evaluation)
중간 연산은 stream을 다른 stream으로 변환하거나 요소들을 변환하거나 필터링하는 작업을 수행합니다. 이러한 중간 연산들은 연산을 호출할 때 즉시 수행되지 않고, 최종 연산이 호출될 때까지 지연한다. 이를 ‘Lazy Evaluation(지연 평가)’이라고 한다.
데이터의 연속 흐름에 대해 중간 연산은 실행되고 있지 않다가 최종 연산을 만나게 되면, 그때 중간 연산이 실제로 실행된다.
-> Stream의 데이터가 처리되는 순서
데이터 처리는 모든 데이터에 대해 하나의 함수가 끝나고(모두 처리되고 나서) 다른 함수가 수행되는 것이 아니라, 일련의 데이터가 나타난 흐름의 순서대로 처리됩니다. 앞선 데이터가 먼저 처리되고 뒤의 데이터가 나중에 처리되는 구조 (하나의 이어진 통로)
참고 사이트 : https://www.elancer.co.kr/blog/view?seq=255
그럼 맨처음의 문제의 정답 부분 중 Stream 을 이해 할 수 있다!!!
package Programmers_nbc;
import java.util.*;
public class Pr_49 {
static class Solution {
public static int[] solution(int[] numbers) {
Set<Integer> productSet = new HashSet<>();
for (int i = 0; i < numbers.length - 1; i++) {
for (int j = i + 1; j < numbers.length; j++) {
int product = numbers[i] + numbers[j];
productSet.add(product);
}
}
int[] answer = productSet.stream().mapToInt(Integer::intValue).toArray();
Arrays.sort(answer);
return answer;
}
}
public static void main(String[] args) {
int[] numbers = {2, 1, 3, 4, 1};
System.out.println(Arrays.toString(Solution.solution(numbers)));
}
}- 유심히 봐야 할 부분
int[] answer = productSet.stream()
.mapToInt(Integer::intValue)
.toArray();
=> .stream() 을 통해 stream을 생성한다.
(이 과정 이후에는 Stream<Integer> 상태)
=> .mapToInt(Integer::intValue) :
1) mapToInt를 통해 IntStream으로 변환
2) 스트림(IntStream)의 각 Integer 요소를 기본형 int로 변환한다. ->(Integer 클래스의 intValue를 통하여 변환)
=> .toArray() : 최종 연산으로 IntStream의 모든 요소를 int[] 배열로 수집한다. 스트림을 소비하기 때문에 stream 중단됨
=> 확실히 익숙하지 않은 형태의 코드이지만 빅데이터 시대에 이러한 데이터 처리를 원활하게 하기 위한 방법은 선택이 아닌 필수이므로 알아 둘 필요가 있다.
