Definition
EM은 Expectation-Maximization 의 준말이다
Motivation
Example
우리가 알고 있는 단순선형 회귀모델을 생각하자.
Yi=Xiβ+ϵi , i=1,2,....n
우리가 일반적으로 가정하는 상황은, X1,....Xn 그리고 y1....yn 을 알고있는 상황이다.
이 경우에서, (Xi,yi),i=1,2,3...n 은 Complete data라고 할 수 있다
만약, 우리가 y1....yn 을 여전히 알고 있지만,
X1...Xm 까지만 알고 Xm+1....Xn (m<n)을 모르는 상황에 있을 때, 어떻게 회귀계수 β 를 추정하는 것이 좋을까?
이 때는, (X1,...Xm,y1...yn) 은 observed data라고 생각 할 수 있고, Xm+1...Xn 은 missing data라고 생각 할 수 있다.
물론, i=m+1...n 까지의 데이터를 날리고 추정하는 것도 하나의 방법이지만, EM 알고리즘은 이런 경우에 활용 가능한 최적화 알고리즘을 제공한다.
이와 같은 단순한 문제 뿐만 아니라, missing data problem으로 변환할 수 있는 대부분의 추정문제(보통 latent variable을 도입하는 형태로 많이 이루어진다)에서, EM 알고리즘은 활용될 수 있다.
Algorithm
알고리즘을 설명하기에 앞서, 다음과 같은 용어를 정의한다
- Yc : Complete Data
- Yo : Observed Data
EM 알고리즘은 다음의 단계로 구성된다.
E-Step
Q(θ∣θ0)=Eθlogf(Yc∣Yo,θ0) 을 구한다.
What is Q ?
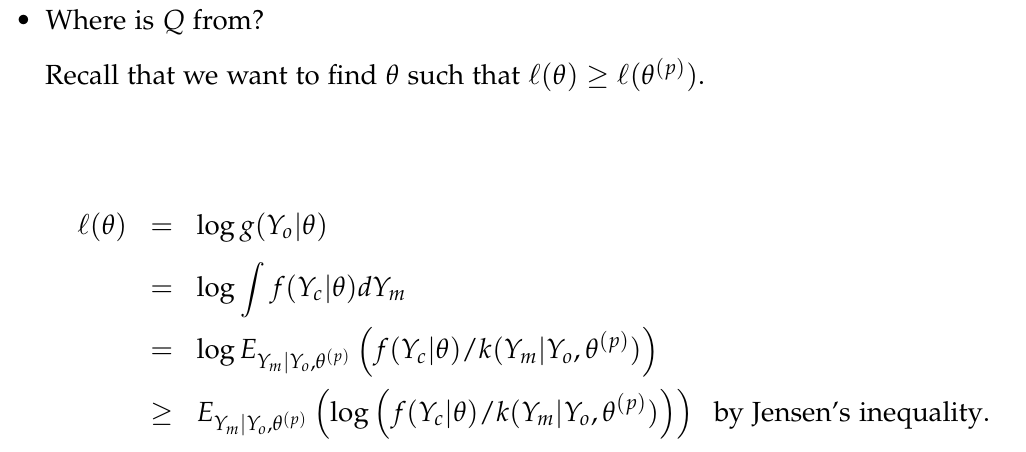
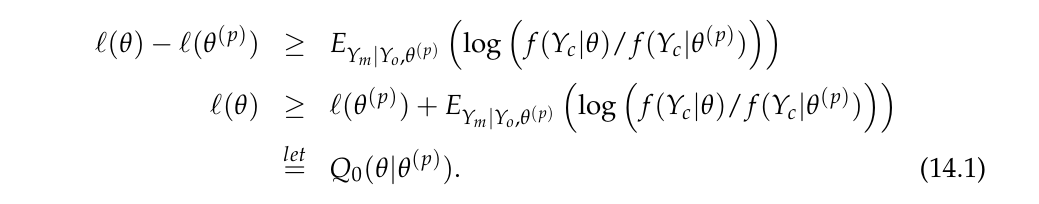
즉, l(θ)의 lower bound를 최대화시키는 작업을 반복하면, argmaxθl(θ)의 근사치를 찾을 수 있을 것이라는 발상이다.
M-Step
E-step에서 구한 Q를 maximize 시키는 새로운 θ 를 구하고, 이를 새로운 θ0로 업데이트 시킨다.
Iteration
θ 가 만족스러운 값에 수렴 할때까지 이를 반복한다.
비교적 간단하지 싶으면서도, 왜 이런 알고리즘이 만들어졌는지에 대한 부연설명을 간단히 해보겠다.(본인의 주관적인 의견도 포함되었으니 비판적으로 수용바람)
일단은, 우리가 좋은 모수를 추정하기 위해 하려고 하는 것은, Observed Data Yo 하에서 Likelihood를 최대화시키는 θ를 찾는 것이다. (argmaxθlogf(Yo∣θ))
Complete Data Yc의 경우엔, 우리가 비교적 쉽게 log-likelihood를 구할 수 있는 상황이 많다. (motivation part에서의 예시만 봐도 그러하다) 또한, 구하기 쉽지 않다면, latent variable를 도입하여 표현이 용이하게끔 할 수 있다.
그러나, Observed Data Yo의 경우 logf(Yo∣θ) 를 구하기 힘든 상황이 많다. 당장 motivation의 상황만 보더라도, 저 상황에서의 log-likelihood를 어떻게 표현 할 것인가?
따라서, 비교적 구하기 쉬운 complete data에 관한 log-likelihood를 이용하여 logf(Yo∣θ) 를 최적화시키는 알고리즘을 고안한 것이 EM알고리즘이라고 생각하면 될 것이다. 이 알고리즘이 어떻게 이를 가능케 하는지는 이어서 설명하도록 하겠다.
Why it works
EM Algorithm은 두 가지 유용한 성질이 있다.
-
EM 알고리즘에 의해 Update 되는 θ는 logf(θ∣Yo) 를 단조증가 시킨다. (monotonicity)
-
logf(θ∣Yo) 는 l이 bounded from above라는 조건 하에서 특정값 l∗로 수렴한다. 이 때, l이 unimodal이면 l∗가 global maximum 이 되지만, 일반적으로는 local maximum이다.
(참고 : unimodality)
https://en.wikipedia.org/wiki/Unimodality
본 포스트에서는 1번의 증명만을 다루도록 하겠다.
Q(θ∣θ(p)=∫logf(Yc∣θ)k(Ym∣Yo,θ(p))dYm
=EYm∣Yo,θ(p)(logf(Yc∣θ))
=l(θ)+H(θ∣θ(p))
whereH(θ∣θ(p))=∫logk(Ym∣Yo,θ)k(Ym∣Yo,θ(p))dYm
Q(θ(p+1)∣θ(p))=l(θ(p+1))+H(θ(p+1)∣θ(p))
Q(θ(p)∣θ(p))=l(θ(p))+H(θ(p)∣θ(p))
Q(θ(p+1)∣θ(p))−Q(θ(p)∣θ(p))={ℓ(θ(p+1))−ℓ(θ(p))}+{H(θ(p+1)∣θ(p))−H(θ(p))}
Q(θ(p+1)∣θ(p))≥Q(θ(p)∣θ(p)) by the definition of EM
H(θ(p+1)∣θ(p))≤H(θ(p)∣θ(p)) by the following using Jensen’s inequality
∫logk(Ym∣Y0,θ(p+1))k(Ym∣Y0,θ(p))dYm−∫logk(Ym∣Y0,θ(p))k(Ym∣Y0,θ(p))dYm=∫log(k(Ym∣Y0,θ(p))k(Ym∣Y0,θ(p+1)))×k(Ym∣Y0,θ(p))dYm≤log∫k(Ym∣Y0,θ(p+1))dYm=0
Therefore ℓ(θ(p+1))≥ℓ(θ(p)).
Application
(작성중)
Reference
