MFCC
Mel-Frequency Cepstral Coefficient의 약자로 한글로 풀이하면 멜 주파수 중심 계수이다. Mel은 사람의 달팽이관을 모티브로 따온 값이라고 생각하면 된다. 달팽이관의 각 부분은 각기 다른 진동수를 감지한다. 이 달팽이관이 감지하는 진동수를 기반으로 하여 사람은 소리를 인식한다.
주파수를 특징으로 쓰는 이유다. 하지만 이것에도 특징이 있는데 주파수가 낮은 대역에서는 주파수의 변화를 잘 감지하는데, 주파수가 높은 대역에서는 주파수의 변화를 잘 감지하지 못한다. 달팽이관에서는 저주파 대역을 감지하는 부분은 굵지만 고주파 대역을 감지하는 부분으로 갈수록 얇아지기 때문이다. 위와 같은 달팽이관 특성을 고려한 값을 Mel-scale이라고 한다.
데이터에서 주파수를 성분으로 뽑아내야 한다면 푸리에변환을 해야 할 것이다. 하지만 사람이 발성하는 음성은 그 길이가 천차만별일 것이다. 안녕하세요라고 말하더라도, 어떤 사람은 0.5초, 어떤 사람은 1초가 걸릴 수도 있다. 그래서 음성 데이터에서 한 번에 멜 스케일을 뽑게 되면 이 천차만별인 길이에 대하여 같은 안녕하세요라는 음성이라고 학습시키기는 어려울 것이다.
위와 같은 문제를 해결하기 위해 음성데이터를 모두 20~40ms로 쪼갠다. 여기서 사람의 음성은 20~40ms 사이에서는 음소가 바뀔 수 없다는 연구결과들을 기반으로 음소는 해당시간 내에 바뀔 수 없다고 가정한다. 그래서 MFCC는 음성데이터를 모두 20~40MS 단위로 쪼개고 쪼갠 단위에 대해서 Mel 값을 뽑아서 특징으로 사용한다.
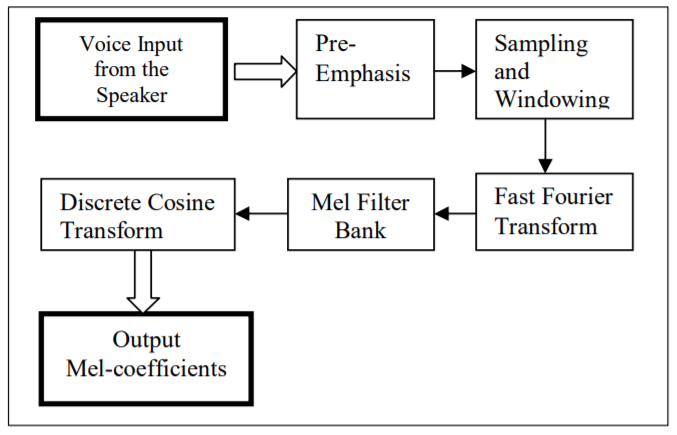
Pre-Emphasis
사람이 발성 시 몸의 구조 때문에 실제로 낸 소리에서 고주파 성분은 많이 줄어들게 되서 나온다고 한다. 그래서 먼저 줄어든 고주파 성분을 변조가 강하게 걸리도록 High-pass Filter를 적용해주는 과정이다.
Sampling and Windowing
Pre-emphasis된 신호에 대해서 앞에서 언급했던 이유 때문에 신호를 20~40ms 단위의 프레임으로 분할한다. 여기서 프레임을 50% 겹치게 분할한다(프레임끼리 연속성을 만들어주기 위해).
만약 프레임이 서로 뚝뚝 떨어지게 샘플링을 한다면, 프레임과 프레임의 접합 부분에서 순간 변화율이 무한대가 될 수 있기 때문이다.
그리고 이 프레임들에 대해 window를 각각 적용한다. 이때 hamming window를 적용한다.
FFT
각각의 프레임들에 대하여 푸리에 변환을 통하여 주파수 성분을 얻는다. FFT까지만 적용하더라도 충분히 학습 가능한 특징을 뽑을 수 있다. 이 때, Mel scale을 적용한 특징이 보통 더 나은 성분을 보인다.
