
Stanford의 CS 224n의 첫 강의를 들었다.
강의의 전반적 차례 이후 WordNet에 대해 시작했다.
모든 word를 one hot vector로 구분할 경우 단어끼리의 연관성을 줄 수 없다.(여기서는 similarity)

그렇게 나온 아이디어가 word vector 이다. dense vector인데 dot 연산을 통해 similarity 를 계산할 수 있다.

word2vec의 모습이다. large corpus(body) 이며 학습시키면 비슷한 word끼리 군집을 이룬다.
중심 단어의 similarity를 계산하거나 context 단어의 probability를 계산할 수 있다.
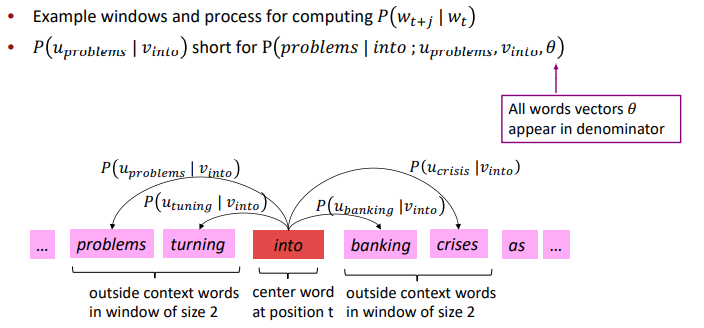

word2vec 학습 방식인데 아마 이건 CBOW(Continuous Bag of Words)같아 보인다.
주변 단어들을 통해(window크기 만큼) 중앙 단어의 Likelihood를 계산한다. 결과를 softmax function을 통해 mapping시키는거 같다. softmax는 다중분류를 위해 Deep Learning에서 많이 쓰는 함수이다.
그뒤 교수님이 glove library로 실습을 직접 해주셨다.
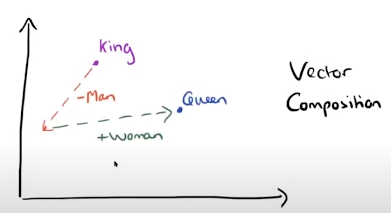
이게 word2vec의 가장 핵심이지 않을까 싶다... king 에서 man 방향의vector을 빼고 woman vector을 더하니 Queen이 나온다...
단어끼리의 연관성을 파악할 수 있지만 사람이 보기 편하지 컴퓨터가 이걸 통해 context를 파악한다고 할수 있는지는 스스로 생각할 때는 어려워보인다.
좋은 강의 감사합니다.

AI개발자를 향해 전진중