"마스크팩" 상품을 검색해보자 !
import os
import sys
import urllib.request
client_id = ""
client_secret = ""
encText = urllib.parse.quote("마스크팩")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)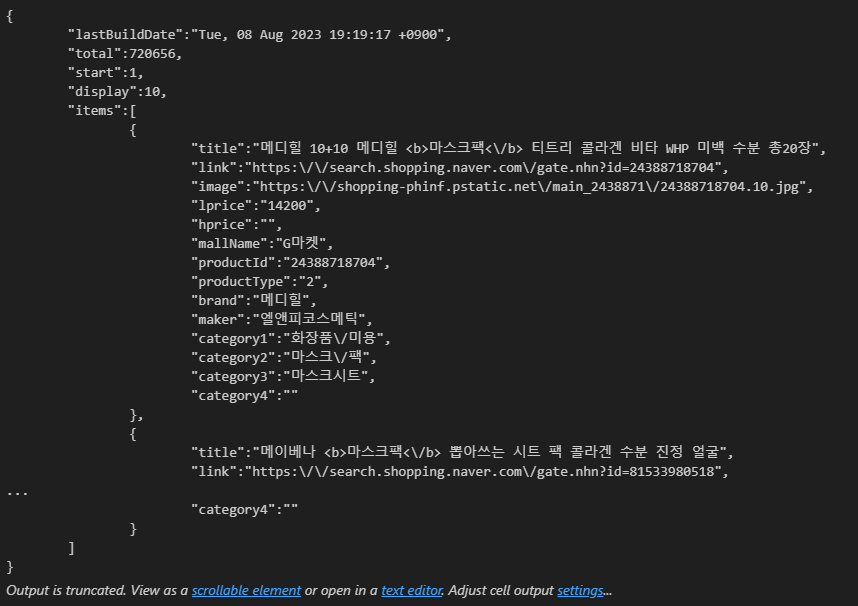
1. gen_search_url( )
- 먼저 검색해야 할 URL을 만든다
- 아래 코드 참고해서 작성
url = "https://openapi.naver.com/v1/search/cafearticle?query=" + encText # json 결과
# api_node = 쇼핑몰 / 블로그 / 카페 / 등등
# search_text = 검색어
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_dispgen_search_url("shop", "TEST", 10, 3)
잘 출력되었다 !
2. get_result_onepage( )
import json
import datetime
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urllib.request.urlopen(request)
# 현재 시간이 찍힘
print("[%s] Url Request Success" % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))url = gen_search_url("shop", "마스크팩", 1, 5)
one_result = get_result_onpage(url)
- one_result 은 dictionary 형태이다
one_result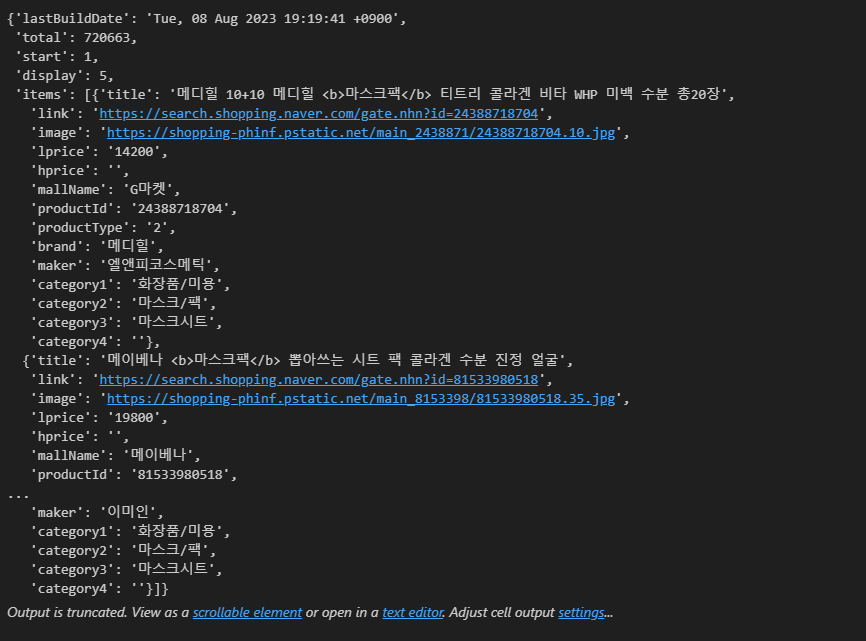
- key 값인 'items'를 검색하니 list 형태로 총 5개의 데이터가 담겨 있다.
- 즉 list 형태이기 때문에 필요한 정보를 얻기 위해서는 index로 접근해야 한다.
one_result["items"]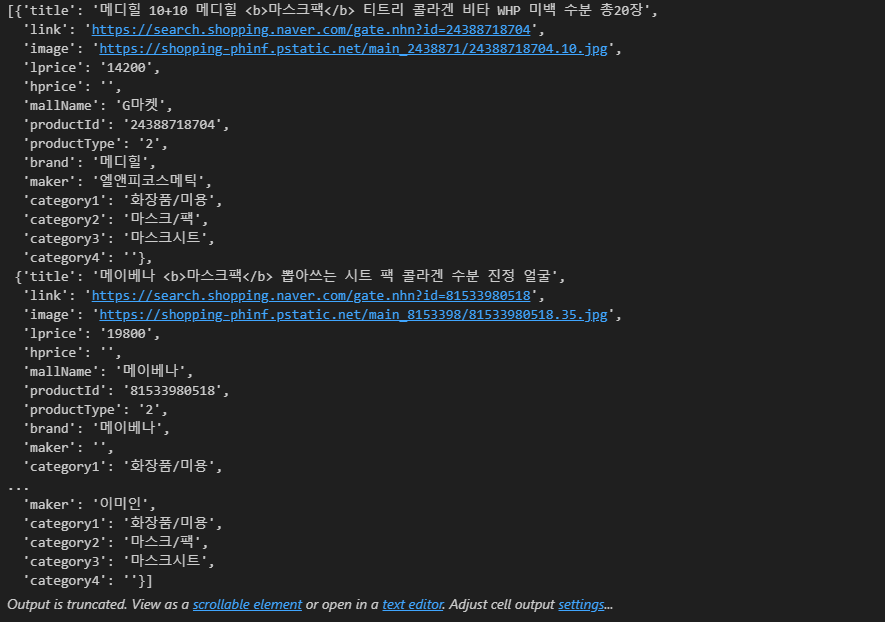
- 한 개의 dictionary 데이터 출력
one_result["items"][0]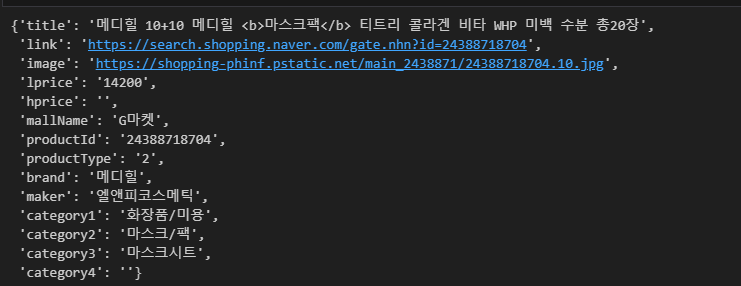
- 다시 한 번 key 값인 'title'로 데이터 출력
one_result["items"][0]["title"]
- 이번엔 key 값인 'link' 출력
one_result["items"][0]["link"]
- 가격 출력
one_result["items"][0]["lprice"]
- 쇼핑몰명 출력
one_result["items"][0]["mallName"]
3. get_fields( )
- 이제 필요한 정보들을 dataframe으로 정리하자
import pandas as pd
def get_fields(json_data):
title = [each["title"] for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mall_name = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title": title,
"link": link,
"lprice": lprice,
"mall": mall_name,
}, columns=["title", "lprice", "link", "mall"])
return result_pd
get_fields(one_result)
그런데 title 출력 결과에 b 태그가 있다. (검색어를 강조하는 태그)
4. delete_tag( )
- 해당 b 태그를 없애는 함수를 작성
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>", "")
return input_str - title 에 함수 적용
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mall_name = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title": title,
"link": link,
"lprice": lprice,
"mall": mall_name,
}, columns=["title", "lprice", "link", "mall"])
return result_pd
get_fields(one_result)
이 때까지의 내용을 정리하면,
1. URL을 만들어내고 2. 그 response를 받아서 3. dataframe 으로 정리하였다.
url = gen_search_url("shop", "마스크팩", 1, 5)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
pd_result
5. actMain( )
- 이제 모든 데이터를 모아야 한다.
result_mol = []
for n in range(1, 1000, 100):
url = gen_search_url("shop", "마스크팩", n, 100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
- result_mol 은 list 형이다 (그 안의 각각의 요소들이 dataframe으로 잡혀있는 것)
- 따라서 pandas dataframe으로 바꾸기 위해서 concat 명령 실행
result_mol = pd.concat(result_mol)
result_mol.info()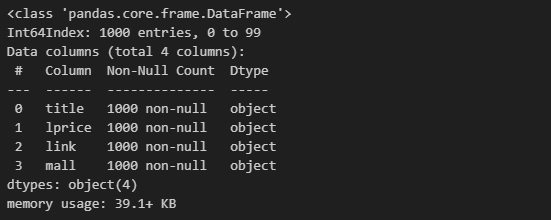
총 1000개의 data가 들어왔으므로 데이터가 잘 확보되었다.
그런데, 데이터는 1000개인데 index는 0~99이므로 index 수정이 필요해보인다.
result_mol.reset_index(drop=True, inplace=True)
result_mol.info()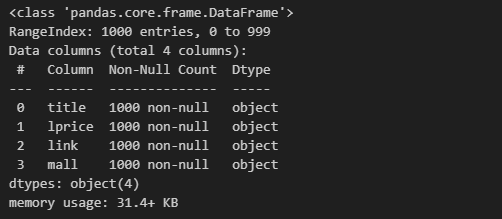
result_mol.tail()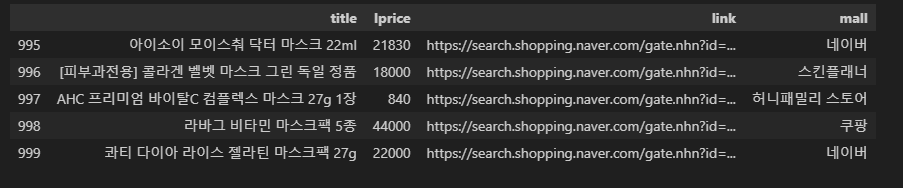
또한, 가격 lprice가 object 형이므로 float형으로 변환시켜야 한다.
result_mol["lprice"] = result_mol["lprice"].astype("float")
result_mol.info()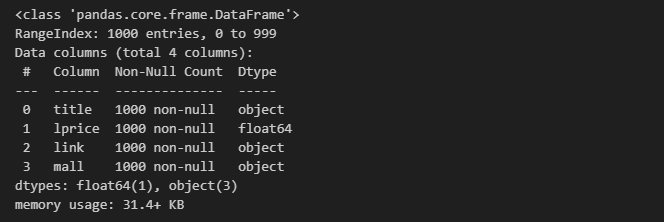
6. 시각화
plt.figure(figsize=(15, 6))
sns.countplot(
x = result_mol["mall"],
data=result_mol,
palette="RdYlGn",
order=result_mol["mall"].value_counts().index
)
# x 축이 세워짐
plt.xlim([0, 9])
plt.xticks(rotation=90)
plt.show()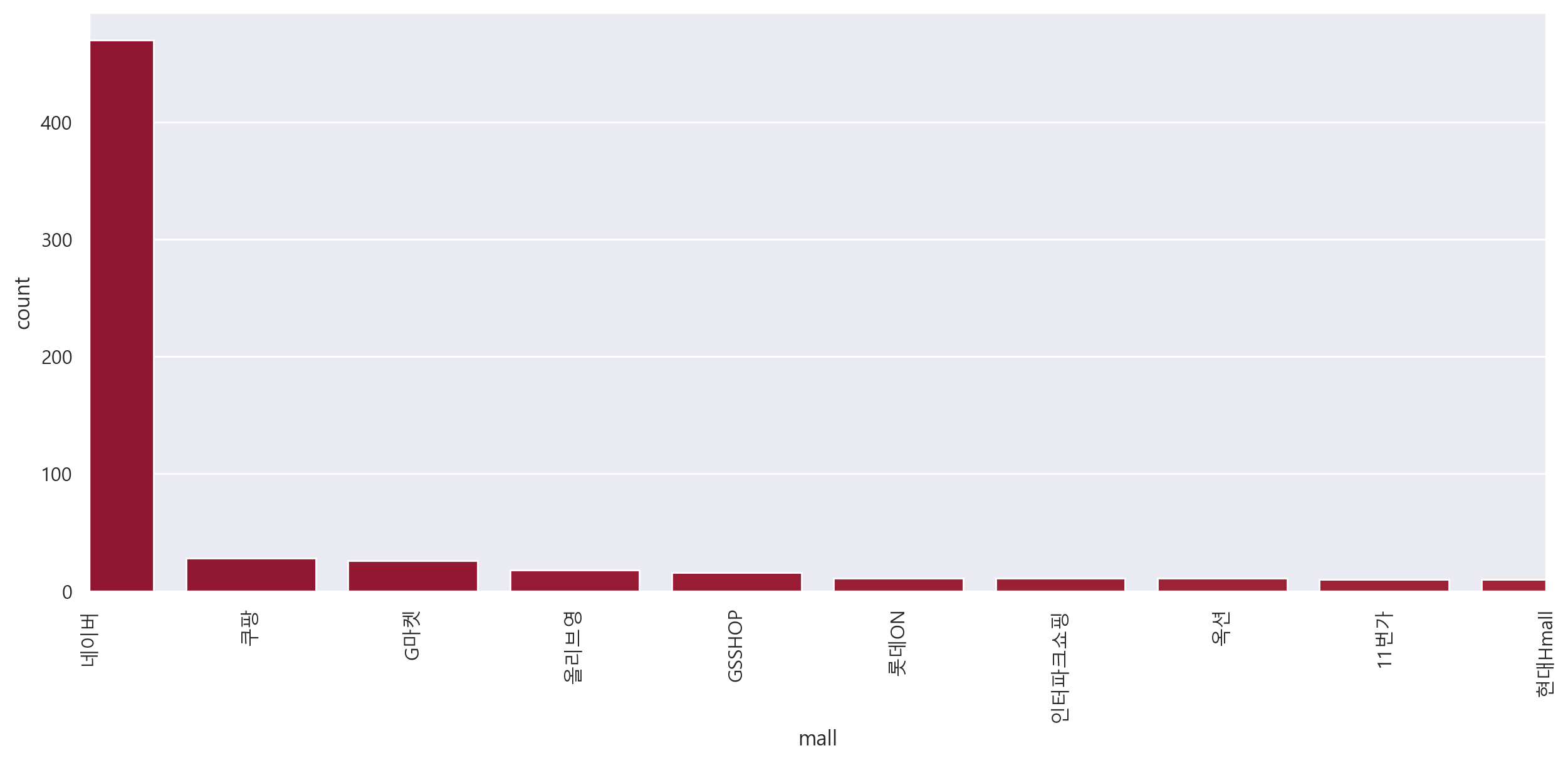
마스크팩 검색 결과, 쇼핑몰 중 네이버 비율이 압도적으로 높은 것을 확인

데이터 관련 학습 일지