

LG Software Developer Conference 2일차 내용 일부 정리
1. S/W의 힘으로 세계 최고 초전도 화질 달성
LG전자 채명석 책임 연구원
SW 개발자로써 HW영역의 화질 분야를 접근하는 과정
초전도 화질이란?
연구원 본인이 만든 용어로, "저항을 0으로 만든다"의 개념에 입각하여 비디오 월의 멀티 비전 스크린에서도 눈으로 볼떄 하나의 디스플레이로 보는 것과 같이 거부감이 전혀 느껴지지지 않는, 시각 인지의 저항 없는 균일한 화면의 상태 를 뜻 한다.
비디오 월은 다양한 모니터 혹은 패널들의 조합으로 제작하는 만큼 각각의 통일성이 무척 중요하다.
-
LCD/OLED 사이니지 비디오 월 : 모니터와 같은 기기들을 이어붙여 하나의 화면처럼 동작하도록 한다. 다만 테두리들의 존재로 검은선과 같이 나타나여 합일성이 좀 떨어진다는 단점이 있다.
-
LED 사이니지 비디오월 : 패널 위에 LED를 이용하기 때문에 패널들간의 통일성은 무척 뛰어나나, LED 패널 내의 LED간의 단차로 인해서 밝은 부분, 어두운 부분이 존재하여 이슈가 존재한다.
LED 사이니지 비디오 월의 문제를 해결하기 위하여 이해야하는 디스플레이 성능지표에서의 성능지표는 위 블로그에서 아주 설명이 잘 되어있다.
사람의 눈은 하나의 색을 볼때는 이후의 색과 차이를 크게 못느끼지만, 특정색과 비교를 하게 되면 그 차이를 쉽게 찾아낸다. 따라서 LED 패널에서의 미세한 차이 (RGB 1정도)도 눈에 크게 차이 나는 것처럼 보이기 때문에 중요한 해결 과제이다. 경계면에 그라데이션을 적용하면 해결되기도 한다.
LED Signage Calibration
Pixel Calibration
광원 각각 (UHD Screen : 3940 x 2160 x 3 = 24,883,200 개의 광원) 을 Calibration을 한다. 특히나 광원마다 온도의 변화로 밝기 또한 변한다. 심지어 LED에서의 발열로 인해, 화면 얼룩현상은 더 심화될 수 있다.
아쉽게도 배경지식에 대한 설명이....길어서 세션 시간을 넘겨 해결방안을 못들었다..(실화냐)
2. ThinQ 데이터 큐레이션 & 개인화 시스템
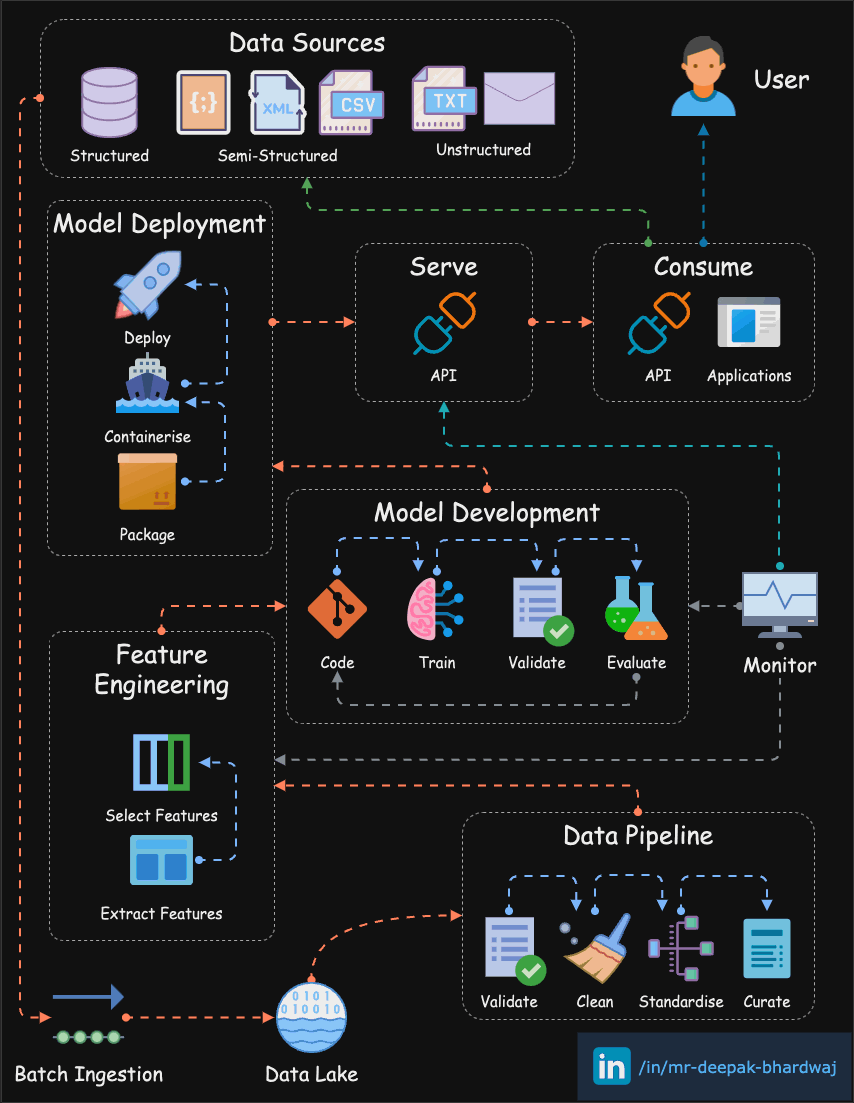
개인화 서비스를 위해서는 정말 많은 요소들이 필요하다. Data Engineering부터 MLops, Data Science 등 거의 대부분 Data 비즈니스의 Engineering 과정이 필요하다.
여기에서 드는 기술적인 비용과 부하도 대단하지만 실제 문제는 따로 존재한다.
바로 사용가능한 데이터의 양의 부족이다. 실제 ThinQ에서의 데이터는 월단위로 TB단위로 쌓이지만, 본질적인 고민을 했을 때 우리는 어쩌면 MB단위의 데이터만 필요하지만 실제 사용가능한 좋은 데이터는 없는 것이 아닌가 라고 생각한다.
달성해야하는 과제
- 고품질, 고활용성, 표준화 된 Curation Data 확보
- 비용 효율적인 데이터 생성
- 고객 Engagement 높이기 위한 개인화 시스템 확보
- 룰 기반 탈피, 빠르고 효과적인 개인화 모델 구축
ThinQ 데이터 큐레이션
현재 사내에서 다루는 데이터는 ThinQ 사용 Data등 다양한 데이터가 있지만, 그 안에서 압도적인 양을 차지하는 데이터는 기기 데이터이다.
현재 LG전자에서는 많은 제품을 제작하지만, 같은 제품군에서도 많은 모델이 존재한다. 다양한 모델이 존재하고 기능이 다른 만큼 발생되는 데이터가 무척 방대하다.
기존에는 데이터를 Case by Case로 데이터를 한정 활용했다. 기기의 Raw Data를 필요에 따라 Parsing을 수행하고 이용하였다. 따라서 중복적으로 데이터를 각 부문에서 가공하고 이용하는 부문에서 효율성이 많이 떨어졌다.
데이터 큐레이션이란
흔히들 사용되는 Data Engineering 프로세스인 것 같다. + 도메인지식
데이터를 효율적으로 사용하기 위해, 수집/정리/가공을 기반으로 목적성 있는 표준화 된 데이터를 만드는 것이다. 파싱을 통해 제품의 Raw데이터를 해석하고, 전처리를 통해 제품별로 표준화를 수행한다. 이런 데이터를 지수화하여 Insight를 반영하고 모든 구성원들이 접근하여 직접 활용 할 수 있는 수준까지 만드는 과정을 거친다.
- L0 Data : Raw (제품 본연 데이터)
- L1 Data : Parsed
- CL2 Data : Preprocessed (사영성 기반 분석 나응, 데이터 활용의 전처리 Load 절감)
- CL3 Data : Profitting Data (Insight 반영한 지수화 데이터, 마이크로 새그멘테이션 직접활용)
이러한 과정에서 얻을 수 있는 가장 큰 이득은, TB규모의 데이터를 가공을 거침에 따라 GB 심지어는 MB 수준까지 데이터의 규모를 감소시킬 수 있다는 점이다.
대용량 데이터 처리를 위한 Solution
Spark on EKS 도입을 활용하여 비용적인 부분을 해결하기 위해 노력하고 있다. 비용 효율 극대화를 위해서 Spot Instance를 사용한다.
사업부마다 필요 데이터와 데이터 처리 로직이 다르다. 이런 문제점의 해결방법은 각 조직별 로직을 pod화 하여 EKS상에서 운영하는 정책을 도입했다. Aurora DB나 Athena 를 이용하여 운영하는 솔루션을 채택했다.
Apache Airflow를 이용한 스케쥴링을 통해서 데이터를 체계적이고 직꽌적으로 관리하기 위해서 노력한다. 특히 데이터 특성에 따른 스케쥴링에 집중하였고, 유지보수를 위해서 MS Teams를 통해 장애알림을 즉각적으로 받을 수 있도록 노력한다.
Personalization
아직까지도 많은 문제가 존재하여 ML보다는 룰기반에 의존하고 있지만 ML Solution 적용을 노력하고 있다. 하지만 cold start 문제와 bias 문제를 해결하는 문제들이 존재한다. 따라서 MLaaS를 도입하여 (AWS SageMaker, MS Azure ML)등을 통해서 해결하는 방안도 고려하고있다.
3. DevSecOps 보안 적용 사례
서혁준 팀장
추진 배경
보안공역이 점점 증가하고 있다. 클라우드 IaaS에서 SaaS로, 웹에서 API endpoint로 공격 표면 영역이 넓어지고 있다. 따라서 다수의 사업자들과 글로벌 서비스에서 취약점들이 발견되고 있거나 사고가 벌어지고 있다.
따라서 기존의 웹 공격을 넘어 SW공급망, API엔드포인트, 소스코드, 클라우드 공격에 적극 대응해야한다.
- 종속 외부 라이브러리 : sw공급망을 OSS약점코드, 취약점 공격
- API Gateway : API 신규 포인트 공격
- Opensource : Log4J 이후로 관심도가 높아지나 했으나, 커뮤니티 등 취약
- 소스코드(웹) : PHP로 쓰여진 코드들이 쉽게 공격당함
이러한 다양한 분야에서 신규 보안 취약점들이 발견됨에 따라, SaaS서비스 운영자의 보안 책임이 더 높아졌다. 개발시 Q-Gate 보안을 준수했다 하더라도, 운영 시 형상 변경으로 인한 보안취약성을 관리 통제하여야 한다.
→ 소스 정적점검, 오픈소스 취약점점검, 모의해킹, 동적 점검, API 보안점검
DevSecOps 보안 프로세스
예산과 인력을 고려하여 SW 운영 보안 활동을 식별하고, 각 활동의 세부 프로세스를 기술 관리적으로 정의
| 방안 | 내용 |
|---|---|
| 정적분석 | 소스코드를 실행하지 않고 취약한 함수 사용 엽, 파라미터 입력값 검증 로직의 유무등을 체크 |
| 동적분석 | URL 세부 주소를 수집하여 파라미터, 헤더, 쿠키 변조 방식으로 취약점을 확인 |
| API 보안점검 | User Interface가 없는 API Endpoint의 인증, 오브젝트 레벨의 권한 체크 |
| 모의해킹 | 시나리오 기반으로 권한 상승, 2 Factor 인증 우회, 웹셀 업로드, 고급 SQL 주입 공격 등 수행 |
| 오픈소스 취약점 점검 | 오픈소스 커뮤니티의 악성코드 유입, 취약한 라이브러리 사용 여부를 식별 |
정적분석
배포 단계에서 자동 실행되도록 하고, 취약점이 수정되어야 운영에 배포되도록 통제
(SonarQube와 Checkmarx 를 조합하여 넓은 룰셋을 이용)
- 코드 커밋한 뒤 Jenkins의 트리거로 정적분석이 자동 실행되고, 취약점 자동 취합
- 심각/높은 등급의 취약점은 개발자가 수정 후 운영 배포 가능
- KISA 49개 보안 약점 기준 기본 룰 외에, 커스텀 룰을 추가하여 품질 개선
동적점검 & 모의해킹
전문가 모의 해킹과 동적점검의 장단점을 혼합하여 반복 수행 가능하도록 구성하고 의미 있는 취약점을 발견
- 전문가가 수립한 시나리오 기반으로 모의해킹을 수행. 대상은 in-hous SW 필수, 솔루션 SW는 선택적으로 수행한다.
- Python 프로그래밍, N-map을 활용하여 자동화. ZAP과 Burp Suite 플러그인 이용하여 재개발
DevSecOps 적용 성과와 과제
점검경롸가 빠른 주기로 중앙 집계되어 정량화되고, 보안 위험이 가시화됨에 따라 변화의 트리거가 됨.
현업 개발 조직의 시큐어 코딩 인식이 재고됨
- CI/CD 단계에서 자동 점검되어 배포가 중단되므로 개발자는 시큐어 코딩에 더욱 관심을 가지게 됨
- 시큐어 코딩 플랫폼을 이용하여 교육을 실시 후 평가한 결과, 점검 항목별 50%-90% 수준으로 이해하고 있음.
DevSecOps
- DevSecOps는 개발 프로젝트의 DevOps 적용이 전제되어야 함 (취약점 수정 가능한 개발자 필요, CI/CD 연동)
- 보안팀과 개발팀의 높은 업무 피로도를 감소시켜야 함 (예: 오탐 최소화)
- 23년은 프로세스 정착의 해였다면, 24년은 개발자 인식의 개선, 조치 리드타임 줄이기, 점검 자동화를 고도화하여 DevSecOps 성숙도를 높여야 함.
