semantic vs instance
semantic
- 픽셀 별로 사전에 정의한 범주 중 어떤 범주에 해당하는지만 예측
- 픽셀 별로 탐지하고자 하는 범주가 입력된 정답이 필요
- 객체끼리 서로 다름을 인식하지 않고 단순히 픽셀 별로 어떤 범주인지만 인식
weakly-supervised semantic segmentation
- Supervised, semi, weakly, unsupervised가 존재
- weakly supervision(상대적으로 작은 정보)
- 위치정보와 범주정보를 weakly supervision으로 사용
instance
- semantic은 사람 3명을 인식하더라고 instance는 객체간 차이까지 인식할 수 있어야 함
panotic
- semantic+instance = instance(동시 수행)
- 배경을 background로 보는 게 아니라 특정 클래스로 인식
Segment Anything(SAM)
| Task | Model | Data | |
|---|---|---|---|
| ChatGPT | 문장 내 빈칸에 들어갈 단어 예측 | Generative model with large transformer | 웹 Text data |
| SAM | prompt segmentation | pretained mae encoder + CLIP Text encoder + mask encoder | data engine |
prompt segmentation
- 입력 이미지와 prompt를 입력받아 prompt가 설명하는 객체를 추출
- prompt로 weakly-supervision을 사용하고 객체에 대한 segmentation 결과를 mask로 정의
구조
- 두 인코더와 단일 마스크 디코더로 구성
- 입력이미지와 prompt에 대한 특징을 추출할 수 있는 서로 다른 인코더 구성
- 두 인코더에서 나온 표현 벡터를 결합해 원하는 객체만 추출하는 디코더 존재
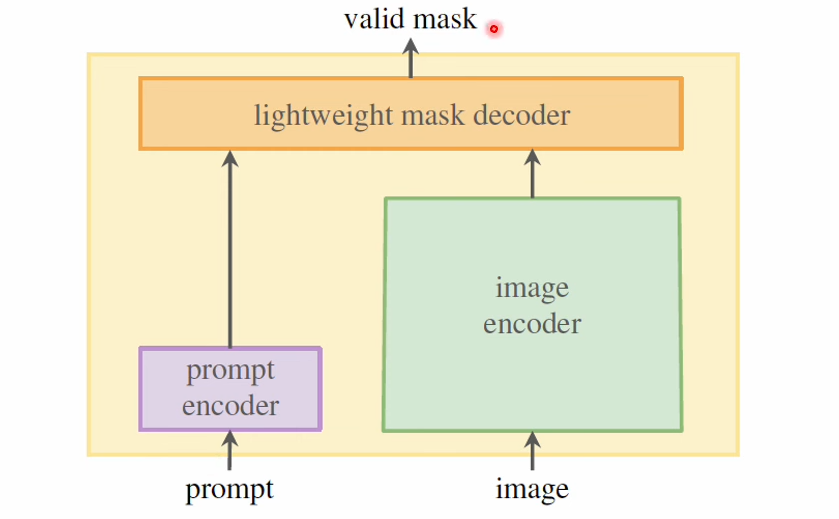
Promptable Segmentation
- 입력데이터: 입력 이미지와 탐지하려는 객체에 대한 Prompt
- 출력데이터: 원하는 객체에 대한 Segmentation 결과
- Prompt가 애매모호하게 입력되었음에도 불구하고 객체에 대한 타당한 마스크 도출 필요
- 사람만 찍었지만 주변에 새까지도 같이 인식하는 경우
- 큰 건물을 찍었지만, 건물의 부속품인 기둥을 건물이라 인식하는 경우
-> image 자체에 대해서는 임베딩, 물체가 있을만한 곳에 칠한 마스크는 합성곱으로 계산, points와 box, text는 prompt encoder를 통해 각각 정답을 찾은 후 이에 대한 score를 계산
masked autoencoder(mae) 라는 사전 학습 방식을 사용하여 학습된 인코더 사용한다. 이 때 사용되는 학습방식은 사진의 일부 패치를 가져와 사진을 확대시키면서 학습시킨 인코더를 이미지에 대한 전반적인 특징이 포함된 벡터일 것이라고 가정하고 SAM 내 이미지 인코더로 사용한다.
-
points와 bbox 에 대해서는 positional 임베딩 진행
-
텍스트에 대한 인코더는 CLIP 방식으로 학슴된 텍스트 인코더 사용
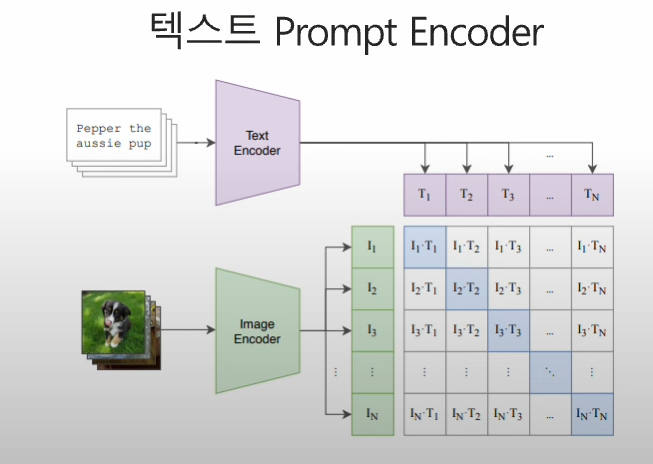
-
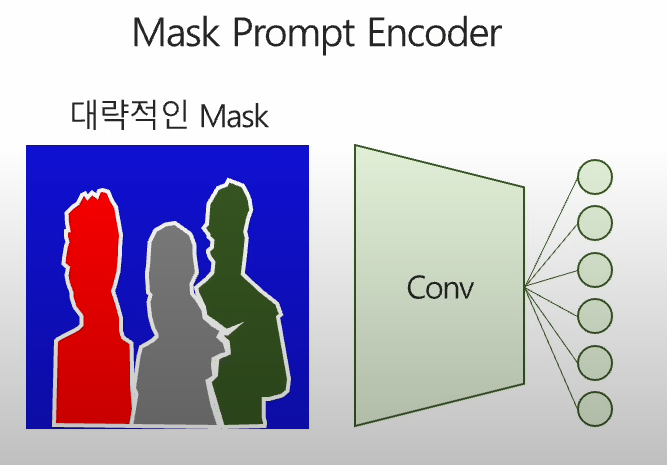
대량적인 마스크에 대해서는 합성곱 연산을 사용해 해당 정보 인코딩
SAM 학습을 위한 데이터
1100만장 입력 이미지와 이에 대한 1억개 이상 MASK를 어떻게 만들었을까?
- Assisted-manual stage
- Semi-automatic stage
- 특정 이미지에 대한 point prompt 및 마스크 생성
- 모델 예측 결과를 prompt로 입력해 더 정확한 마스크 생성 및 보정
- 즉 여기까지 사람이 개입
- Fully-automatic stage
- 이 때 1억개의 99% 이상의 마스크를 생성
- 총 32x32 point prompt를 생성하여 각각 점에 대한 마스크 생성
- point prompt에 대한 여러 마스크 중 스코어가 가장 높은 데이터 추출
Responsible AI
- zeroshot learning in SAM
- 특정 이미지에 단일 point prompt만 입력해서 마스크 3장 생성
- 23개의 데이터 셋 중 16개 데이터 셋에서 더 좋은 결과를 보여줌
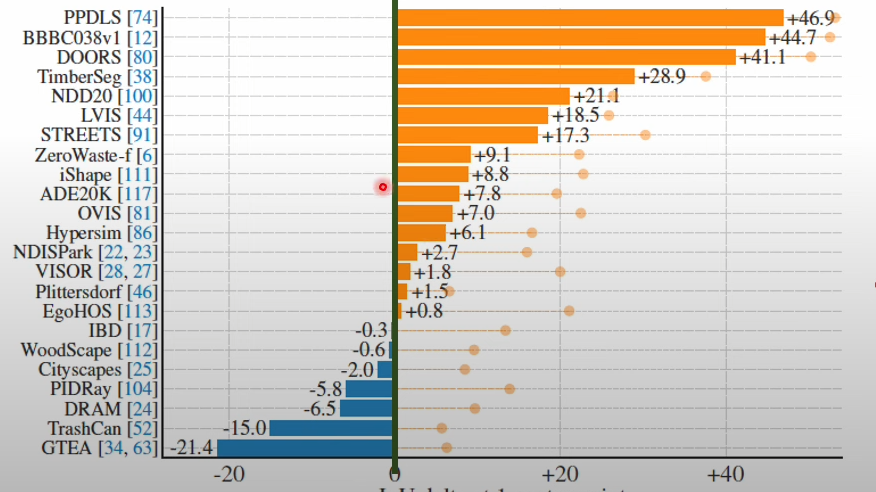
ZEROSHOT EDGE DETECTION
- SAM을 사용해 마스크를 생성 후 SOBEL 필터를 사용해 엣지 변환
- 엣지 디텍션 데이터 셋 내 보다 정확하게 엣지 인식
탐지하기 어려운 객체
- 그림자, 카모플라주
SAM-Adapter
- SAM 가중치 전이학습
- 기존에 있던 prompt encoder는 제거하고 전이학습 진행
- Encoder 내 가중치는 고정한 후 마스크 디코더만 미세 조정
입력 이미지 내 미세한 패턴에 대한 특징 어떻게 추출하나?
-
트랜스포머 블럭 연산 결과와 task-specific 정보를 결합 후 미세 조정
-
기존 트랜스포머 내 가중치 고정 후 어댑터 내부에 대해서만 학습
-
서로 다른 두 MLP와 GELU 활성 함수로 특정 어댑터 구성
-
어뎁터 사용을 통해 배경과 배경과 유사한 관심객체를 분리할 수 있을거라는 기대
이미지 인코더 내 어뎁터를 다수 추가하고 어뎁터와 마스크 디코더 학습 진행
SAM 방식으로 학습된 이미지 인코더 내부 가중치는 학습 대상에서 제외
Human pose estimation
- 사람의 눈을 대체할 수 있는 시각 기능(object가 어디에 있는지에 대한 위치 정보)
- 시각 기능을 통해 획득한 자세에 대한 정보(관절 중심점에 대한 위치 정보)
학습
- 입력 데이터는 사람의 RGB 이미지
- 출력 데이터는 사람의 bbox와 탐지하고자 하는 관절의 xy 좌표
deepPose 모델
- 사람 이미지만 추출 후 고정된 이미지로 변환
- AlexNet 특징 추출기를 사용해 Representation 벡터 산출
- 해당 벡터를 레이어에 입력해 관절별 예측값 산출
- mse 손실 함수 사용
- 관절별 대략적인 위치 파악
- 예측 관절 위치를 실제 이미지에 역변환(사람을 추출 후 고정된 이미지로 변환했기 때문)
- 예측된 두개의 관절들 위치 사이 거리를 계산
- 계산한 거리를 바탕으로 관절에 대한 bbox를 만듬
PDJ(Percent of Detected Joints)
- human pose estimation 평가 지표 및 계산 방식
- 몸통 길이 계산
- (특정 임계값 * 몸통 길이) 가 반지름인 원 생성
- 예측 위치가 원 내부에 있는 지 여부 확인
- 원 내부에 있으면 1(True), 없으면 0(False)
- (1의 개수)/(전체 관절 수) = PDJ
참고할 레이블링 도구
- 도구명: Supervisely
Human pose estimation 알고리즘 계층도
한 사람
- 관절별 좌표 예측 ##
- 특정 관절이 존재할 만한 곳을 히트맵 형태로 출력
여러 사람
- 사람을 우선적으로 탐지 후 탐지 결과 내에서 관절별 좌표 예측
- 탐지하고자 하는 관절에 대한 위치 예측 후 사람 별로 나눔
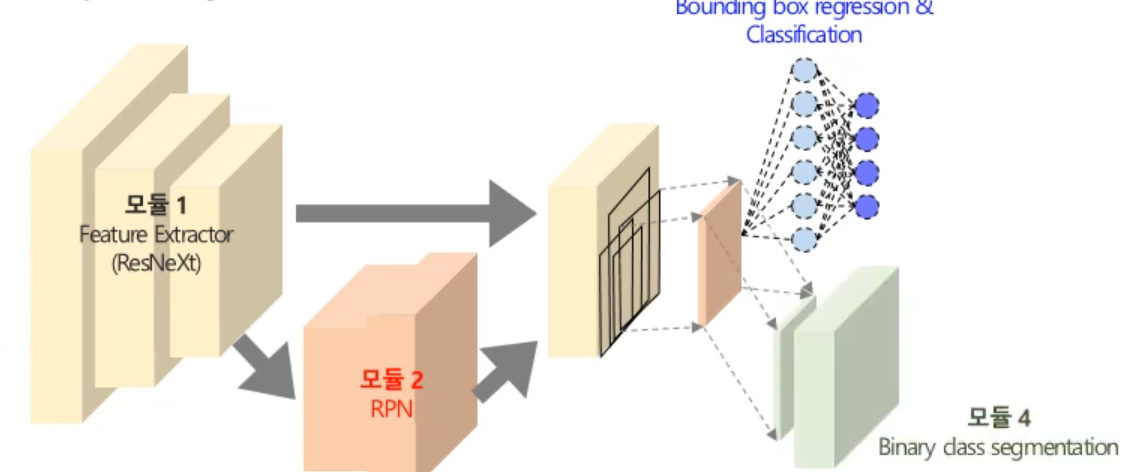
Mask R-CNN
- Object detection + instance segmentation + human pose estimation을 하나의 모델로 통합 가능
기본 아이디어
- 객체가 있을만한 영역 탐지(bbox detect)
- 탐지한 영역 내 어떠한 범주가 있을 지 예측
- 상자 내 픽셀에서 탐지한 범주인지 아닌지 분류
구조
- feature extractor(resnext)
- region proposal net(rpn)
- bbox reg and classi
- binary class seg
mask r-cnn학습을 위한 관절별 좌표 값 변환
-
관절별 좌표를 픽셀 단위로 지정 -> 마스크 생성
-
특정 관절 좌표에 해당하는 픽셀은 1, 나머지는 0인 마스크
-
구조에 5. human estimation을 추가
OKS(Object Keypoint Similarity)
- 관절 예측 좌표와 실제 좌표사이의 유클리디언 커리를 이용
instance segmentation <- cost effective method
- 정답 데이터를 구축하기 위해 높은 수준의 labeling cost 필요
CutLER
- MaskCut, DRop loss, Self-training
- MaskCut이 놓친 객체는 계속 검출되지 않는 방향이지만, 새로운 객체를 탐색할 수 잇도록 Droploss 전략을 제악.
- 첫번째 단계에서 MaskCut을 통해 생성된 Coarse Mask를 슈도 마스크로 사용하여 학습
DINO
- knowledge distilation 관점에서 teacher 모델이 추출한 특징을 학생이 학습
- Emerging Properties는 복잡한 시스템이나 모델에서 개별 구성 요소들이 상호작용하면서 나타나는 새로운 특성이나 행동
- Knowledge Distillation: 큰 모델이 학습한 지식을 더 작은 모델로 전달하여, 작은 모델이 큰 모델의 성능에 가깝게 따라가도록 하는 과정
NCut
- 이미지를 전체 픽셀이 서로 연결되어 있는 그래프로 보고, 두개 또는 그 이상의 하위 그래프로 나누는 기법
- 일반화된 eigenvalue system을 해결함으로써, 두 하위 그래프로 그래프를 분할 하는 비용을 최소화 함
- Eigenvalue(고유값)와 Eigenvector(고유벡터)으로 주어진 행렬을 변환할 때 벡터의 방향을 변하지 않고 크기만 일정 배율로 변하는 스칼라 값을 의미
의의
- 레이블 없이 여러 문제에 대한 탐지 및 분할 가능
- 교육하기 쉽고 단순
- zeroshot에 좋음
BoxTeachure
- 슈도 마스크를 사용하는 방법론 제시
Weakly Supervised Segmentation, BoxInst
- 픽셀기반 정답보다 Weakly label을 활용하여 segmentation 진행
Weakly label?

BoxInst(High-Performance instance Segmentation with Box Annotations
- ConInst를 사용하여 이미지의 인스턴스 개수만큼 마스크 헤드 확보
- ConInst: ROI가 없는 합성곱으로 인스턴스 세분화
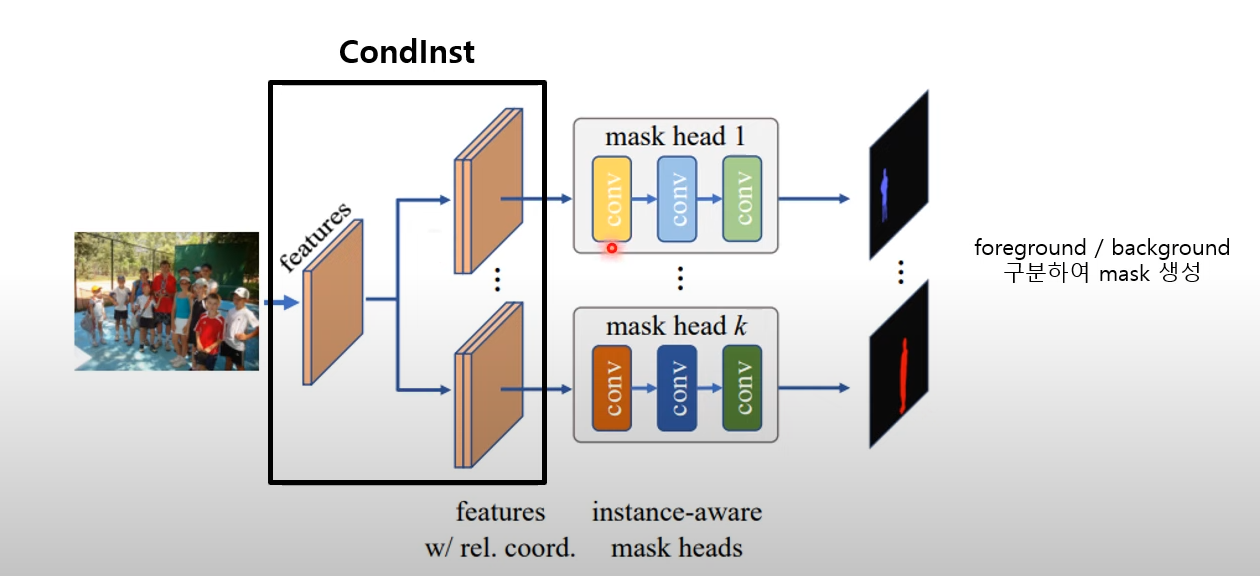
- Box-supervised 방식으로 생성한 마스크를 슈도 라벨로 활용
BoxTeachure
-
Teacher 모델을 활용하여 슈도 마스크를 생성 후 분류 점수와 마스크 확률에 따라 마스크 신뢰점수 추정
-
Box-based Mask Assingment 알고리즘을 통해 슈도 마스크 GT BBOX에 하나씩 할당
-
Stuend 모델은 gt box와 슈도 마스크를 활용한 훈련을 통해 최적화
-
EMA를 통해 Teacher 모델을 업데이트 하여 고품질 슈도 마스크 생성
-
슈도 마스크가 가지고 있는 노이즈를 완화시키기 위해 픽셀 간 유사성을 활용하여 loss 제안
Human activity recognition
-
스마트 시계 사용 활성화 인간 활동에 대한 시그널 정보 수집
-
다양한 분야에서 CCTV 사용해 영상 정보 수집
-
시그널 또는 영상을 입력 받아 인간이 어떠한 행동을 하고 있는지를 인식
-
senseor based har과 vision based har 로 나뉘고 vision based har은 다음과 같이 나뉨
- video-based har과 skleton based har로 나뉨.
- skeleton은 여러 변화에도 강건한 성능을 보유(촬영 각도, 배경관련 요소 x)
Spatial Temporal Graph Convolutional Networks for Skeleton based AR(Action Recognition)
그래프 데이터란?
- 여러 점과 선의 집합(Vertex, Node, Edge)
- 데이터 간의 관계를 표현할 때 사용하는 데이터 형태
프레임별 skeleton을 연결 해 단일 그래프로 변환
- 영상 내 프레임별 skeleton 산출(intra-body connection)
- 프레임 사이 동일한 관절에 대한 연결 생성
ST-GCN
- 그래프 내 특정 관절을 선택하고 이와 지역적 시각적으로 연결된 관절 선택
- 9개 ST-GCN 블럭으로 구성되며 ResNet과 같이 블럭 사이 잔차 학습 진행
- 마지막 연산은 Softmax
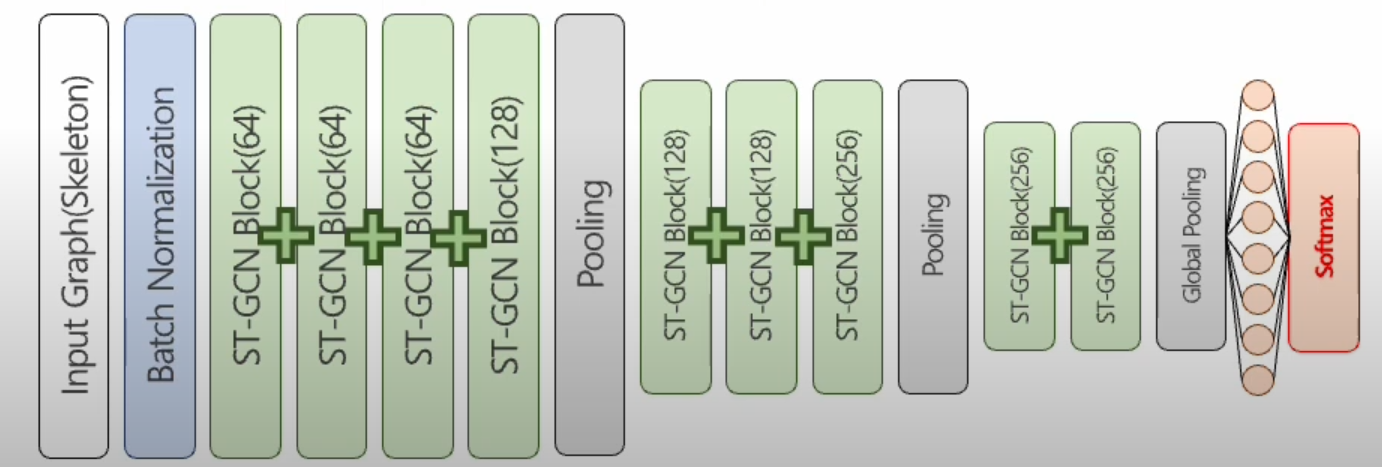
요약
- 영상데이터에 대해 OpenPose를 이용해 Skeleton 추출
- 여러 프레임에 해당하는 Skeleton을 ST-GCN입력데이터로 사용
- Skeleton 특징 추출 및 행동 인식 진행
Cyber Phisical System with Human in the Loop
- 인간 행동을 인식하고 행동에 대한 결과 제시
- 인간이 제시한 결과를 확인하고 다른 행동을 진행하며 둘 사이에 소통 진행
- 인간 행동 인식을 위해 Skeleton을 추출하고 주성분 분석을 사용해 차원 축소
- 차원 축소된 Skeleton 특징 벡터를 입력 해 위험 여부 분류 모델 학습
고령자 일상 행동 인식을 위한 휴먼 케어 로봇 개발(ETRI)
- 진행 중...
Unsupervised Semantic Segmentation
Mutual information maximization
상호 의존 정보(Mutual infromation)
- 두 확률변수 사이의 상호의존성을 측정한 것으로, 한 변수를 통해 얻어지는 다른 한 변수에 대한 정보량
- 두 확률 변수의 독립여부를 측정할 수 있어 상관계수와 유사하게 두 변수 사이의 관계를 나타내는 척도
- 두 확률변수의 상호의존정보를 높이는 방향으로 모델을 학습하면 두 변수의 상호의존성이 높아진다
-> 결국 두 이미지 사이의 공통된 특징이 잘 추출되는 방향으로 모델을 학습
AC
- 이미지 생성 방법론 중 autoregressive 모델인 pixelcnn의 masked 합성곱을 개선
- masked 합성곱을 통해 입력 이미지에 대한 두 개의 view를 생성하고 예측된 결과에 대해 상호의존정보를 최대화
- masked 합성곱은 합성곱 연산시 합성공 필터에 0을 적용하는 것, 모델 학습시 업데이터 안함
- 이 논문에선 단순화된 마스크 합성곱을 제안했다.
- blind spot이 생기는 기존의 마스크 합성곱의 단점을 해결하기 위해, attention mechanism을 적용하고 지그재그 타입의 합성곱 마스크 형태 추가
- 실제로 합성곱 마스크의 종류가 다양할 수록 성능 향상
IIC
-
입력 이미지 -> CNN -> FC -> Output 단순한 모델 구조
-
입력이미지에 데이터 증강을 적용해 positive pair를 생성하고 동일한 모델에 통과시켜 예측결과(z,z')를 얻음
-
두 예측결과인 z와 z' 사이의 mutual information이 최대화되도록 모델 학습
-
두 이미지 간의 공통 특징을 최대한 추출하도록 학습하고 이 정보를 기반으로 clustering
Overclustering
- 목표 클래스 수보다 더 많은 수의 cluster를 가진 overclustering head를 추가하여 학습
InfoSeg
- 이미지의 local feature와 global feature를 함께 학습
PiCIE
- 이미지의 pixel-level feature representation 과 k menas clustering을 동시에 학습하고 픽셀 단위 레이블링
- 입력 이미지에 대한 augmentation을 통해 두 개의 view를 생성하고 각 view에서 얻은 pixel-level feature의 클러스터링 결과가 같아지도록 모델 학습
faster r-cnn
물체가 있을 거같은 곳들에 미리 뽑아 cnn 실행.
mask r-cnn
keypoint r-cnn
