Pod 업데이트 방법
- ReCreate
업데이트할 pod를 한 번에 교체하는 방식
버전A에서 버전B로 업데이트 할 때 버전 A를 종료하고 버전 B를 실행
down time(pod의 교체 과정에서 서비스 중단 시간) 발생- Rolling Update
업데이트 시 새 버전을 배포하면서 이전 버전을 하나씩 줄여나가는 방식
기존 버전과 새 버전의 pod가 공존할 수 있는 단점
하지만 서비스가 끊기지 않아 무중단 업데이트 가능
Replica Set

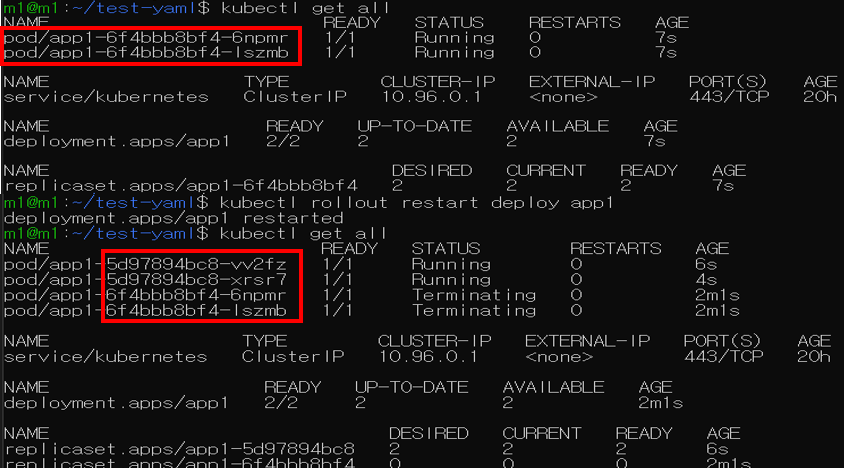
Deployment vs Replica Set
Deployment 업데이트 방식의 기본값은 Rolling update
→ 다른 업데이트 방식 설정은 yaml파일에 작성
아래의 Deployment.yaml과 ReplicaSet.yaml을 생성한 후 두 pod의 동작 방식의 차이 확인
1. 각각 오류가 있는 이미지로 pod 생성
2. yaml파일을 정상적으로 수정한 후 오류가 없는 이미지로 pod 생성
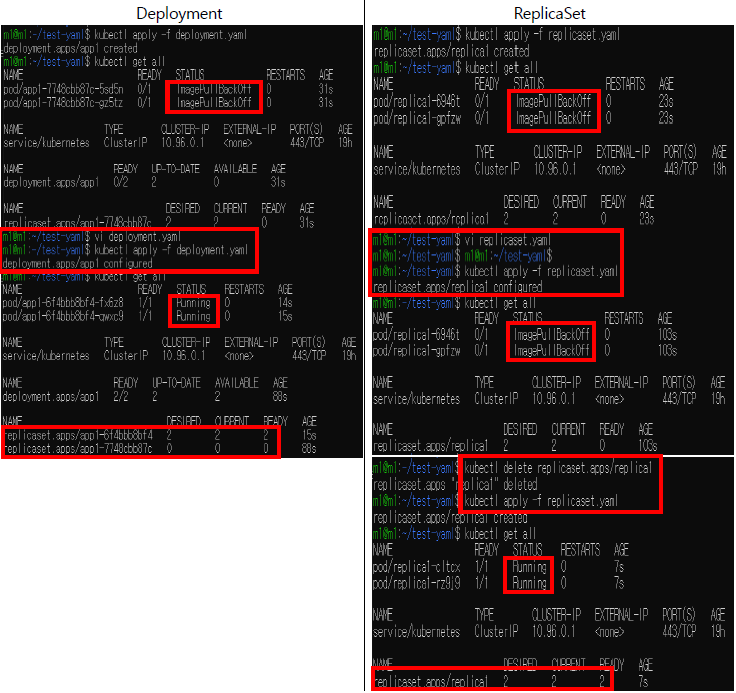
Deployment, ReplicaSet 배포
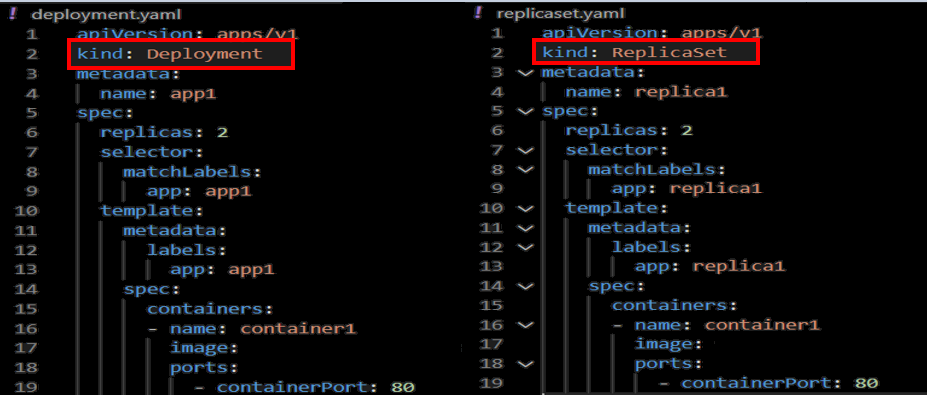
아래와 같이 pod가 생성된 것을 확인
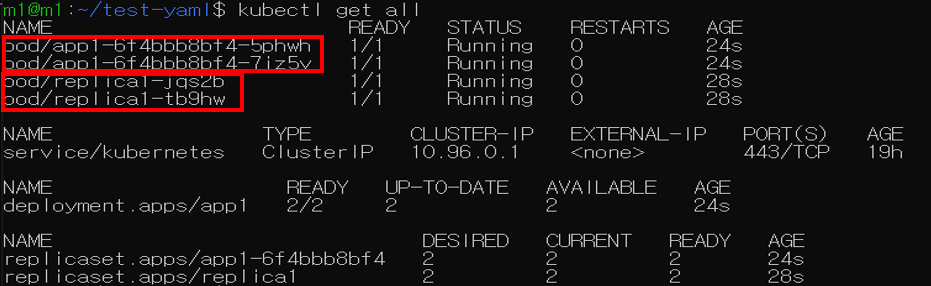
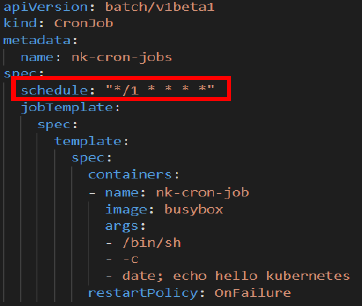
Job
서버 및 애플리케이션 관리 등을 목적을 단 한 번의 반복된 형태의 작업을 실행
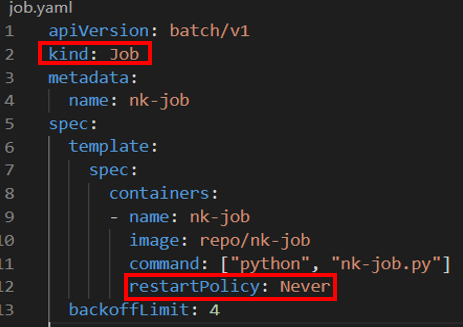
Job 배포는 오류 발생시 로그를 남기지 않고 바로 소멸 되어 오류 추적이 힘들다
restartPolicy 옵션에 OnFailure로 설정하기에는 pod를 재생성해 ETL과 같은 큰 작업에 있어 비효율적
<해결 방법>

Cronjob
StatefulSet
ReplicaSet의 특징
- Pod 이름의 불규칙한 이름 생성 알고리즘
- 순서 없는 pod 생성
- Persistence Volume과 pod 1:1 한계
이러한 특징은 데이터베이스 서버와 같은 데이터의 저장이 영구적이어야 하는 작업에 적합하지 않음
StatefulSet은 기본적으로 pod를 순차적으로 기동하며 삭제도 순차적으로 삭제
Pod 이름을 생성하는 알고리즘이 규칙적 → Pod가 삭제 되어도 Volume은 유지
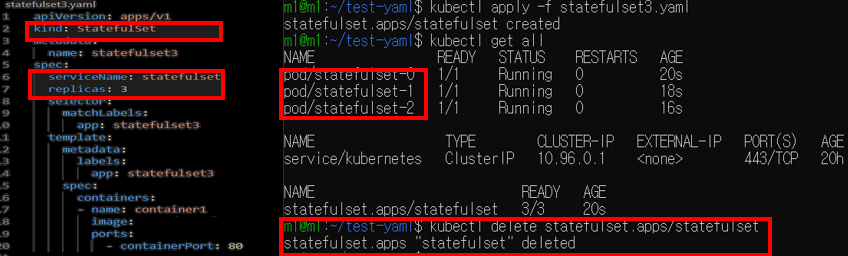
아래와 같이 동일한 이름의 pod가 생성된 것을 확인
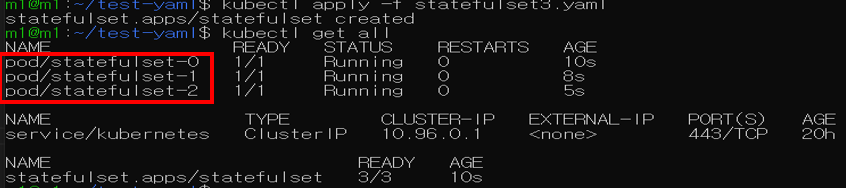
StatefulSet 완벽한 삭제 명령어
grace=$(kubectl get pods <pod> --template '{{.spec.terminationGracePeriodSeconds}}')
kubectl delete statefulset -l app=myapp
sleep $grace
kubectl delete pvc -l app=myapp
kubectl rollout restart deploy deploy-replica1StatefulSet 강제 삭제 명령어
kubectl delete pods <pod> --grace-period=0 –force
# 명령 후에도 Pod이 켜져 있는 Unknown상태일 경우 다음 명령을 사용하여 클러스터에서 Pod 제거
kubectl patch pod <pod> -p '{"metadata":{"finalizers":null}}'DeamonSet
클러스터 전체 노드에 pod를 올릴 때 사용하는 컨트롤러
로그 수집 혹은 모니터링용으로 사용
taint와 toleration 옵션을 사용하면 특정 노드에만 선택해서 실행 가능
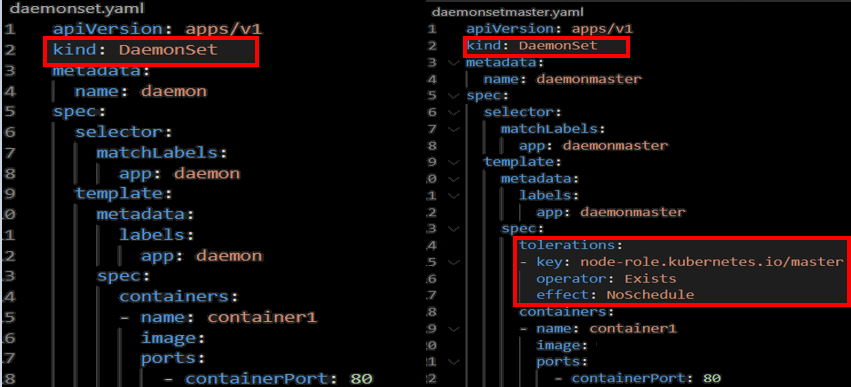
- toleration : taint를 무시
taint : 노드 마다 설정 가능 → 설정한 노드에는 pod가 스케줄 되지 않음
기본적으로 Master노드에는 pod가 스케줄 되지 않게 taint가 걸려있습니다.
kubectl taint node {nodename} {key}={value}:{option}
# Taint 해제 명령어
kubectl taint nodes {해제할 노드 이름} node-role.kubernetes.io/master-
# Taint 복구 명령어
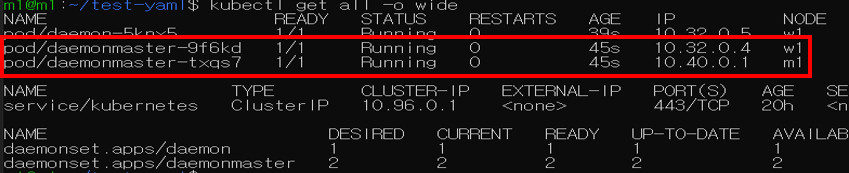
kubectl taint nodes {설정할 노드 이름} node-role.kubernetes.io=master:NoSchedule아래와 같이 Master노드에 pod가 생성된 것을 확인
Can Do It
brb
