Chapter7의 주요 내용
- 병렬 스트림으로 데이터를 병렬 처리하기
- 병렬 스트림의 성능 분석
- 포크/조인 프레임워크
- Spliterator로 스트림 데이터 쪼개기
병렬 스트림을 사용한다는 것은 어떤 의미인가?
컬렉션에 parallelStream을 호출하면 병렬 스트림(parallelstream)이 생성된다. 병렬 스트림이 란 각각의 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림이다. 따라서 병렬 스트림을 이용하면 모든 멀티코어 프로세서가 각각의 청크를 처리하도록 할당할 수 있다.
순차 스트림을 병렬 스트림으로 변환하는 방법
순차 스트림을 병렬 스트림으로 변환하거나 그 반대로 변환이 가능하다. 순차 스트림과 병렬 스트림의 가장 큰 차이는 스트림이 여러 청크로 분할되어 있다는 것이다. 병렬 스트림은 리듀싱 연산을 여러 청크로 나눠서 수행한다. 병렬 스트림을 실행할 때 스트림 자체는 아무 변화도 일어나지 않는다. 내부적으로는 스트림마다 불리언 플래그가 설정되고, 병렬로 수행된다.
병렬 스트림의 스레드 풀은 어떻게 설정되는가?
병렬 스트림은 병렬 작업을 커스터마이즈하거나 동작 수행을 위해 내부적으로 ForkJoinPool을 사용한다. ForkJoinPool은 기본적으로 프로세서 수에 상응하는 스레드를 갖는다. Runtime.getRuntime().availableProcessors()를 통해 반환되는 프로세서 수를 반영하기 때문이다. 물론, 아래와 같이 전역적으로 설정할 수 있다. 전역 설정을 하면 모든 병렬 스트림에 영향을 미친다. 현재까지는 개별 병렬 스트림에 사용할 수 있는 특정한 값을 설정할 수 없다.
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");병렬 스트림의 성능은 언제 효율적이고, 언제 효율적이지 못한가?
병렬 스트림의 효율에 관한 몇 가지 기준이 있다. 하지만 기준을 이야기하기 전에 언제나 직접 측정해보는 것을 권장한다. 측정은 가장 정확하고 확실한 비교 방법이다. 테스트를 진행해보고 측정 값이 부정확하거나 효율적이지 못하면 병렬 스트림을 사용하지 않는 것이 낫다.
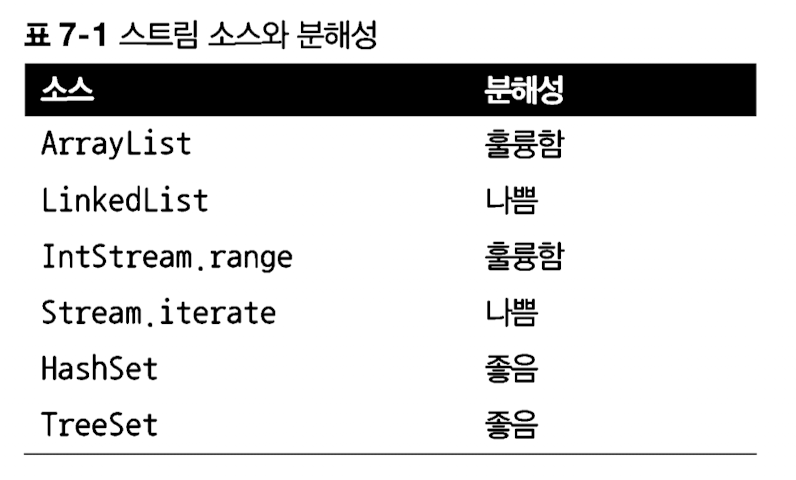
병렬 스트림은 특화된 자료구조나 자료의 크기가 일정 기준 이상일 때 효율적이라고 할 수 있다. 병렬 스트림의 동작 방식을 생각해보면, 당연히 개별 스레드의 연산 처리 속도가 병렬 스레드를 생성하고 작업을 분배하는 시간보다 길어야한다. 당연한 말이지만, 병렬 스트림을 사용하는데 추가로 투입되는 비용이 순차 스트림으로 인한 낭비분보다 적을 때 효율적이다. 이는 자료구조와 스트림의 특성에 기반한다. 스트림의 중간 연산이 sized와 같이 정확히 같은 크기의 분할이 가능하다면 병렬 스트림이 더 효율적일 것이다. 또한 LinkedList처럼 전체 요소를 탐색해야 하는 자료구조보다는 ArrayList처럼 요소 탐색 없이도 리스트릴 분할할 수 있는 자료구조가 낫다.
효율을 떠나서 자료구조가 순차 실행을 기반하고 있다면 병렬 스트림의 사용은 문제를 일으킬 수 있다. 여러 스레드가 가변 공유 객체에 접근하기 때문이다. 다수의 스레드에서 동시에 데이터에 접근하면 데이터 레이스 문제가 발생한다. 부정확하거나 일관되지 못한 결과로 인해 병렬 스트림을 사용하는 의미가 사라진다.
그 외에도 몇 가지 병렬 스트림의 사용 효율을 늘리는 방법도 있다. 당연히 소량의 데이터보다는 대량의 데이터를 처리할 때 유리하다. 그리고 박싱에 드는 비용을 줄이기 위해 가능한 기본형 특화 스트림(IntStream, LongStream, DoubleStream)을 사용하면 좋다.
병렬 스트림은 포크/조인 프레임을 어떻게 활용하는가?
병렬화의 개념을 쉽게 설명하자면, 일을 쪼개고 동시에 실행한다는 의미다. 포크/조인 프레임워크는 말 그대로 일을 쪼개고 결과를 합치기 위한 프레임워크다. 하나의 작업을 재귀적으로 작은 작업으로 분할하고, 그 결과를 다시 합쳐서 전체 결과를 만들도록 설계되어 있다. 포크/조인 프레임워크에서는 쪼개진 서브태스크를 스레드 풀 (ForkJoinPool)의 작업자 스레드에 분산 할당하는 ExecutorService 인터페이스를 구현한다.
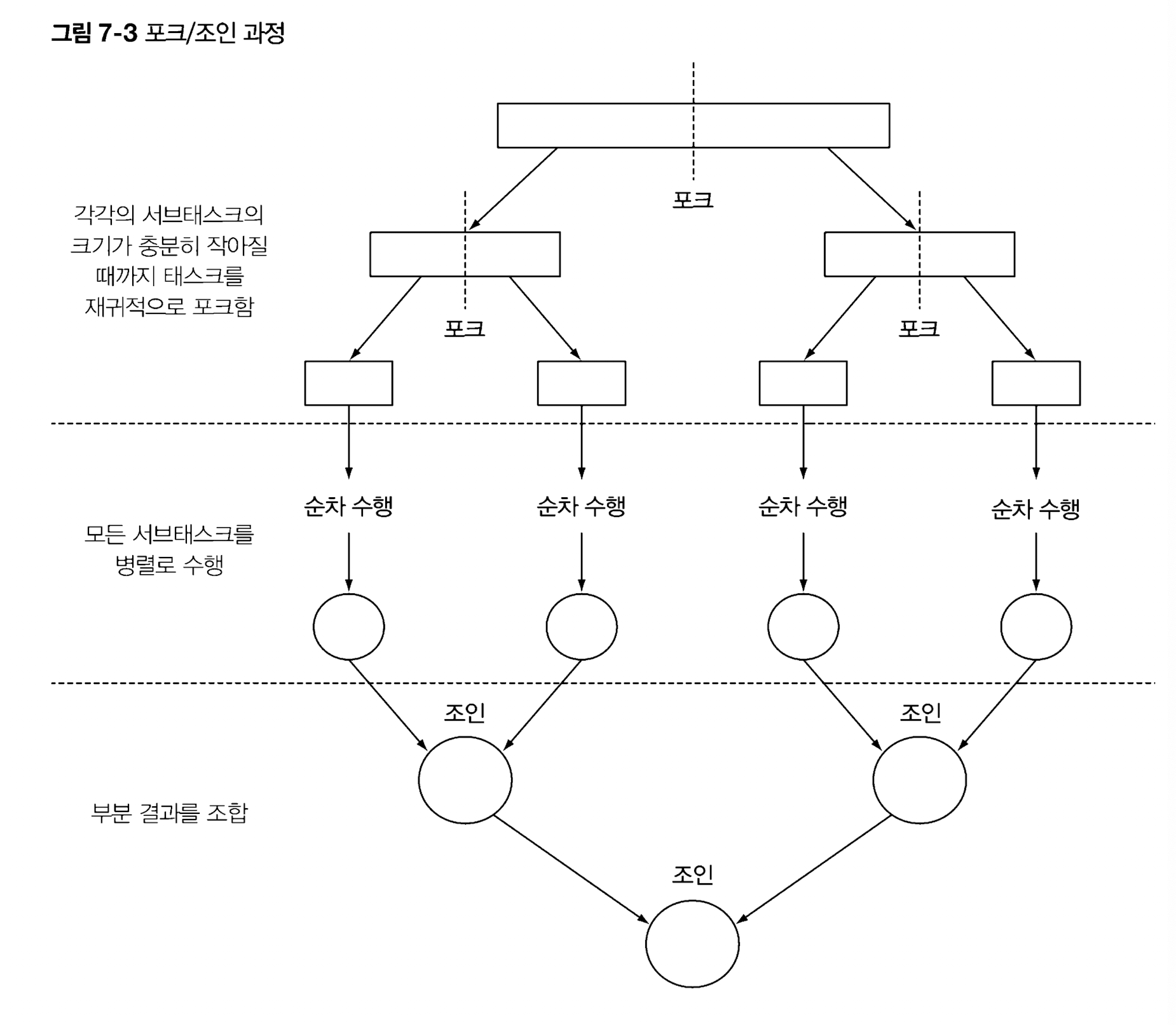
포크/조인 프레임워크를 통해 작업이 분할되고 동시에 처리가 시작되지만 모든 스레드의 동작이 끝나지 않을 수 있다. 포크/조인 프레임워크에서는 작업 홈치기(workstealing)라는 기법으로 이 문제를 해결한다. 작업훔치기 기법에서는 ForkJoinPool의 모든 스레드를 거의 공정하게 분할한다. 할 일이 없어진 스레드는 유휴 상태로 바뀌는 것이 아니라 다른 스레드 큐의 꼬리에서 작업을 홈쳐온다. 모든 태스크가 작업을 끝낼 때 까지, 즉 모든 큐가 빌 때까지 이 과정을 반복한다. 따라서 태스크의 크기를 작게 나누어야 작업자 스레드 간의 작업부하를 비슷한 수준으로 유지할 수 있다.
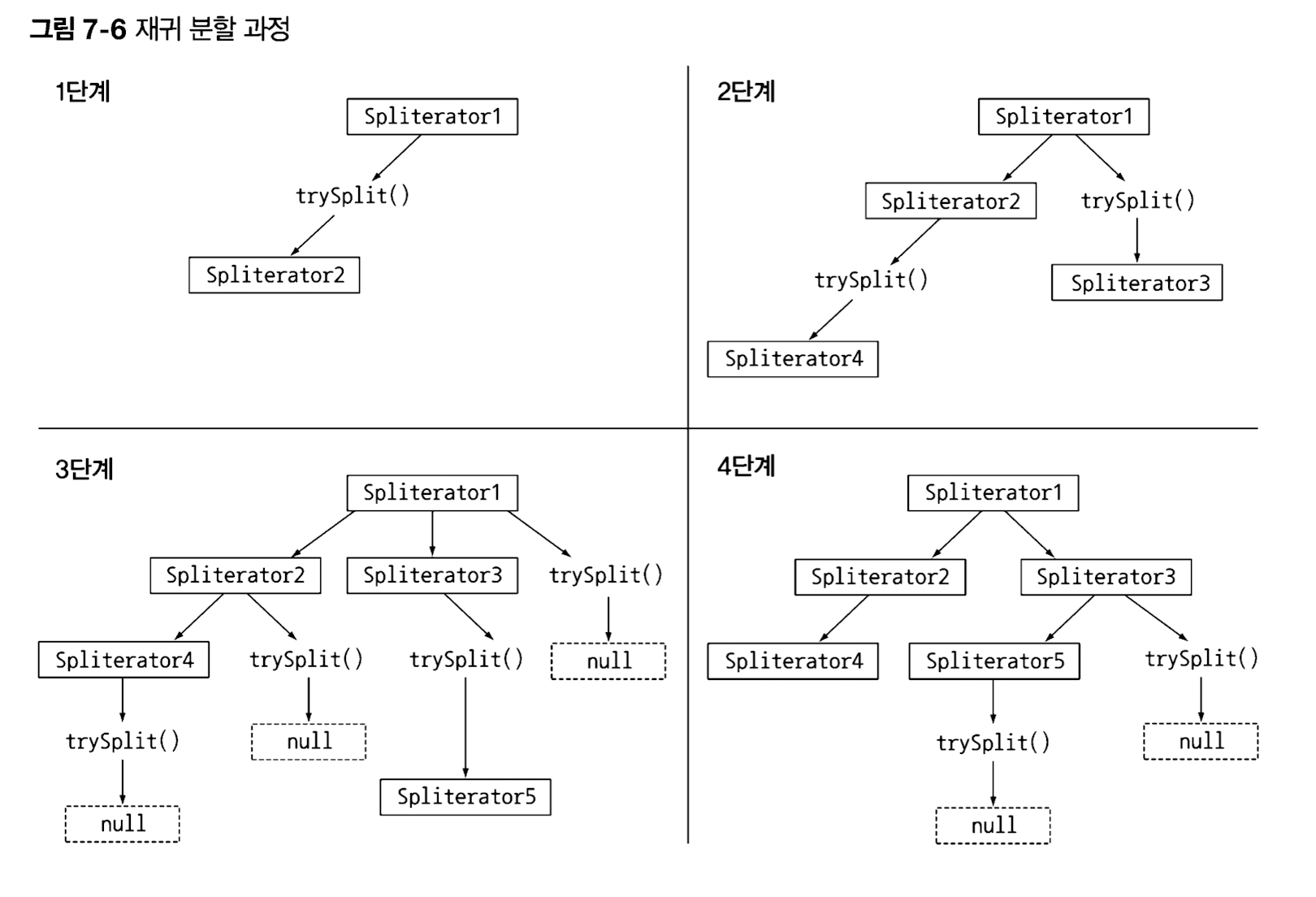
Spliterator는 탐색하려는 데이터를 포함하는 스트림을 어떻게 병렬화하는가?
Spliterator는 이름에서 알 수 있듯, 분할할 수 있는 반복자를 의미한다. 기본적으로 스트림을 어떻게 병렬화 할 지 정의하는 기능을 한다. 병렬 스트림에서 Spliterator를 이용하기 때문에 분할 로직을 개발하지 않고도 분할 기능을 사용할 수 있다.
분할 과정을 살펴보자.
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}
// T는 Spliterator에서 탐색하는 요소의 형식을 가리킨다.
// tryAdvance 메서드는 Spilterator의 요소를 하나씩 순차적으로 소비하며 탐색해야할 요소가 남아 있으면 True를 리턴한다.
// trySplit 메서드는 Spliterator의 일부 요소를 분할해서 두번째 Spilterator를 생성하는 메서드이다.
// estimateSize로 탐색해야 할 요소의 갯수를 구할수 있다.스트림을 여러 스트림으로 분할하는 작업은 재귀적 함수 호출을 통해 최소 단위까지 나눠진다. 첫 번째 Spliterator에서 trySplit()를 호출하면 두 번째 Spliterator가 생성된다. 이 과정을 반복하면서 지수적 분할이 이루어진다. 분할 작업은 trySplit의 결과가 null이 될 때까지 반복된다. null은 더 이상 분할할 수 없는 최소단위의 자료구조임을 의미한다.