[Web Application Hacking] Ch 4. Mapping the Application
Up to Chapter 3, the content has mainly been theoretical explanations about the technology, and I didn't feel the need to summarize much.
And as of Chapter 4, Practical content included by it, so I intend to begin summarizing the content.
Chapter 4. Mapping the Application
The first step in the process of attacking an application is gathering and examining some key information about it to gain a better understanding of what you are up against.
Web Spidering
Web Spidering is a technique used to grasp all resources and the structure of the target web application. This technique becomes achievable by recursively fetching all contents linked from the main page.
robots.txt
The robots.txt file, situated at the web root, comprises a roster of URLs that the website wishes to evade web spiders and search engines from visiting or indexing.
It is important because it occasionally contains critical URL information.
Automated Spidering
Automated Spidering refers to the process in which a spider tool spiders the target webserver entirely without human intervention.
Because this technique utilizes the resources exposed externally to find out the structure of web server, there is an issue where the spider cannot verify certain resources when user interaction is required or when links to access the resource are hidden.
User-Directed Spidering
It refers to the process in which the user navigates through the application in a typical manner using a standard web browser, and the spider tool captures this interaction to build a sitemap of the application.
Because the interaction with the web application is carried out by the user, no issues arise when the Automated Spidering technique is employed.
User-Directed Spidering Processing
-
Configure the browser to use either Burp or WebScrab as a local proxy.
-
Browse the entire application normally, attempting to visit every link/URL you discover.
-
Review the site map generated by the proxy/spider tool
Intruder of Burp
Burp Suite's Intruder can be utilized for performing Automated Spidering.
Let's look at an example of usage. When you define parameters within the request, Intruder sends the request to the destination server with randomized values for those parameters:
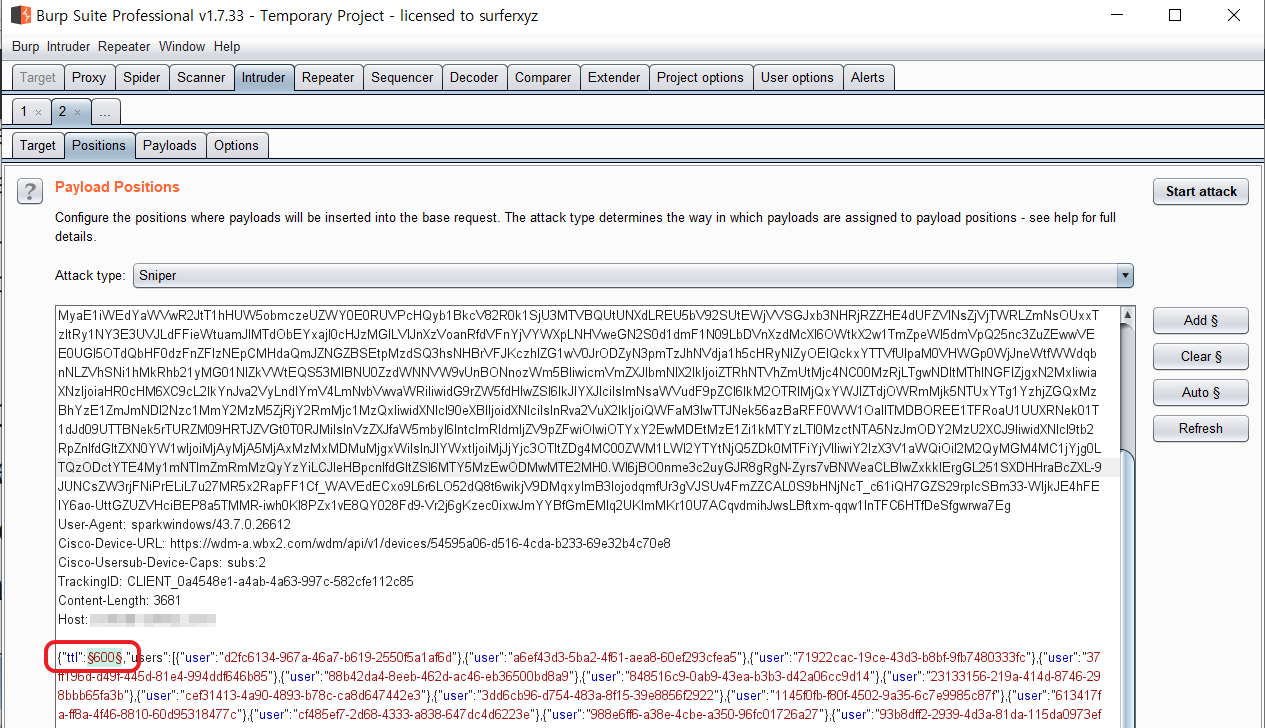
It then collects the responses:
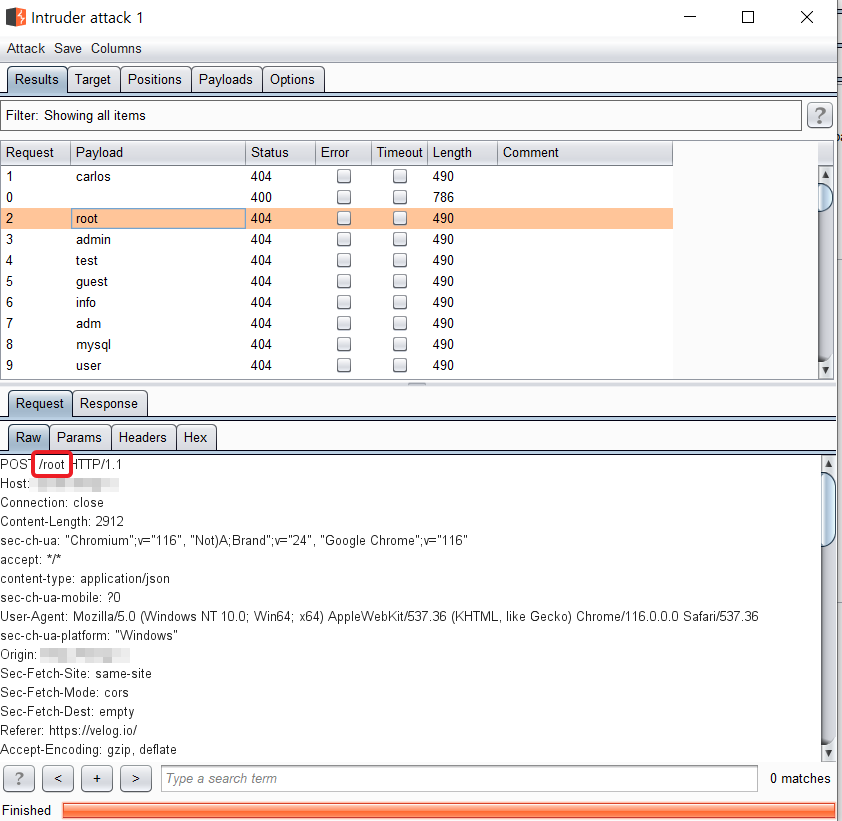
HACK TIPS
-
Identify any naming schemes in use. For example, if there are pages called
AddDocument.jspandViewDocument.jsp, there may also be pages calledEditDocument.jspandRemoveDocument.jsp -
If there are identifiers distinguishing resources, modify them to find undiscovered resources.
(likeAnnualReport2009.pdfandAnnualReport2010.pdf) -
Review all client-side code to identify any clues about hidden server-side content such as HTML and JavaScript.
-
Search for temporary files such as the
.DS_Storefile, which contains a directory index under OS X,file.php~1, which is a temporary file created whenfile.phpis edited, and the.tmpfile.
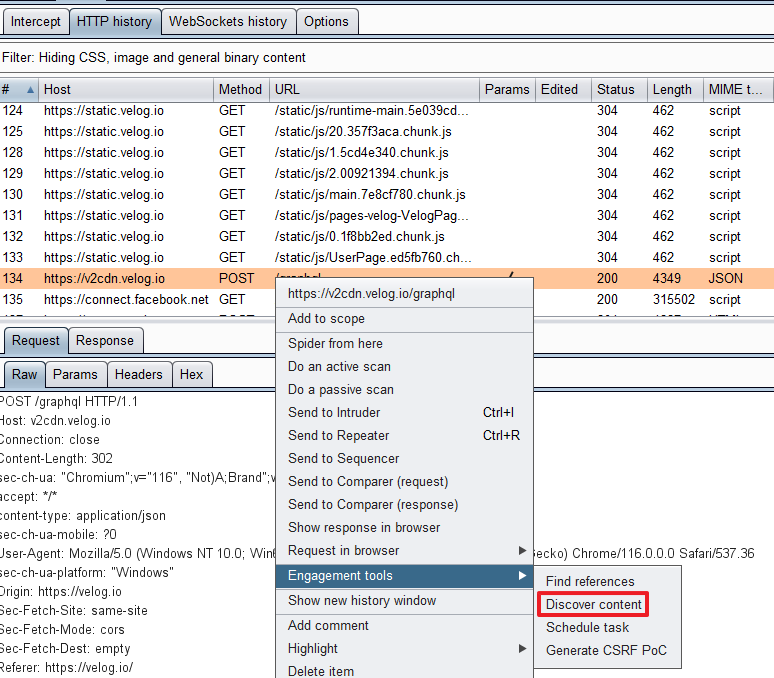
Content Discovery of Burp
The Content Discovery feature of Burp Suite automates these processes.
Let's follow the menu:
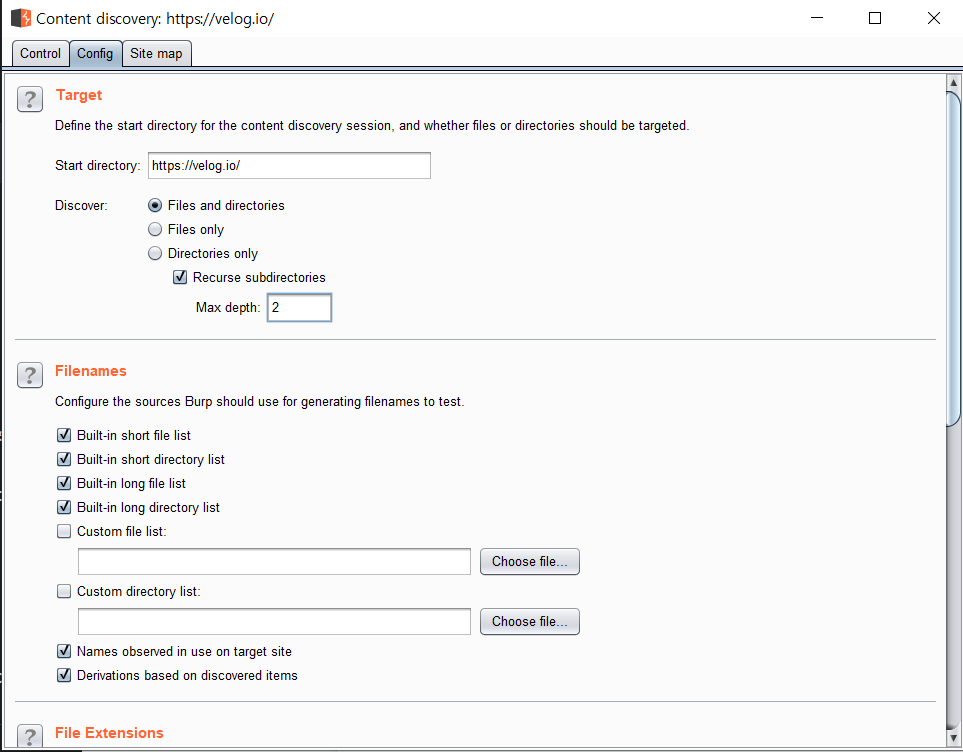
Subdirectory exploration, file names, and extensions can be easily configured.
Google Dorks
Google Dorks also provide a wide range of information necessary for web server attacks:
-
Searching for specific file extensions
filetype:pdf site:example.com
This query searches for PDF files uploaded toexample.com -
Searching for
access.log
intitle:"index of" intext:"access.log" site:example.com
This Dork would enable you to search for access log files ofexample.com -
Finding developer-written source code
intitle:"index of" intext:"server at" site:example.com -
Discovering links to a specific website
link:www.wahh-target.com
This Dork would return all the pages on other websites that contain a link to the target.
Above will help you discover the web application's server-side source code and the version of the framework in use

개발자로서 성장하는 데 큰 도움이 된 글이었습니다. 감사합니다.