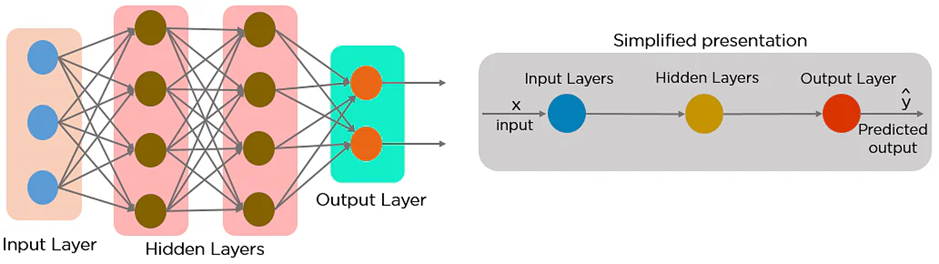
RNN(Recurrent Neural Network, 순환신경망)
RNN층은 기본적인 신경망의 은닉층(hidden layer)과 유사하다고 볼 수 있음.
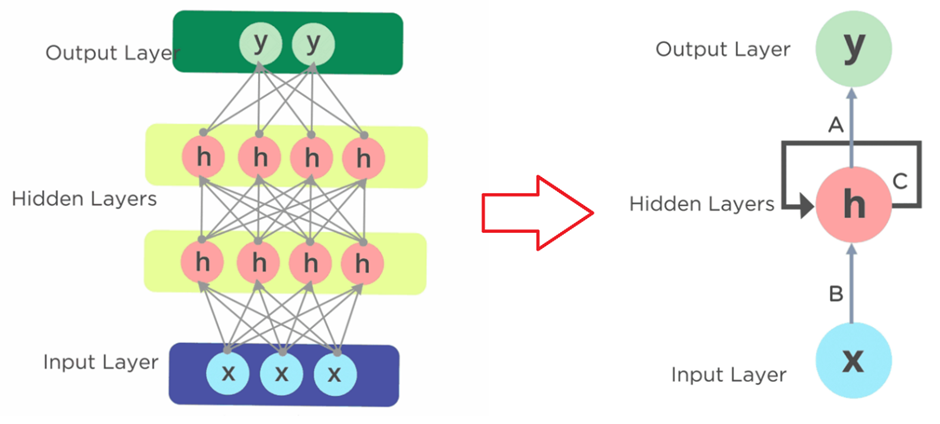
차이점은 기본적인 은닉층엔 입력값이 한 번만 적용. 반면, RNN층은 하나의 RNN층이 순차적으로 입력되는 데이터에 반복(순환) 적용.
- Feed-forward neural network, the decisions are based on the current input. It doesn’t memorize the past data
- RNN can handle sequential data, accepting the current input data, and previously received inputs. RNNs can memorize previous inputs due to their internal memory.
RNN은 순차적으로 입력되는 데이터를 분석하기에 적합한 알고리즘.
- 즉, Sequential Data에 적합.
- Sequential Data는 순서를 갖고 연속적으로 나열되어 있는 데이터 형태
예) document는 sentence들의 Sequential Data.
예) sentence는 word들의 Sequential Data.
- 텍스트 데이터뿐 아니라 동영상(이미지가 연속으로 있는), 음악 등에도 적용.
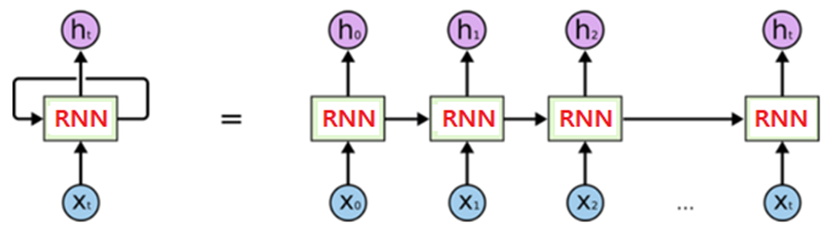
RNN 특징
현재 단계에서 입력되는 data를 처리하기 위해, 전 단계에서 입력된 데이터들의 정보를 사용.
- 텍스트 데이터에선 주어진 단어들을 기반으로 다음에 출현할 확률이 높은 단어가 무엇인지 예측.
- hi, my name is ooo nice to meet ___ - 특정 단어를 예측하기 위해 목표한 단어 이전 단어들 뿐 아니라, 이후의 단어 정보까지 확용 가능(bidirectional)
- hi, my name __ ooo nice to meet you
1) RNNs read input sequesce one by one
- 한 단어씩 input
2) RNNs maintain an internal state, representing the semantics of input sequence processedso far
- 작동한 시점까지 input된 정보가 internal state(RNN의 핵심, hidden state라고도 함)에 들어가 있는 것.
> step1. my > step2. my name > step3. my name is ....
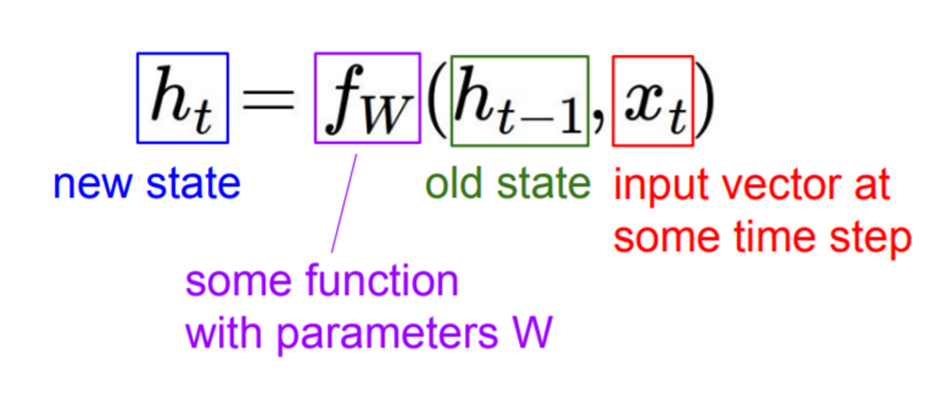
- old state를 통해 new state 계산
- 첫번째 hidden state는 ‘random’ 값을 주기도, 0을 주기도 함(아직 input이 없었으니).
- some function with parameters W는 항상 같은 값을 사용한다.
Why?
텍스트 데이터가 RNN에 입력되는 방식
예, my name is jaegyeong
-
다른 신경망과 같이 RNN에 입력되는 단어들 또한 저차원 벡터(dense vector)로 변환한 뒤 입력.
-
임베딩된 각 단어들의 정보가 순차적으로 RNN층에 입력.//
- 'my'의 벡터 정보(예, [1, 2, 0, 0 ... 2]가 RNN에 입력.
- 만약 예시 문장인 my name is jaegyeong의 단어들이 각각 10차원 벡터로 표현되었다면, input layer의 node 수는 10개.
- 여기서 input layer에 존재하는 10개의 node에는 my의 백터가 갖는 각각의 원소값이 들어가는 것
- RNN층(은닉층 중 하나라고 생각하면 편함)의 node 갯수는 사용자가 설정. -
RNN층의 n개의 node에서 출력된 각각의 값들은 다음 층(hidden layer 또는 output layer에 바로 전달되는 것이 아님. name, is, jaegyeong를 순차적으로 모두 입력 받고 이들에 대한 결과값 하나만 다음 층으로 보냄.
- 이때, 두번째 단어인 'name'의 벡터 정보는 'my'처럼 RNN층에 벡터 값이 그대로 들어가지 않음.
'my'에 대한 RNN층의 출력값이 'name'의 벡터 정보와 함께 RNN층의 입력값으로 들어감.
- 이 과정을 통해 이전 단어의 정보를 계속 저장(주어진 문장에 포함되어 있는 모든 단어를 이렇게 수행)
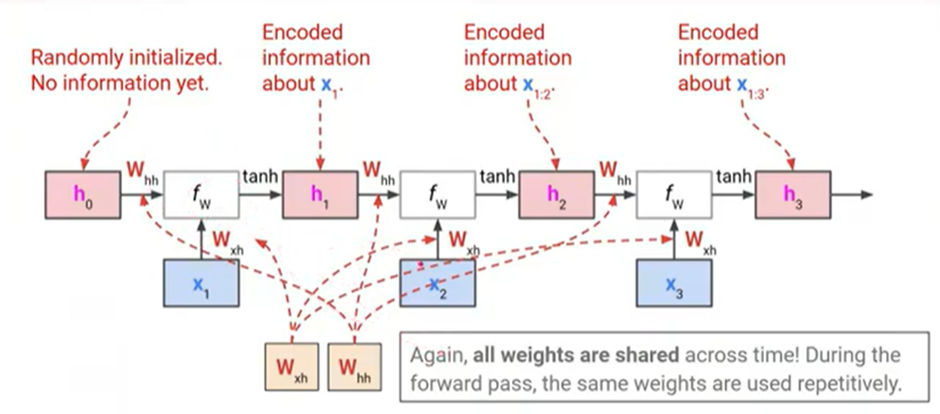
- h3에는 3 단어(x1,x2,x3)에 대한 정보가 모두 담겨있는 것.
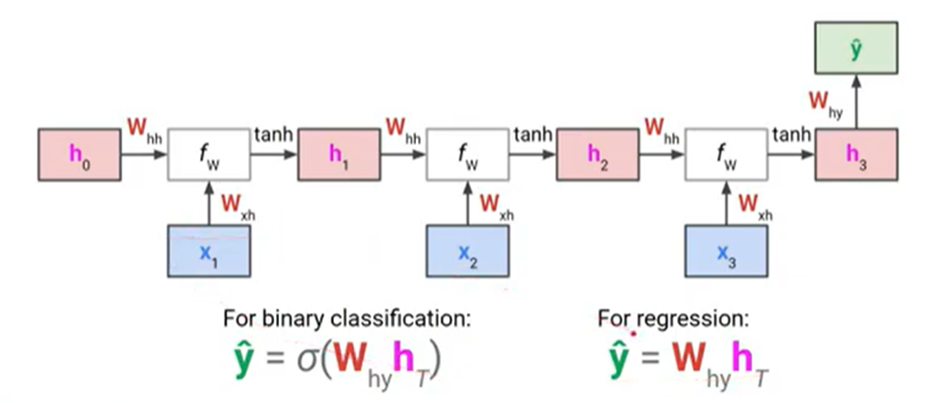
- 이렇게 나온 ‘실제값(Y) – 예측값(Y헷)’을 통해, loss function 계산(back propagation) -> parameter(W) 업데이트.
최종적으로 RNN층에서 출력된 하나의 값만을 RNN층 이후의 layer로 전달.
1) 마지막 단어인 jaegyeong에 들어가고 나온 값(그림상, ht만을 다음 layer로 넘길 수도 있고,
- ht만 다음 layer로 전달하더라고, ht 이전 단어의 정보도 저장되어 있는 것.
- Sentiment analysis에서는 이 방법을 사용.
2) 각 단어에서 나온 값을 모두(그림상, h0, h1, h2 ... ht) 보낼 수도 있음.
- 빈칸 단어 예측이 필요한 Language model에서는 이 방법을 사용.
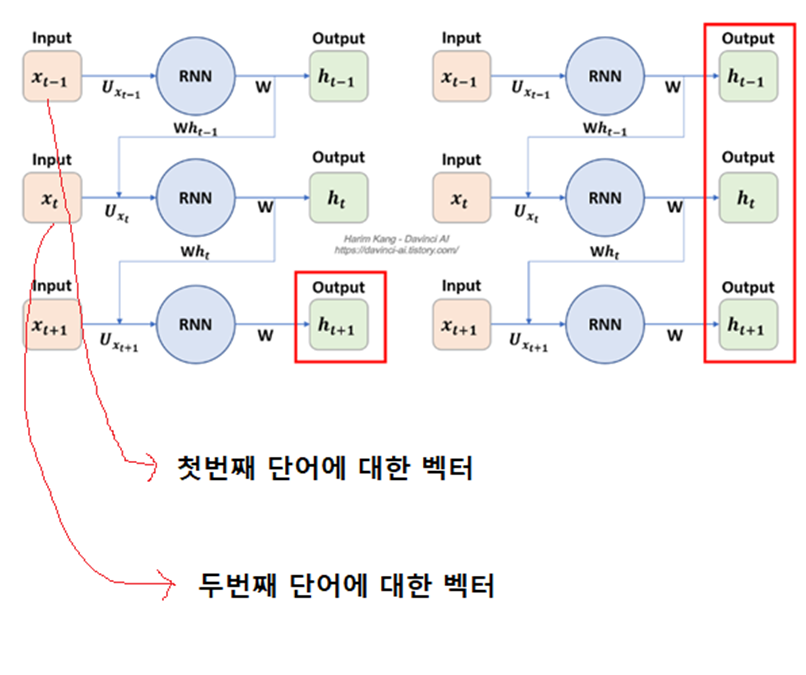
RNN을 활용한 감성분석이 정확도가 높은 이유.
주어진 문장을 바탕으로 긍/부정을 판단함에 있어, 단순히 특정 감성어의 등장만으로는 정확한 분류가 되지 않을 수 있기 때문.
예) It is not good
이때, target 단어의 앞/뒤 단어를 RNN을 통해 함께 파악해주면, 정확도가 더 높아지는 것.
추가 one-to-many의 관계도 있음(input이 아닌 output이 sequential한 경우).
예) input으로 사진 1장 -> output으로 사진과 관련된 문장(단어들의 sequence)
