Kafka
웹사이트, 어플리케이션, 센서 등에 취합한 데이터를 스트림 파이프라인을 통해 실시간으로 관리하고 보내기 위한 분산 이벤트 스트리밍 플랫폼으로 데이터 생산자와 소비자 사이의 중재자 역할을 함으로써 데이터의 전송 제어, 처리, 관리 역할을 한다.
Kafka를 사용하는 이유
- before
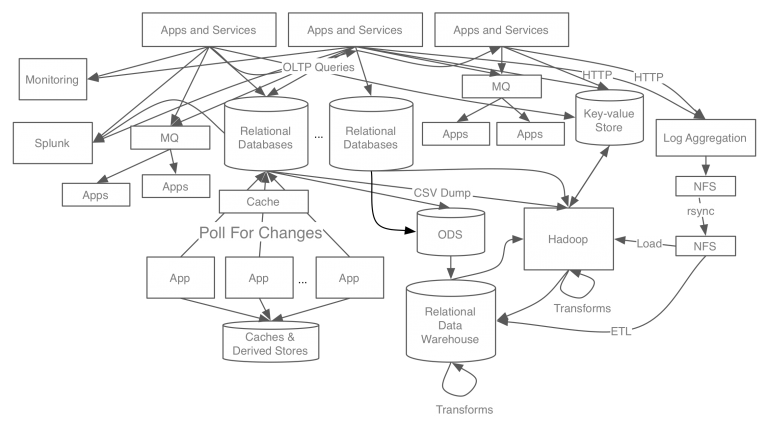
- after
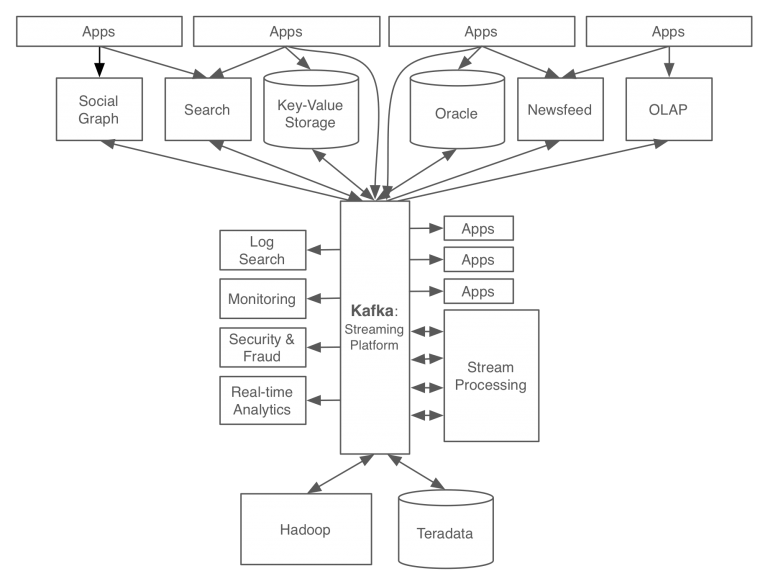
카프카를 사용함으로써 모든 데이터와 이벤트의 흐름을 중앙에서 관리할 수 있게 되었다.
카프카의 기본 구성 요소
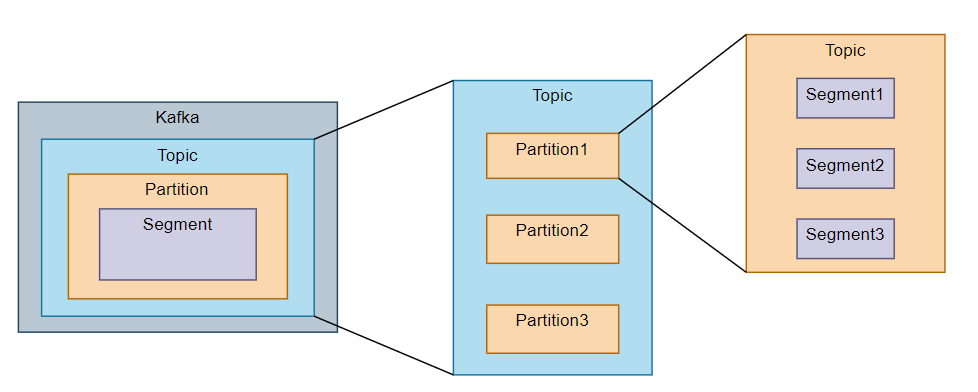
Cluster- 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 집합Producer- 데이터를 만들어내어 전달하는 전달자Consumer- Producer 에서 전달한 데이터를 브로커에 요청하여 메시지를 소비Broker- 생산자와 소비자 사이의 중재자 역할Topic- 메시지를 구분하기 위한 카테고리Partition- 토픽을 구성하는 데이터 저장소로서 수평으로 확장가능 나뉜 파티션 수 만큼 컨슈머를 연결할 수 있다.Segment- 메시지가 브로커의 로컬 디스크에 저장되는 파일Replication- 각 메시지들을 여러 개로 복제해서 카프카 클러스터 내에 있는 브로커들에게 분산시키는것, 복제되는 것은 토픽의 파티션
리더, 팔로워
원본 파티션을 리더, 리플리케이션 된 파티션을 팔로워 라고 부른다.
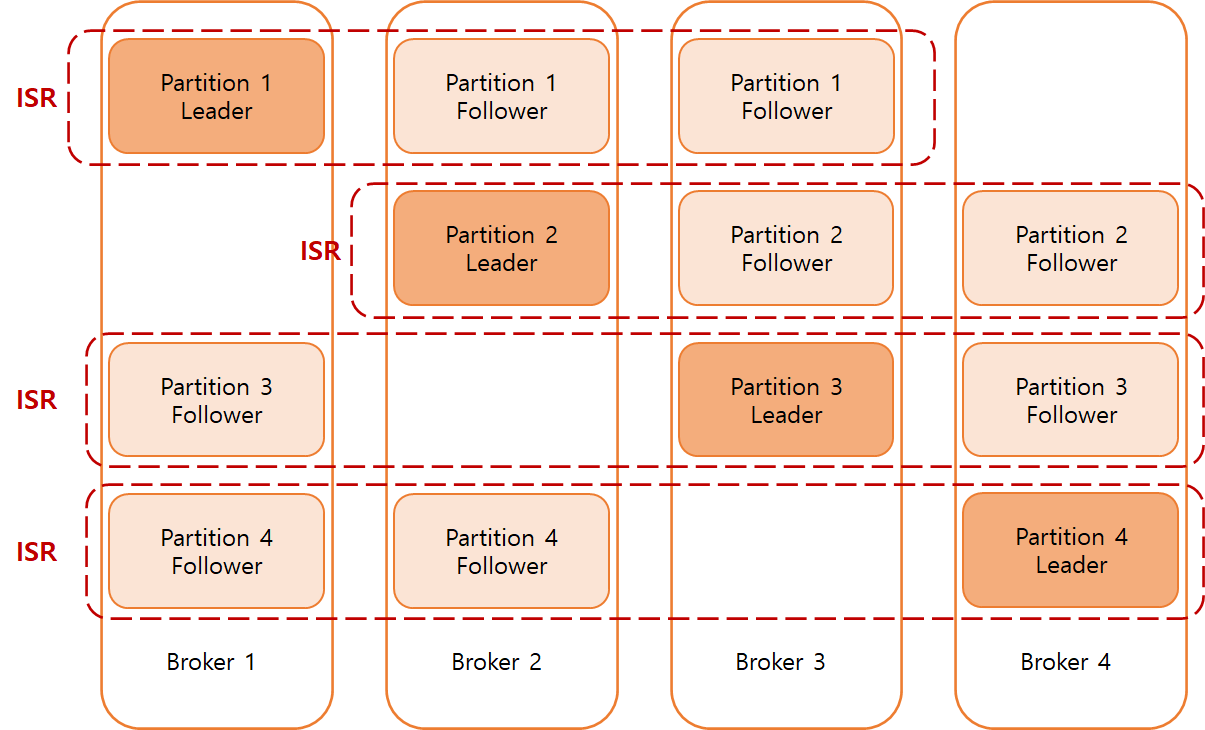
( 참고 : https://ddimtech.tistory.com/5)
리더가 제 역할을 못하는 상태가 되면 팔로워가 리더로 승격한다(주키퍼 에서 관리). ISR(In Sync Replica) 라는 그룹으로 묶여있으며 리스트는 주키퍼에 저장된다.
ack
프로듀서의 옵션으로 파티션의 레플리케이션 과 관련있는 설정
ack = 0- 프로듀서가 데이터를 전송하고 응답값을 받지않음, 속도가 빠르지만 데이터 유실의 가능성이 있다.ack = 1- 프로듀서가 응답값을 받는다. 파티션에 복제가 잘 되었는지에 대한 응답값은 받지 않는다.ack = all- 프로듀서가 응답값을 받으며 팔로워 파티션에 복제가 잘 되었는지에 대한 응답도 받는다, 속도가 느리다
주키퍼
kafka의 메타데이터(metadata) 관리 및 브로커의 정상상태 점검(health check) 을 담당(분산 애플리케이션에서 코디네이터 역할, 브로커 노드 관리, 토픽 관리 ,컨트롤러 관리 등)
사용해보기
간단하게
Config
#application.properties
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.bootstrap-servers=localhost:9092
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.group-id=consumerGroup
spring.kafka.consumer.auto-offset-reset=earliestconsumer.group-id- Consumer 들을 그룹화 하고 관리하기 위해 사용consumer.auto-offset-reset- Consumer가 처음으로 그룹에 가입하거나 offset을 잃어버렸을 경우 동작, earliest - 가장 이른 메시지부터 처리, latest - 가장 최신 메시지 부터 처리bootstrap-servers- 브로커 서버의 호스트 및 포트 정보를 지정
Producer
@Slf4j
@Service
@RequiredArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, String> template;
public void sendMessage(String message) {
template.send("topic1",message);
}
}KafkaTemplate- 메세지를 편리하게 생성하기 위해 제공하는 인터페이스
Consumer
@Service
@Slf4j
@RequiredArgsConstructor
public class KafkaConsumer {
@KafkaListener(topics = "topic1", groupId = "consumerGroup")
public void listen(String message) {
log.info("receive message = {}", message);
}
}@KafkaListener- 카프카 메시지를 처리하는 메서드를 정의할 수 있도록 하는 애노테이션
자세하게
Config
@Bean
public KafkaAdmin kafkaAdmin() {
HashMap<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
return new KafkaAdmin(configs);
}KafkaAdmin- 카프카 클러스터를 관리하고 관리 작업을 수행하기 위한 도구
Topic 생성
@Bean
public NewTopic personTopic(){
return new NewTopic("person", 1, (short) 1);
}NewTopic(String name, int numPartitions, short replicationFactor)- 새로운 토픽을 정의하고 생성하는데 사용, numPartitions - 해당 토픽이 가질 파티션의 수, replicationFactor - 리플리케이션 의 수
Producer 생성
@Bean
public ProducerFactory<String, PostgrePerson> producerFactory() {
HashMap<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, PostgrePerson> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
ProducerFactory- Producer를 생성하고 구성하기 위한 팩토리 인터페이스로 여러 Producer 인스턴스를 생성하고 관리한다.
Spring Kafka를 사용하는 경우, ProducerFactory를 구현하고 설정을 통해 KafkaProducer를 생성 및 구성한다.
Consumer 생성
@Bean
public ConsumerFactory<String, PostgrePerson> consumerFactory() {
HashMap<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, "consumerGroup");
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
configProps.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
configProps.put(JsonDeserializer.VALUE_DEFAULT_TYPE, PostgrePerson.class.getName());
return new DefaultKafkaConsumerFactory<>(configProps);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, PostgrePerson> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, PostgrePerson> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// factory.setConcurrency(3);
return factory;
}ConsumerFactory- Consumer를 생성하고 구성하기 위한 팩토리 인터페이스ConcurrentKafkaListenerContainerFactory- 카프카 리스너를 생성하는데 사용, 이 리스너를 통해 메시지를 비동기적으로 소비하고 처리 할 수 있다.factory.setConcurrency()- 병렬로 실행할 스레드 수 설정
Controller
@PostMapping("pub")
public CompletableFuture<String> pub(@ModelAttribute("person") PostgrePerson person) {
CompletableFuture<SendResult<String, PostgrePerson>> future = kafkaTemplate.send(personTopic.name(), person);
return future.thenApply(SendResult -> {
//성공시 실행
return "redirect:/kafka";
}).exceptionally(exception -> {
//실패시 실행
return "redirect:/kafka";
});
}CompletableFuture- Java에서 비동기적인 작업을 처리하고 다양한 비동기 작업을 조합하고 관리하기 위한 클래스
Service
@KafkaListener(topics = "#{personTopic.name}", groupId = "consumerGroup")
public void consumer(@Payload PostgrePerson person , @Header(KafkaHeaders.RECEIVED_PARTITION) String partition) {
log.info("kafka receive message = {} partition = {}",partition,person);
repository.save(person);
}