크롤링 특강 (11월 11일)
강의 <데이터 구축을 위한 웹 크롤링>
크롤링 : 웹사이트에서 자동화된 방법으로 데이터를 수집하는 과정
FIRST, 크롤링할 Web URL 분석
SECOND, HTTP GET 요청 송신 및 응답 수신
THIRD, html 파싱 : beatifulsoup 등 파서를 통해 HTML 에서 원하는 정보 추출
FINALLY, 데이터 정제 후 JSON 등 저장 ->데이터 베이스에 저장

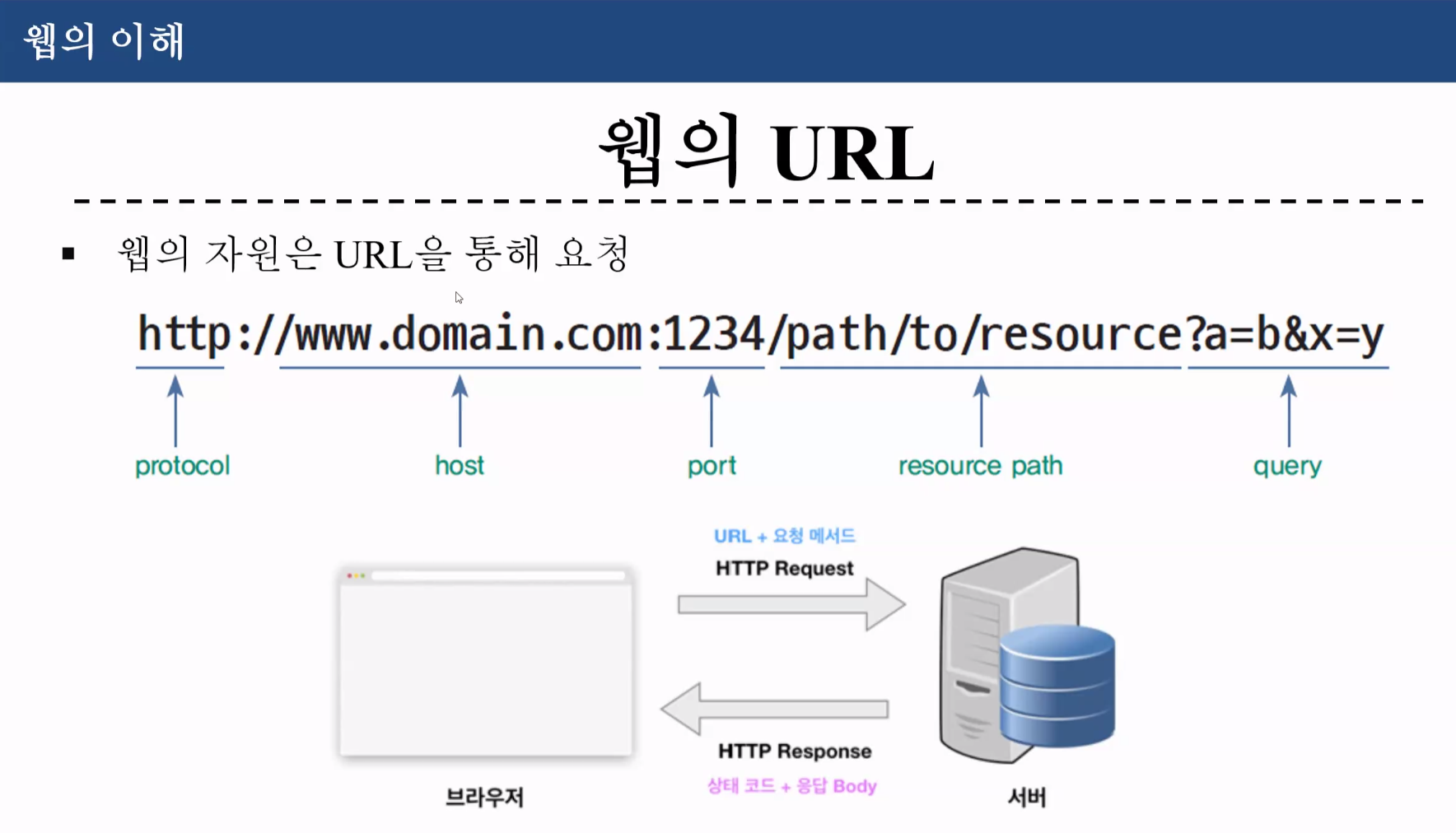
protocol : 주고받는 규약
host : 서버의 ip 주소
port :
resource path : 서버 설계자가 정함
query : 똑같은 경로지만, 특정 파라미터 추가
a=b x=y 페이지넘버pageno=1 언어lang=en

브라우저 -> url 접속 : get
- 별은 all
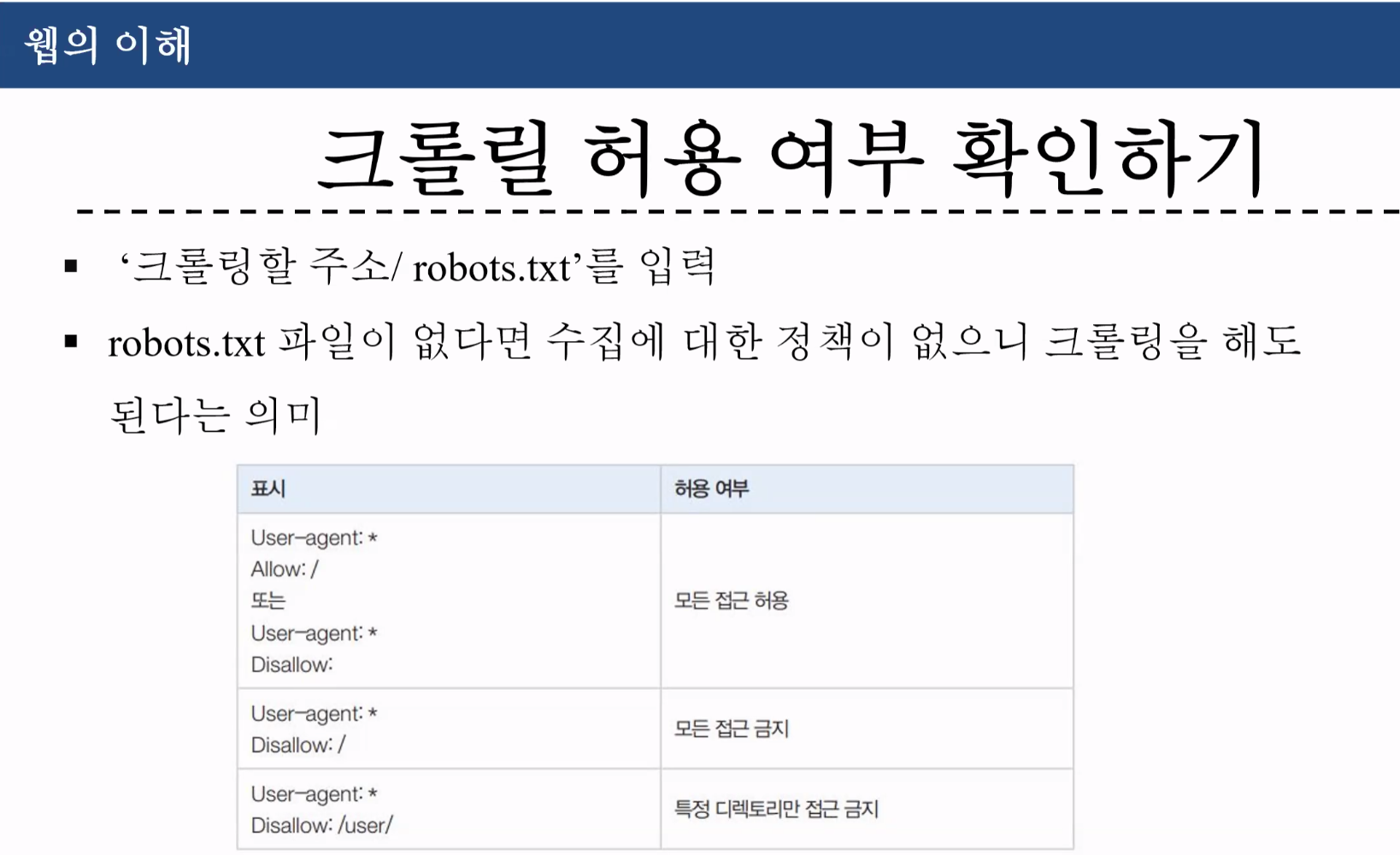

네이버 메인 화면에서
https://www.naver.com/robots.txt 주소창에 검색
User-agent: *
Disallow: /
Allow : /$
Allow : /.well-known/privacy-sandbox-attestations.json
의미는?

민증같은
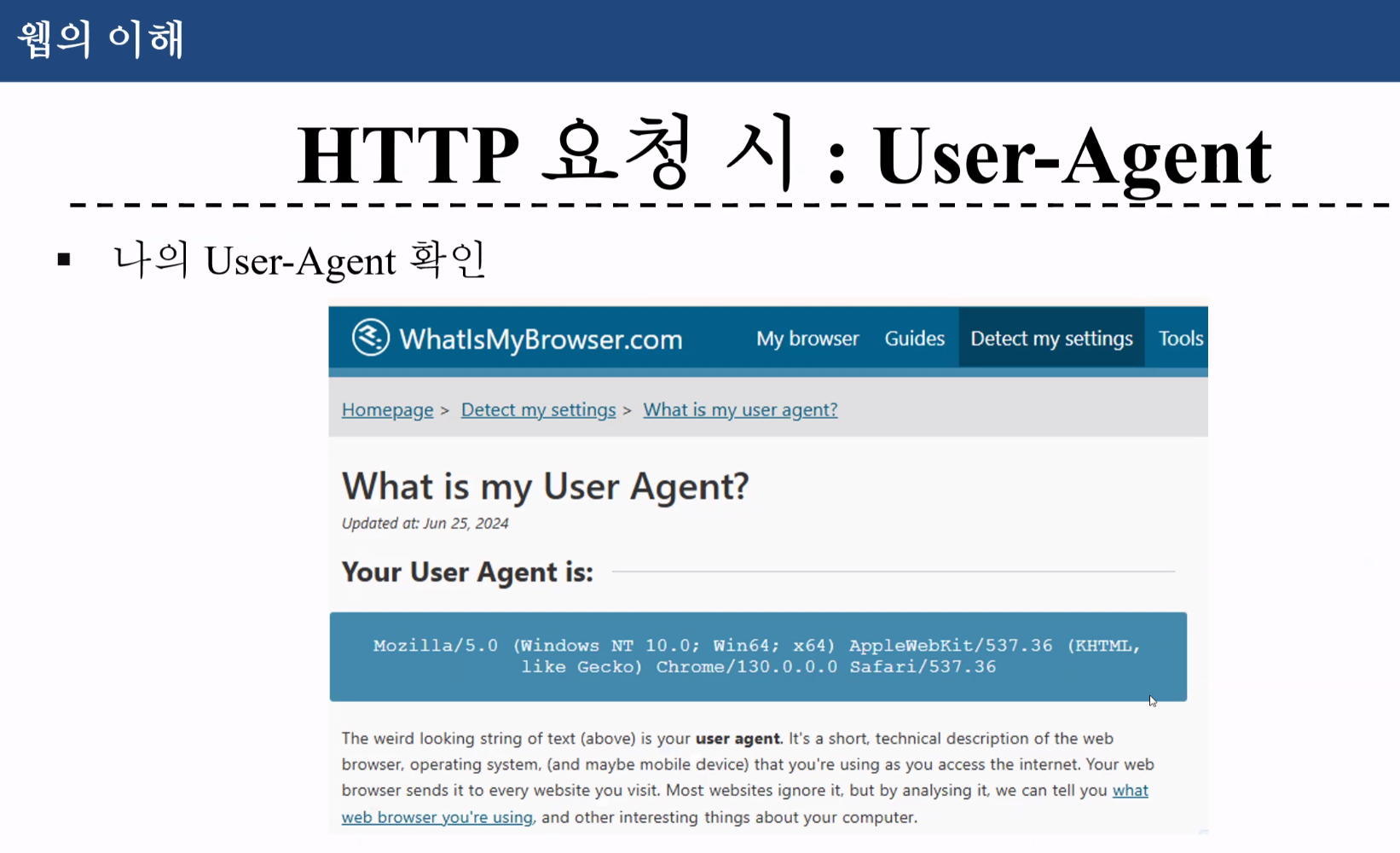
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36
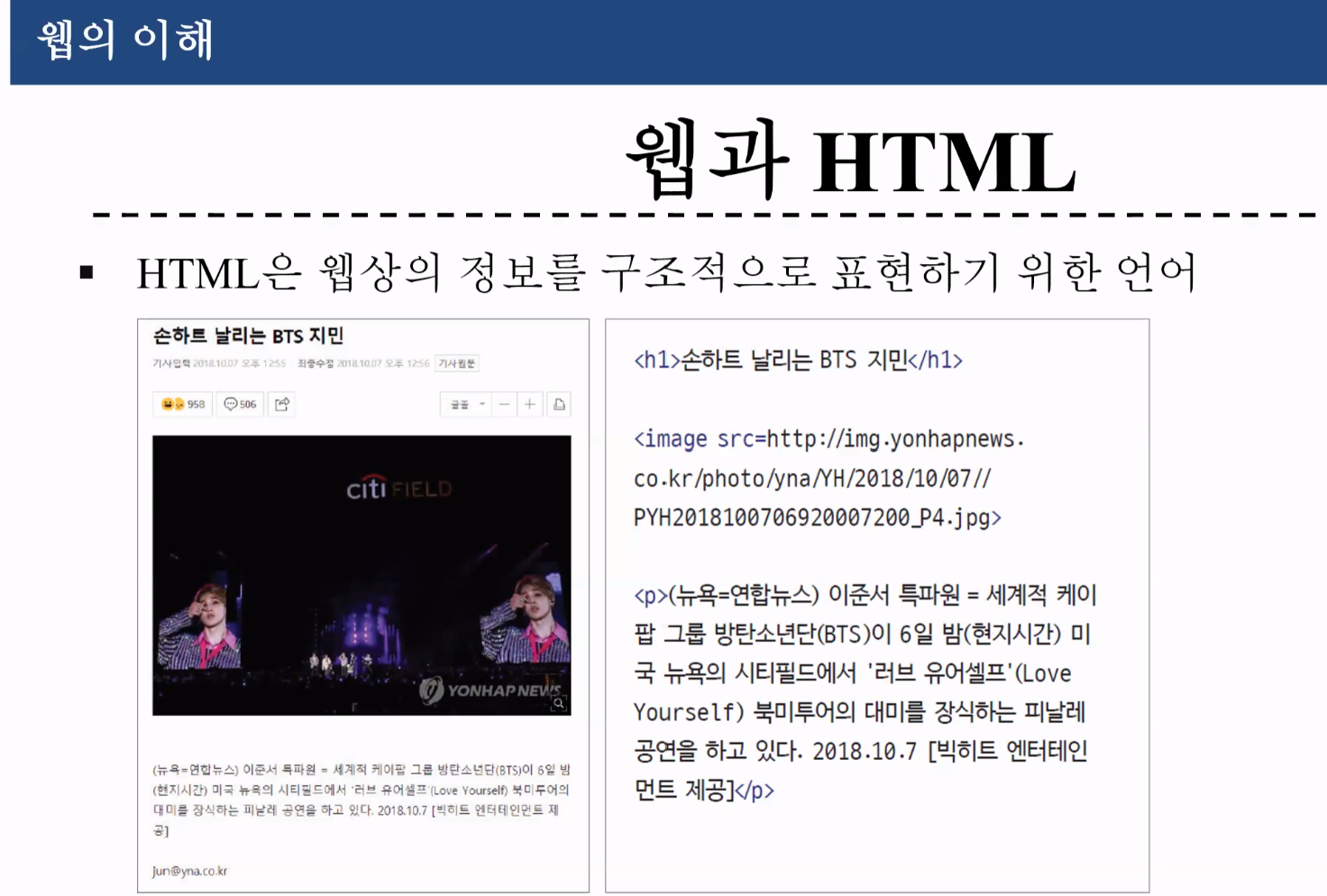
html : tag 기반으로
ul : 순서 있는? 찾아보기
ol : 순서 없는?
li?
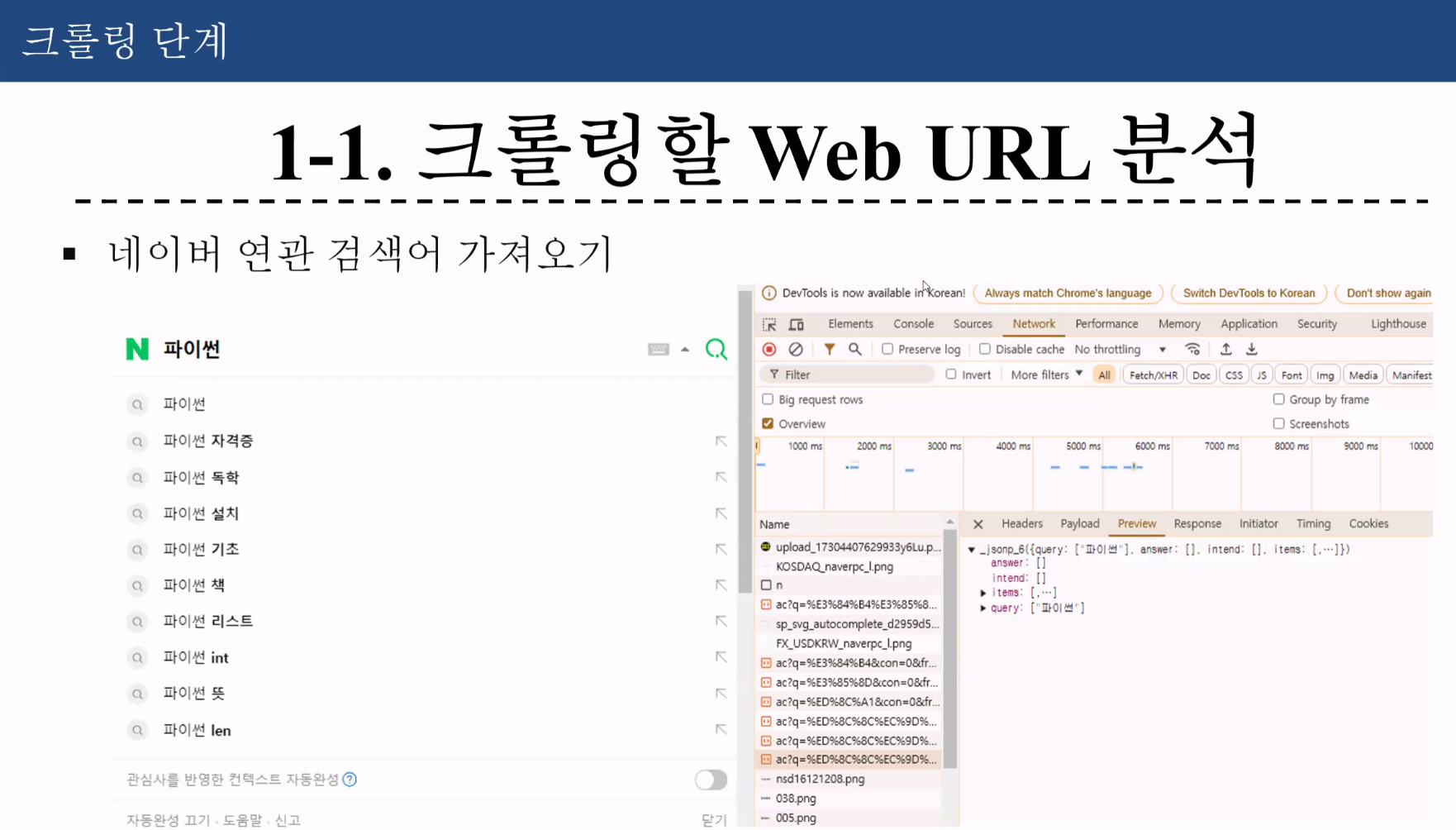
한글이 이상한 문자로 바뀐거 %ED%8C~~ : 언어코드
크롬에서는 그렇지 않음 KINDFUL 해석
파이를 ai라고 작성 바꿔
https://ac.search.naver.com/nx/ac
?q=ai&
con=0&
frm=nv&
ans=2&
r_format=json&
r_enc=UTF-8&
r_unicode=0&
t_koreng=1&
run=2&
rev=4&
q_enc=UTF-8&
st=100&
_callback=_jsonp_4
셀렉해서 삭제하며 비교해보기 기존 내가 원하는 정보 살아있나
지워도 큰 이상 없으면 지우기
https://ac.search.naver.com/nx/ac
?q=ai&
st=100&
https://ac.search.naver.com/nx/ac?q=ai&st=100&
데이터 포멧 : 파이썬 기준으로는 딕션어리,
여기서는 JSON포멧이라고함

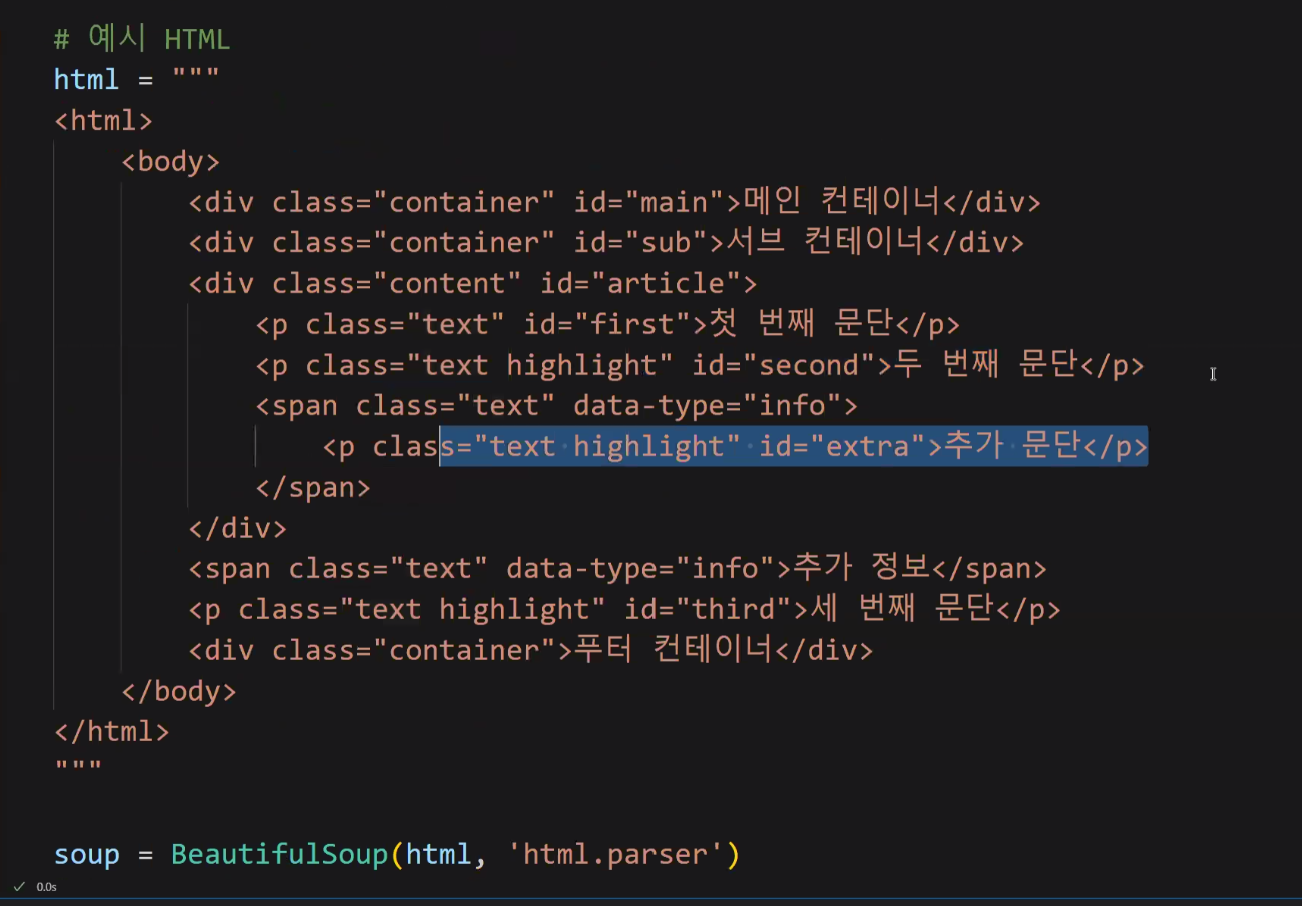

Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36
"""
독스트링
"""
https://velog.io/@worksso/%ED%81%AC%EB%A1%A4%EB%A7%81-%ED%8A%B9
http 상태 코드
https://www.hollys.co.kr/store/korea/korStore2.do
json scv 차이는?
과제 : 네이버 주식
네이버 페이 증권 페이지 들어가서 삼성전자 검색
시세 들어가보면, 페이지 확인
-> 1,2,3, 페이지라도 다 똑같은 url -> url 사용불가
-> 사용자 관리 networks =? size+day.naver 어쩌고 찾아서 복사(https://finance.naver.com/item/sise_day.naver?code=016360&page=4
) -> 블라우저에 검색
page=10 등 가능해짐
개발자 도구 element로 보면, tr태그 있고, td 있고
날짜 종가 전일비 시가 고자 저가 거래량
데이터 정제하는 방법:
숫자 39,000을 39000로 만들기 찾아보기
파싱 : beatifulsoup 라이브러리로 파싱
이 말은, 원하는 정보를 태그로 뽑아올 때
