
개요
이전의 무한 스크롤 방식에서 데이터 조회 시, 중복 현상 이슈를 해결하기 커서 기반 페이지네이션을 도입하였습니다.
이러한 커서 기반 페이지네이션을 적용하여 데이터 중복 이슈 뿐 아니라, 기존의 오프셋 기반 페이지네이션의 한계점인 오프셋이 값이 커질 경우에도 빠른 성능을 보여주었습니다.
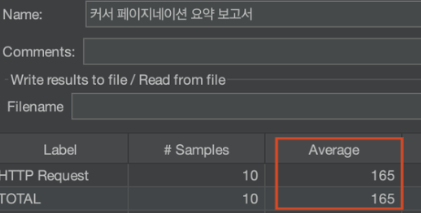
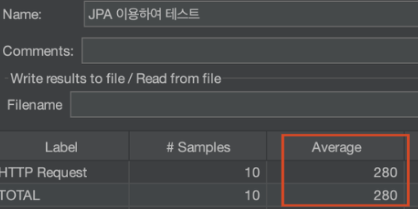
하지만 숙소 검색 기능을 이용하게 되면 성능이 낮아지는 것을 확인했습니다. (20만건 기준)
그리고 우리 서비스(숙소 예약 서비스)를 생각해보았을 때 사용자가 검색 기능을 사용할 빈도 수는 높다고 생각이 들었습니다.
따라서, 숙소 검색 쿼리에 대하여 성능 개선한 내용을 정리해보려고합니다.
문제 원인 - LIKE 연산
이전까지 DB에서 문자열을 찾는 쿼리를 작성할 때는 항상 LIKE 연산을 사용했습니다.
그리고 사용자 입장에서 생각해보았을 때, 검색 기능은 전문 검색이 필수라는 생각을 했습니다.
SELECT * FROM hotel WHERE name LIKE name '%[키워드]%';그렇기 때문에 검색 필드(name)에 인덱스를 추가하여 성능 테스트를 진행했습니다.
하지만 문제를 발견했습니다.
%키워드% 검색

name 필드에 인덱스를 추가해서 실행계획을 실행해보면, index가 적용되지 않는다.. 그리고 rows를 확인해보면 전체 데이터 개수(218192)가 나오게 된다.
인덱스를 타지 않는 이유
이러한 문제가 발생하는 이유는 데이터베이스의 인덱스 자료구조는 대부분 B-TREE 구조이다.
B-TREE는 노드의 자식 노드의 데이터들은 노드 데이터 기준으로 데이터보다 작은 값이 왼쪽부터 오른쪽으로 정렬되어 있다.
다시 말해, B-TREE는 기본적으로 데이터를 1,2,3 또는 ㄱ,ㄴ,ㄷ과 같은 오름차순 형태로 들고 있기 때문에 특정 문자열로 시작하는 데이터의 값을 알아야 찾을 수 있다.
즉, 첫 글자를 모르기 때문에 인덱스 순서대로 Full Table Scan을 하게 되는 것이다.
와일드 카드(%)를 앞에만 제거해주면 정상적으로 index가 적용되는 것을 확인할 수 있다.

LIKE 연산 정리
LIKE키워는 와일드 카드(%)와 함께 사용%를 사용할 때 항상 인덱스를 사용하지 않는다.- DB 인덱스 자료구조는 B-TREE이다.
키워드-> 적용 가능키워드%-> 적용 가능%키워드%-> 적용 불가%키워드-> 적용 불가
- 따라서, 대량의 데이터를 검색할 경우 성능 저하가 발생한다.
개선 방법 - Full Text Search
Full Text Search는 단어나 구문에 대한 검색을 지원하고자 제공되는 방식이며, Full Text Search를 활용하기 위해서는 검색 필드에 Full Text Index 를 설정해주어야한다.
그리고 문자열이 정해진 방법으로 분리되어 인덱스를 생성하고, 빠르게 검색을 가능하게한다.
Built in parser
Built in parser는 공백을기준으로 키워드를 추출하는 방식입니다.
오늘 저녁은 제육볶음입니다 -> 오늘 / 저녁은 / 제육볶음입니다위와 같은 방식으로 토크나이징 되어있다면 "저녁" 혹은 "제육볶음"의 키워드로 검색할 수 없습니다.
왜냐하면 Full Text Search는 토큰과 검색 키워드가 전부 일치하거나 prefix가 일치한 경우에만 결과를 가져오기 때문입니다.
N-gram parser
이러한 문제를 해결해주는 parser가 N-gram parser입니다.
N-gram parser는 지정된 토큰 사이즈를 기준으로 키워드를 추출합니다.
오늘 저녁은 제육볶음입니다 -> 오늘 / 늘저 / 저녁 / 녁은 / 은제 / 제육 / 육볶 / 볶음 / 음입 / 입니 / 니다위와 같은 방식으로 토큰나이징 되기 때문에 "저녁", "제육", "볶음" 으로 검색이 가능합니다.
정리하면
Built in parser는 기본적으로 공백을 기준으로 단어를 구분해서 파싱하고,N-gram parser는 하나의 문장을 최소 토큰 수 만큼 모두 나누어서 파싱합니다.
Full Text Index 생성
ALTER TABLE hotel ADD FULLTEXT INDEX idx_hotel_name(name) WITH PARSER NGRAM;N-gram parser를 사용하여 인덱스를 생성ngram_token_size는 2로 설정- 한국어 검색에 적합하다고 판단
- 인덱스를 작게할 수 있어 검색속도 향상
- 검색할 수 있는 토큰 크기가 제한된다
하지만, JPA에서는 아직 Full Text Search에 대해서 지원하지 않는다.
따라서, JDBC Template을 이용하여 Full Text Search 조회와 성능 테스트를 진행해보려고한다.
JDBC Template 코드
String sql = "select * from (SELECT * FROM hotel WHERE MATCH (name) AGAINST (? IN BOOLEAN MODE)) as sub\n"
+ "where (created_at='2024-06-05T00:38:05.008' and id<382 )or (created_at<'2024-06-05T00:38:05.008') order by created_at desc limit 10";
List<Hotel> findHotels = jdbcTemplate.query(sql,
(rs, rowNum) -> {
Hotel hotel = Hotel.builder()
.name(String.valueOf(rs.getLong("name")))
.build();
return hotel;
}, request.getKeyword());테스트 시나리오 및 조건
Number of Threads : 1
Ramp-up period : 1
Loop Count : 10
데이터 개수 : 20만건
JPA
JDBC Template
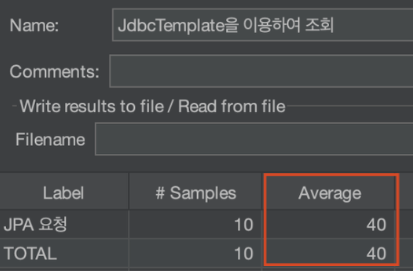
정리
이처럼 Full Text Search 기능을 이용해서 LIKE 연산에 대한 성능 저하 이슈를 해결해보았습니다.
하지만 Full Test Search 기능을 이용하기 위해서는 JDBC Template을 사용해야합니다. 하지만 JdbcTemplate을 사용하게 되면 트랜잭션 관리, 비표준화 API, 생산성, 유지보수 등이 문제가 될 수있습니다.
따라서, 성능이 개선된 것을 확인했지만 팀원들과 회의 한 결과 전문 검색 엔진인 Elasticsearch를 도입하기로 결정했습니다.
Elasticsearch는 부분검색, 유사검색, 다중 필드 검색 등 고급 검색 기능을 제공해줍니다.
또한 분산 DB에 걸쳐서 검색 쿼리를 구현하기 위해서도 추후 Elasticsearch 도입을 고려하고 있었기 때문입니다.
따라서 마이크로 서비스 아키텍처에 따라서 수평확장에 용이한 Elasticsearch를 도입하기로 결정하였습니다.
