컬렉션 조회 최적화 (OneToMany)
OrderItems 조회 V1
@GetMapping("/api/v1/orders")
public List<Order> ordersV1(){
List<Order> all = orderRepository.findAll(new OrderSearch());
for (Order order : all) {
// 강제 초기화
order.getMember().getName();
order.getDelivery().getAddress();
List<OrderItem> orderItems = order.getOrderItems();
orderItems.stream().forEach(o -> o.getItem().getName());
}
return all;
}<이건 기본적으로 추가해줘야하는!>
@Bean
Hibernate5Module hibernate5Module() {
return new Hibernate5Module();
}강제로 프록시 초기화를 시켜주어, orderItems 각 객체마다, orderItem 프록시를 초기화 시켜주어 name에 값을 불러온다.
-
데이터는 잘 불러와지나, 각각 프록시 강제 초기화마다 sql 문을 날리는 것을 확인할 수 있음.
-
엔티티를 직접 노출하기 때문에, api 스펙이 Entity의 영향을 받게 됨
OrderItems 조회 V2 - DTO화
일단 DTO 를 만들자
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2(){
List<Order> all = orderRepository.findAll(new OrderSearch());
List<OrderDto> collect = all.stream().map(o -> new OrderDto(o)).collect(Collectors.toList());
return collect;
}
@Data
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItem> orderItems;
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
order.getOrderItems().stream().forEach(o -> o.getItem().getName());
orderItems = order.getOrderItems();
}
}이제 Entity의 변경에 Api 스펙이 변경되는 일은 없다!
(컴파일 에러로 잡을 수 있게 됨)
@Data 는 api 끝단에서 역할!
DTO 안에 Entity 가 있는 것은 좋지 않음!
직접적으로 1차 Api 스펙에는 영향을 주지 않지만, 내부 Entity 속성이 그대로 노출됨
(OrderItem, Item)
- 엔티티에 대한 의존을 완전하게 끊어야함!!
귀찮더라도,List< OrderItem >을 전부 DTO 로 변환해 주어야함
@Data
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems; // DTO로 수정
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
// DTO 로 수정
orderItems = order.getOrderItems().stream().map(o -> new OrderItemDto(o)).collect(Collectors.toList());
}
}
// 새로운 DTO
@Data
static class OrderItemDto {
private String itemName;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
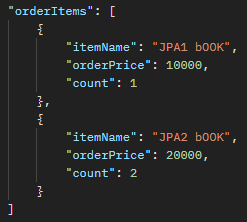
원하는 정보들만 뽑아내서 DTO로 만들 수 있음!!
OrderItems 조회 V3 - fetch join
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3(){
List<Order> all = orderRepository.findAllWithItem();
List<OrderDto> collect = all.stream().map(o -> new OrderDto(o)).collect(Collectors.toList());
return collect;
}
<OrderRepository.java>
public List<Order> findAllWithItem() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class).getResultList();
}이처럼 fetch join 하면 될 것 같음!!
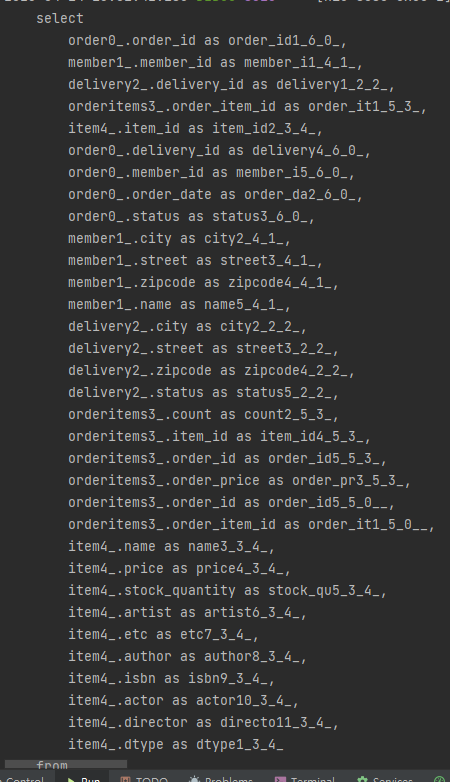
(이 사진도 다가 아님)
정말 어마무시한 쿼리문 하나가 나가는 것을 볼 수 있다!!
n 번의 쿼리를 날리면서 성능을 잡아먹다가, 한번으로 최적화된 모습!
Fetch Join의 고질적인 문제인, 테이블 데이터 중복!!
데이터를 받아보면 티가 난다! 같은 id 값이 두번 들어옴!!
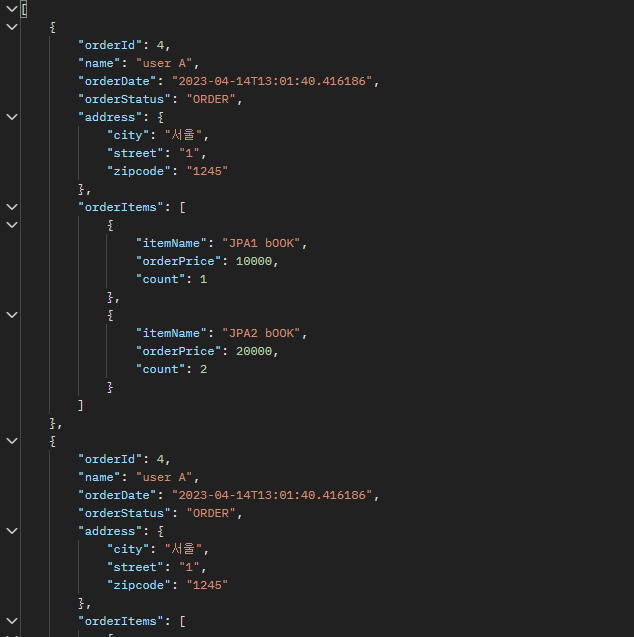
Database 입장에서는 table join 이 되어버린 것임! (데이터 뻥튀기)

아이러니하게도 같은 참조값을 가지기는 함! jpa 가 자체적으로 같은 객체로 만들지만, 알아서 하나로 보내주지는 않음!!
기억나는가? 어떤걸 써야하는지? 바로Distinct
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class).getResultList();
}이제 중복없이 잘 나온다!!
SQL 문에서의
distinct와 무엇이 다를까?
DB Query 에서의 행동이 다르다기 보다는! (이거는distinct가 있으나 없으나 같음)
JPA 에서 자체적으로 버려주는 기능임!!! (들어오는 데이터는 뻥튀기 된 채로 들어옴)
엄청난 제약 조건 (fetch 조인)
치명적인 단점 하나가 있음!!!!!!!!!!!!!!!!!!!!!
진정한 의미의페이징이 불가능해진다
전부다 받아온 다음에, 그 데이터를 기반으로 페이징처럼 출력을 함!!
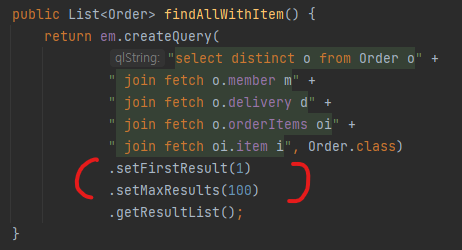
- 메모리 관점에서 의미 퇴색 (n개의 데이터를 다 불러오고, 그 중 몇개를 반환하는 꼴)
- 진정한 의미의 페이징 애매 (distinct 일때는 비슷하게 가능하긴 하지만...)
order 기준으로 페이징 하는 것이 아닌, 다 쪽의 item 기준으로 페이징이 일어남

(hibernate에서도 warn 창을 띄워줌)
일대다의 경우엔 오히려
fetch join을 사용하지 않는 것이 좋음!
🔶🔶 일대다(컬렉션) fetch join 금지!!!!!! 🔶🔶
- 10만개의 데이터가 메모리에 한방에 불러와진다면...!!
- 오우... 대형사고...
- 작은 데이터라는 것이 확실하면, 상관 없긴 함
- 컬렉션 페치 조인은 2개 이상 사용 금지!!
OrderItems 조회 V3.1 - 페이징 & 한계 돌파
페이징도 하고, 컬렉션 엔티티를 함꼐 조회하려면 어떻게 해야할까!!
(아주 비장하게) 지금부터 코드도 단순하고, 성능 최적화도 보장하는 매우 강력한 방법을 소개하겠다!
기존에 @xToOne 은 전부 fetch join
나머지는 하나씩 프록시 초기화 시키면서 들고오는 거 대신, batch 로 들고오는 방법으로!!
<application.yaml>
jpa:
hibernate:
ddl-auto: create
properties:
hibernate:
format_sql: true
default_batch_fetch_size: 100그러면 sql query 문이 세번만 일어남!!
100개의 프록시 초기화를 동시에 진행한다고 생각하면 됨! (lazy 걸려있는 모든 프록시들)
- Order : fetch join (1) <= batch 전 1
- OrderItem : batch (1) <= batch 전 n
- Item : batch (1) <= batch 전 n
batch 사이즈 설정만으로도!
1 / n / n ======>>>> 1 / 1 / 1 처럼 구현할 수 있음 (batch 사이즈에 따라 약간 차이)
- 각각 프록시 초기화를 사용한다면, query sql 효율성이 떨어지고,
- 모두 fetch join 을 사용한다면, 메모리 이슈 / 페이징 이슈가 생김
1) batch를 활용해서 쿼리 듬성듬성 날리기
2)@xToOne관계에만fetch join사용!
2-1) join을 안하기 때문에,@OneToMany일때 fetch join 은 데이터 뻥튀기가 일어나기에, 데이터 전송량 자체를 줄여주는 효과도 있음!! (이거 만개라고 생각하면, 데이터 양이 어마무시함)
꼭 글로벌하게 설정할 필요는 없음
@BatchSize(size = 100) 이런식으로 지정 가능
결론
@xToOne관계는fetch join해도 페이징에 영향을 주지 않는다.
따라서@xToOne관계는fetch join으로 쿼리수를 줄이고- 나머지는 batch size 를 설정하여 최적화!!
- 사이즈를 얼마로 두는 것이 좋은가?
maximum 은 보통 1000 으로 보는 편!! (100 ~ 1000 사이 권장)
애매하면 100, 500 으로 두고 쓰셈!
OrderItems 조회 V4 - DTO 로 조회 (1)
OrderRepository 에 구현하는 것이 아닌,
새롭게 OrderQueryRepository 를 만들어서 따로 관리!!
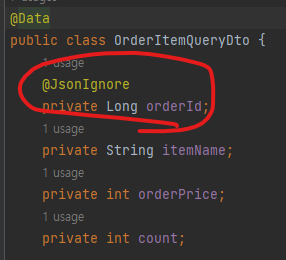
<OrderItemQueryDto.java>
@Data
public class OrderItemQueryDto {
@JsonIgnore
private Long orderId;
private String itemName;
private int orderPrice;
private int count;
public OrderItemQueryDto(Long orderId, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}<OrderQueryDto.java>
@Data
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemQueryDto> orderItems;
/**
* collection 을 바로 주입 받을 수가 없음
* 해당 DTO Constructor 는 jpql 에서 사용됨.
*/
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address/*, List<OrderItemQueryDto> orderItems*/) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.orderItems = orderItems;
}
}<OrderQueryRepository.java>
@Repository
@RequiredArgsConstructor
public class OrderQueryRepository {
private final EntityManager em;
public List<OrderQueryDto> findOrderQueryDtos(){
List<OrderQueryDto> result = findOrders();
result.forEach(o -> {
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId());
o.setOrderItems(orderItems);
});
return result;
}
private List<OrderItemQueryDto> findOrderItems(Long orderId) {
return em.createQuery("select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count)" +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id = :orderId", OrderItemQueryDto.class)
.setParameter("orderId", orderId)
.getResultList();
}
private List<OrderQueryDto> findOrders() {
return em.createQuery("select new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address)" +
" from Order o" +
" join o.member m" +
" join o.delivery d", OrderQueryDto.class)
.getResultList();
}
}Query 문 : 루트 1번, 컬렉션 N번 (for 문 돌면서)
ToOne 관계들을 먼저 조회하고, ToMany(1:N) 관계는 각각 별도로 처리한다.
row 수가 증가하지 않는 ToOne 관계는 조인으로 최적화하기 쉬우므로 한번에 조회하고, ToMany 관계는 최적화하기 어려우므로findOrderItems()같은 별도의 메소드로 조회
이런 방식은 N+1 문제를 야기한다.
OrderItems 조회 V5 - DTO 로 조회 (2)
public List<OrderQueryDto> findAllByDto_optimization(){
List<OrderQueryDto> result = findOrders();
List<Long> orderIds = result.stream().map(o -> o.getOrderId()).collect(Collectors.toList());
List<OrderItemQueryDto> orderItemQueryDtos = em.createQuery("select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count)" +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItemQueryDtos.stream().collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId()));
result.forEach(o -> o.setOrderItems((orderItemMap.get(o.getOrderId()))));
return result;
}in 을 활용해서 한방에 다 가져오기!
OrderItemQueryDto 에 orderId 를 넣은 이유가 여기에 있었음!!
v4 와 다른 점은 query 문을 한번만 날린다는 것!!
OrderItems 조회 V6 - DTO 로 조회 (3)
<OrderFlatDto.java>
@Data
public class OrderFlatDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private String itemName;
private int orderPrice;
private int count;
public OrderFlatDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}plat 형태로 DTO를 설정하여, 직접 jpql 을 설정하면, query 문은 한방에 나간다! (페이징은 x)
public List<OrderQueryDto> findAllByDto_flat(){
List<OrderFlatDto> orderFlatDtoList = em.createQuery("select new" +
" jpabook.jpashop.repository.order.query.OrderFlatDto(o.id, m.name, o.orderDate, o.status, d.address, i.name, oi.orderPrice, oi.count)" +
" from Order o" +
" join o.member m" +
" join o.delivery d" +
" join o.orderItems oi" +
" join oi.item i", OrderFlatDto.class).getResultList();
return orderFlatDtoList.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(),
o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(),
o.getItemName(), o.getOrderPrice(), o.getCount()), toList())
)).entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(),
e.getKey().getName(), e.getKey().getOrderDate(), e.getKey().getOrderStatus(),
e.getKey().getAddress(), e.getValue()))
.collect(toList());
}추가적으로 DB 쪽 아닌, 코드 단에서 OrderQueryDto 형태로 매핑을 해주어 변환해주면 된다!
쿼리 한방에 원하는 기능을 할 수 있게 됨!!
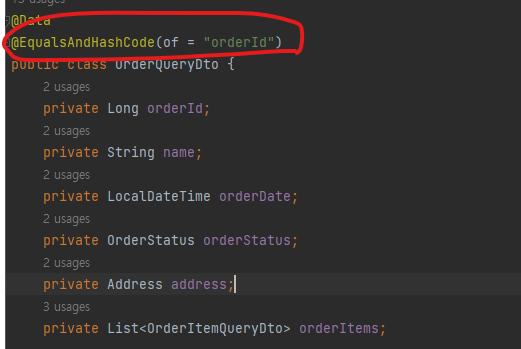
OrderQueryDto 에 해당 어노테이션을 달아줘야,
매핑이 정상 작동!!
V5 (컬렉션 조회 최적화) vs V6 (플랫데이터 최적화)
- V5는 쿼리 2번, V6는 쿼리 1번
- V6는 쿼리가 1번이지만 조인으로 인해 중복 데이터가 추가되므로, 상황에 따라 더 느릴 수도 있음!
- 애플리케이션 추가 작업이 큼! + 페이징 x
요약 정리
엔티티 조회
v1 - 엔티티 그대로 반환
큰일 난다!
엔티티 스펙이 변함에 따라 API 스펙이 변함
v2 - DTO 로 변환
이때 문제는, 성능이 안나올 때가 있음!
v3 - 페치 조인으로 쿼리수 최적화
fetch join 으로 하면, 페이징이 힘들때가 있음
v3.1 - 컬렉션 페이징과 한계돌파
@xToOne관계는 페치 조인으로 쿼리 수 최적화- 컬렉션 은 지연 로딩을 유지하되,
@BatchSize로 최적화
DTO 직접 조회
v4 - JPA에서 DTO 조회
쿼리문을 많이 날려야함.
v5 - 컬렉션 조회 최적화
in jpql 문을 활용하여 쿼리 한방으로 '다' 를 불러옴
v6 - 플랫 데이터 최적화
어플리케이션 단에서 매핑하여 원하는 형태로 사용
권장 순서
1. 엔티티 조회
* 1-1. 페치 조인 (쿼리 수 최적화)
* 1-a. 컬렉션 최적화 (페이징 여부에 따라)
2. DTO 조회
* 2-a. 최적화
3. NativeSQL or JdbcTemplate
Why?
- 엔티티의 경우 여러 기능들을 손쉽게 적용 가능
- DTO 의 경우 최적화에 코드 변경이 많이 필요하다!
개발자는 성능 최적화와 코드 복잡도 사이에서 줄타기!
보통 성능 최적화는 단순한 코드를 복잡한 코드로 몰고감
DTO 조회 방식의 선택지
각 v4, v5, v6 는 엔티티로 했다면 어노테이션으로 해결되는 문제들
- 단건 조회의 경우 V4
- 여러 주문을 한꺼번에 조회하는 경우 V5 (쿼리 수가 확 줄어듬)
- V6 의 경우 실무에서는 페이징이 많기에, 활용되기 어려움!
DTO 직접 조회를 하다보면, 거의 V5를 하게 됨!
