최적화(Optimization)란 딥러닝 모델의 학습 과정에서 모델의 가중치와 편향을 업데이트하여 '손실함수(loss function)'를 최소화하는 과정
Optimization(최적화)를 수행하는 알고리즘이 'Optimizer'
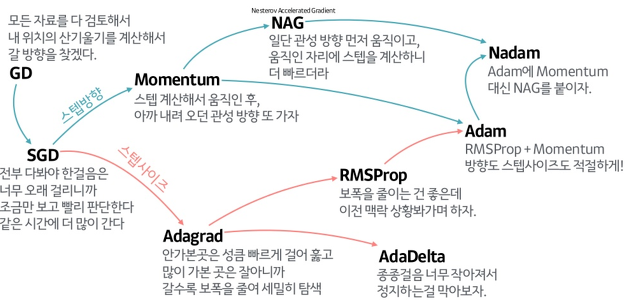
https://www.slideshare.net/yongho/ss-79607172
- 가장 기본적인 최적화 알고리즘이 경사하강법(Gradient Descent: GD)
https://pytorch.org/docs/stable/optim.html
PyTorch의 주요 최적화 알고리즘
- ' torch.optim.ooo '
- PyTorch에서 제공하는 최적화(optimizer)를 포함하는 모듈
1. Stochastic Gradient Descent (SGD)
- 경사 하강법(Gradient Descent)의 확률적인 버전
- 업데이트 스텝마다 무작위로 선택된 일부 샘플(mini-batch)에 대한 손실 함수의 그래디언트를 사용하여 모델을 업데이트
- 가장 기본적인 최적화 알고리즘으로, 각각의 파라미터에 대해 학습률(learning rate)을 곱한 값을 사용하여 가중치를 업데이트
torch.optim.SGD(params, lr=<required>, momentum=0, dampening=0, weight_decay=0, nesterov=False)- params: 최적화할 모델의 파라미터들을 전달합니다.
- lr: 필수 인수로, 학습률(learning rate)입니다.
- momentum: 모멘텀(momentum) 값으로, 기본값은 0입니다.
- dampening: 모멘텀에 적용되는 감쇠(dampening) 값으로, 기본값은 0입니다.
- weight_decay: 가중치 감소(L2 정규화)를 적용하는데 사용되는 가중치 감소 계수(weight decay coefficient)로, 기본값은 0입니다.
- nesterov: 불리언 값으로, 네스테로프 모멘텀(Nesterov Momentum)을 사용할지 여부를 결정합니다. 기본값은 False입니다.
2 Adam (Adaptive Moment Estimation)
- 현재 가장 널리 사용되는 옵티마이저, 경사 하강법(Gradient Descent) 알고리즘을 기반으로 하면서도, 모멘텀 및 학습률 감소와 같은 개선된 기능을 추가.
- 학습률을 각 파라미터마다 적응적으로 조절하는 최적화 알고리즘으로, 현재 그래디언트와 이전 그래디언트의 지수 가중 평균을 이용하여 가중치를 업데이트합니다.
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)- params: 최적화할 모델의 파라미터들을 전달합니다.
- lr: 학습률(learning rate)로, 기본값은 0.001입니다.
- betas: Adam 알고리즘에서 사용되는 두 개의 모멘텀 계수(beta1, beta2)를 튜플 형태로 전달합니다. 기본값은 (0.9, 0.999)입니다.
- eps: 분모를 보호하기 위한 작은 값(epsilon)으로, 기본값은 1e-08입니다.
- weight_decay: 가중치 감소(L2 정규화)를 적용하는데 사용되는 가중치 감소 계수(weight decay coefficient)로, 기본값은 0입니다.
- amsgrad: AMSGrad 알고리즘을 사용할지 여부를 결정하는 불리언 값으로, 기본값은 False입니다.
3. RMSprop (Root Mean Square Propagation)
- 그래디언트의 제곱값의 이동 평균을 이용하여 학습률을 조절하는 최적화 알고리즘으로, Adam과 유사한 방식으로 학습률을 조절합니다.
- 딥 러닝에서 널리 사용되는 최적화 알고리즘 중 하나로, 주로 순환 신경망(RNN)과 같이 긴 시퀀스 데이터를 다룰 때 사용
- RMSprop은 이동 평균을 사용하여 경사의 크기를 조절하기 때문에, 이전 기울기의 크기와 현재 기울기의 크기를 비교하여 기울기의 크기가 크게 변하는 경우 더 작은 학습률을 적용하여 안정적인 학습을 할 수 있습니다.
torch.optim.RMSprop(params, lr=0.01, momentum=0, alpha=0.99, eps=1e-8, centered=False, weight_decay=0, momentum_decay=0)- params (iterable): 최적화할 파라미터들의 iterable. 일반적으로 모델의 model.parameters()를 전달합니다.
- lr (float, optional, 기본값=0.01): 학습률(learning rate)로, 업데이트 스텝의 크기를 결정합니다. 높은 학습률은 빠른 학습을 가능하게 하지만, 수렴하지 않거나 발산할 수 있습니다.
- momentum (float, optional, 기본값=0): 모멘텀(momentum)을 사용하여 업데이트에 관성을 부여합니다. 값이 0이면 모멘텀을 사용하지 않습니다.
- alpha (float, optional, 기본값=0.99): RMSprop에서 이동 평균을 계산할 때 사용되는 계수로, 경사의 크기를 조절합니다. 1에 가까울수록 이동 평균이 빠르게 갱신되어 빠른 학습이 가능하지만, 불안정할 수 있습니다.
- eps (float, optional, 기본값=1e-8): 분모를 0으로 나누는 것을 방지하기 위한 작은 상수입니다.
- centered (bool, optional, 기본값=False): True로 설정하면, 중앙화된 RMSprop을 사용하여 업데이트됩니다.
- weight_decay (float, optional, 기본값=0): 가중치 감쇠(weight decay)를 적용합니다. L2 정규화를 통해 가중치를 규제합니다.
- momentum_decay (float, optional, 기본값=0): momentum decay를 적용합니다. 일반적으로 0.9 이하의 값으로 설정됩니다.
4. Adagrad (Adaptive Gradient Descent)
- 각 파라미터에 대한 학습률을 조절하는 방식으로 모델을 업데이트. 이전 그래디언트의 제곱의 누적 값을 사용하여 학습률을 조절.
- 특히 희소한 데이터셋에 적합.
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)- params: 최적화할 파라미터들의 iterable
- lr: 학습률(learning rate), 기본값은 0.01
- lr_decay: 학습률 감소율, 기본값은 0
- weight_decay: 가중치 감쇠(L2 정규화) 계수, 기본값은 0
- initial_accumulator_value: 그래디언트 제곱의 누적 값 초기화, 기본값은 0
- eps: 분모를 0으로 나누는 것을 방지하기 위한 작은 상수값, 기본값은 1e-10
5. AdamW (Adam with Weight Decay)
- Adam 옵티마이저에 가중치 감쇠(L2 정규화)를 추가한 버전으로, 가중치 감쇠(weight decay)를 통해 모델을 규제하는 효과를 얻을 수 있습니다.
- 가중치 감쇠는 모델의 가중치를 감소시킴으로써 모델의 복잡성을 제어하고, 오버피팅(overfitting)을 완화
torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)- params: 최적화할 파라미터들의 iterable
- lr: 학습률(learning rate), 기본값은 0.001
- betas: 감마 값들 (beta1, beta2)로 이루어진 튜플, 기본값은 (0.9, 0.999)
- eps: 분모를 0으로 나누는 것을 방지하기 위한 작은 상수값, 기본값은 1e-08
- weight_decay: 가중치 감쇠(L2 정규화) 계수, 기본값은 0
- amsgrad: AMSGrad 알고리즘을 사용할지 여부, 기본값은 False

안녕하세요 반갑습니다. 공부한 내용들을 기록하고 있습니다.