
내가 딥러닝을 시작하게 된 NLP 분야의 가장 기초가 되는 RNN을 수업 듣게 되어서 굉장히 반가웠다.
RNN
RNN은 주로 Sequential 데이터 시계열데이터에서 주로 사용되고, 보통 주식, 공장, 비디오, 문자 등 다양한하게 쓰인다.
Vanlilla Neural Networks의 한계는 고정된 크기의 vector를 입력으로 받아들이고 고정 크기의 vector를 출력합니다. 고정된 양의 계산 단계를 사용하여 mapping을 수행한다.
RNN은 vector sequence에 대해 연산을 수행할 수 있고, 더 구체적으로 만들 수 있다는 점에서 차이가 있다.
RNN process sequence
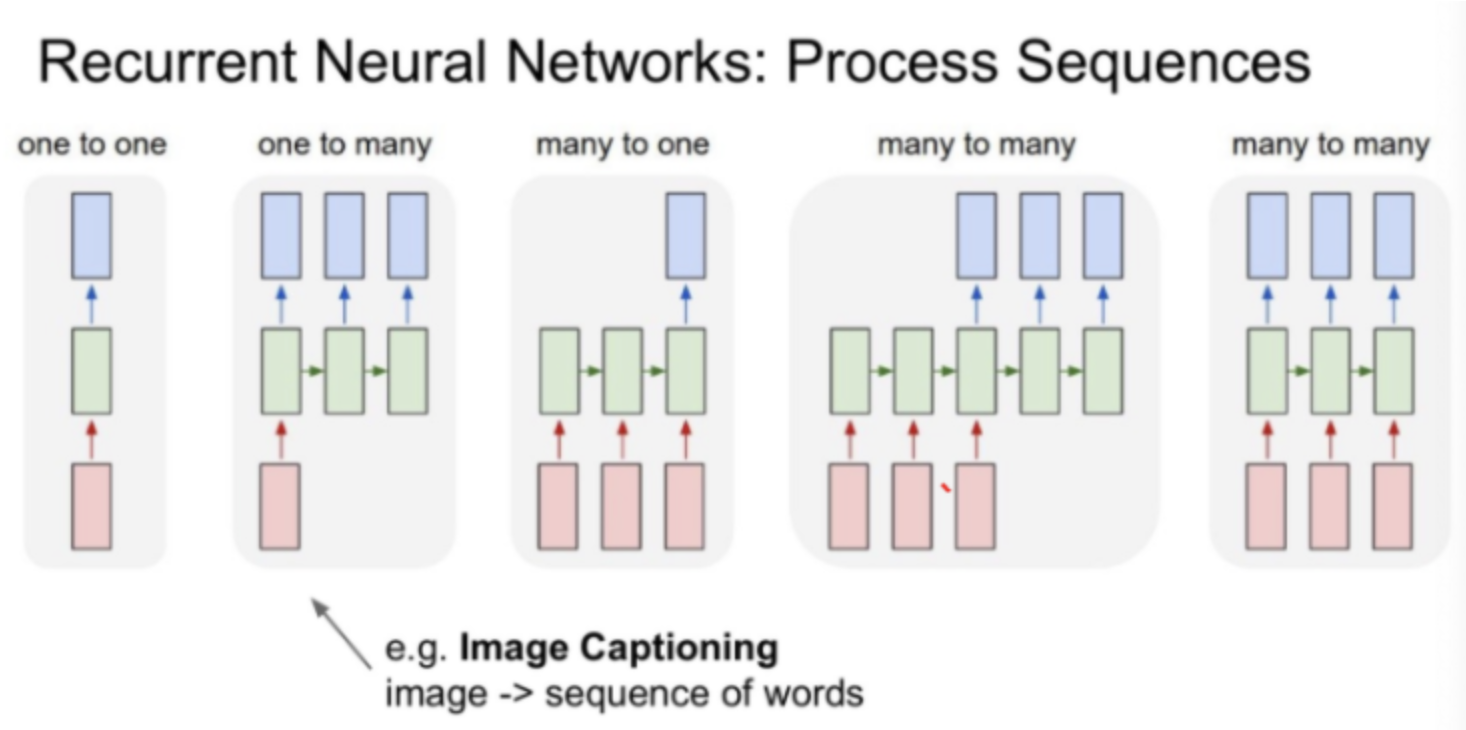
RNN은 주로 입력이 많거나 출력이 다양한 가변적인(sequential) 데이터를 수용한 모델로서 위의 구조를 간단히 정하면 다음과 같다.
one-to-many : 이미지 입력은 하나이고 그 입력에 대한 설명하는 여러 결과를 만드는 image captioning에서 쓰인다.
many-to-one : 연속적인 단어를 입력했을 때 하나의 결과를 출력하는 sentiment classification 중 감정분석, 뉴스 카테고리에서 쓰많이 사용하는 방식이다.
many-to-many : 중간에 hidden state가 많고 문장을 입력했을 때 다양한 문장을 다시 추출할 수 있는 Machine Translation 번역 모델에서 사용다.
many-to-many : 비디오같이 프레임이 연속적으로 입력됬을때 그에 따른 출력결과 다양한 video classification on frame level에서 많이 사용되는 방식으 실시간으로 영상을 분류할 때 사용된다.
이외에도 RNN은 고정된(non- sequential) 데이터에서도 유용하게 쓰인다. 아래 그림을 보면 고정된 데이터를 sequential 하게 접근하여 이미지 숫자를 파악한다.

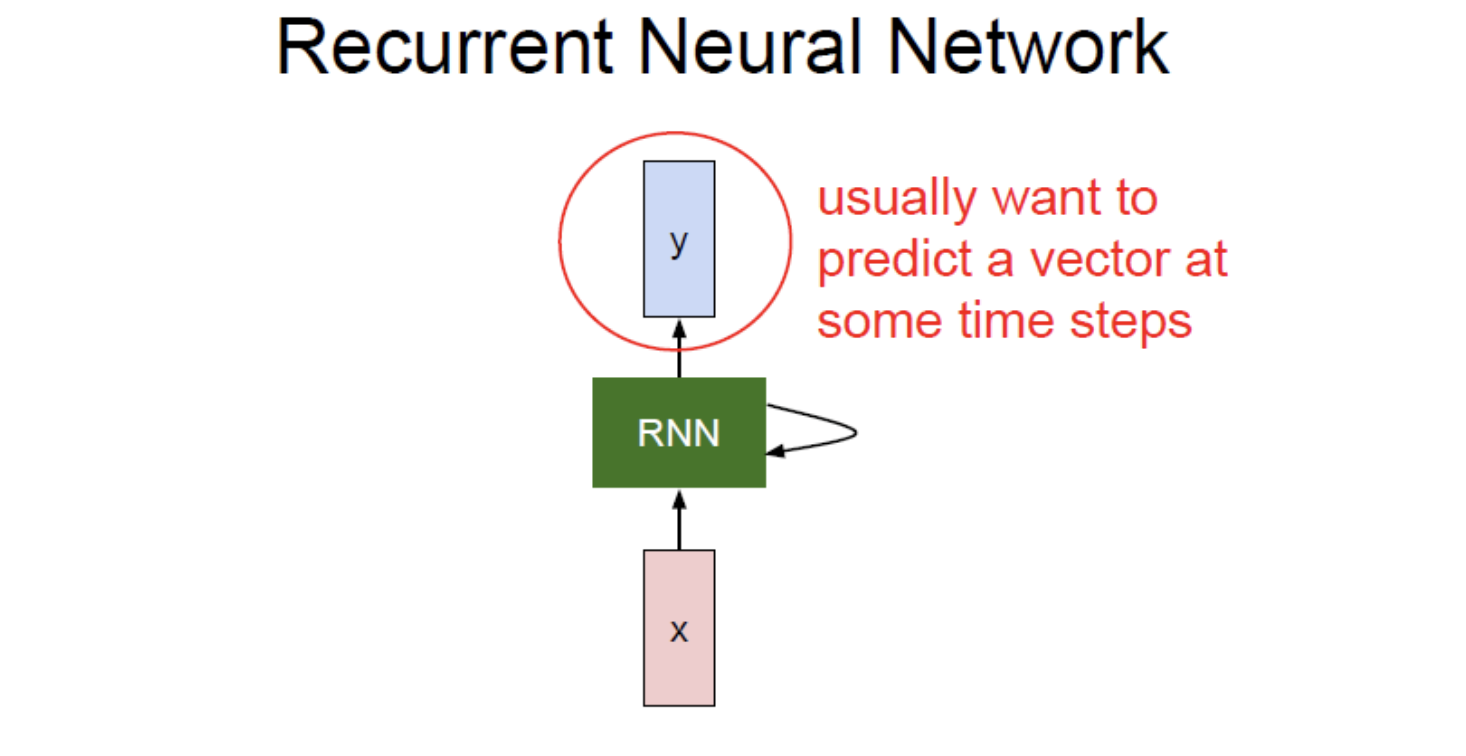
일반적으로 RNN은 작은 Recurrent Core Cell을 갖고 있다.
입력 x가 RNN으로 들어가면, RNN은 새로운 state vector를 만들어내기 위해 fixed function을 사용하여 input vector와 output vector를 결합한다.
RNN 내부의 hidden state에서 새로운 입력을 받아들여 update 되는 방식이다.
이런 방식으로 RNN은 네트워크가 다양한 입출력을 다룰 수 있는 여지를 제공해 준다.
RNN Structure
sequential process를 구현하기 위해 RNN은 입력을 했을 때 hidden state를 반복적으로 거쳐 업데이트 한 후 출력을 내보낸다.

- Input Sequence vector xt
- hidden state를 update.
- output.
NN에서 출력 값을 가지려면 ht를 입력으로 하는 FC-Layer를 추가해야 한다. FC-Layer는 매번 업데이트 되는 Hidden_state(ht)를 기반으로 출력 값을 정한다.
Vanila RNN

h(t−1)은 이전 state를, Xt는 입력값, W(hh) hidden state에서 오는 가중치, W(xh)입력값에서 RNN으로 가는 가중치, W(hy)는 RNN cell에서 출력값으로 가는 가중치를 의미한다.
non-linearity를 위해 tanh를 사용했고,각각의 W는 서로 자신의 영역에서 매 step마다 같은 값을 값을 사용한다.
RNN을 사용하면 이전의 state가 반영되어 새로운 state를 만드는 sequential 데이터에 강점이 있다.
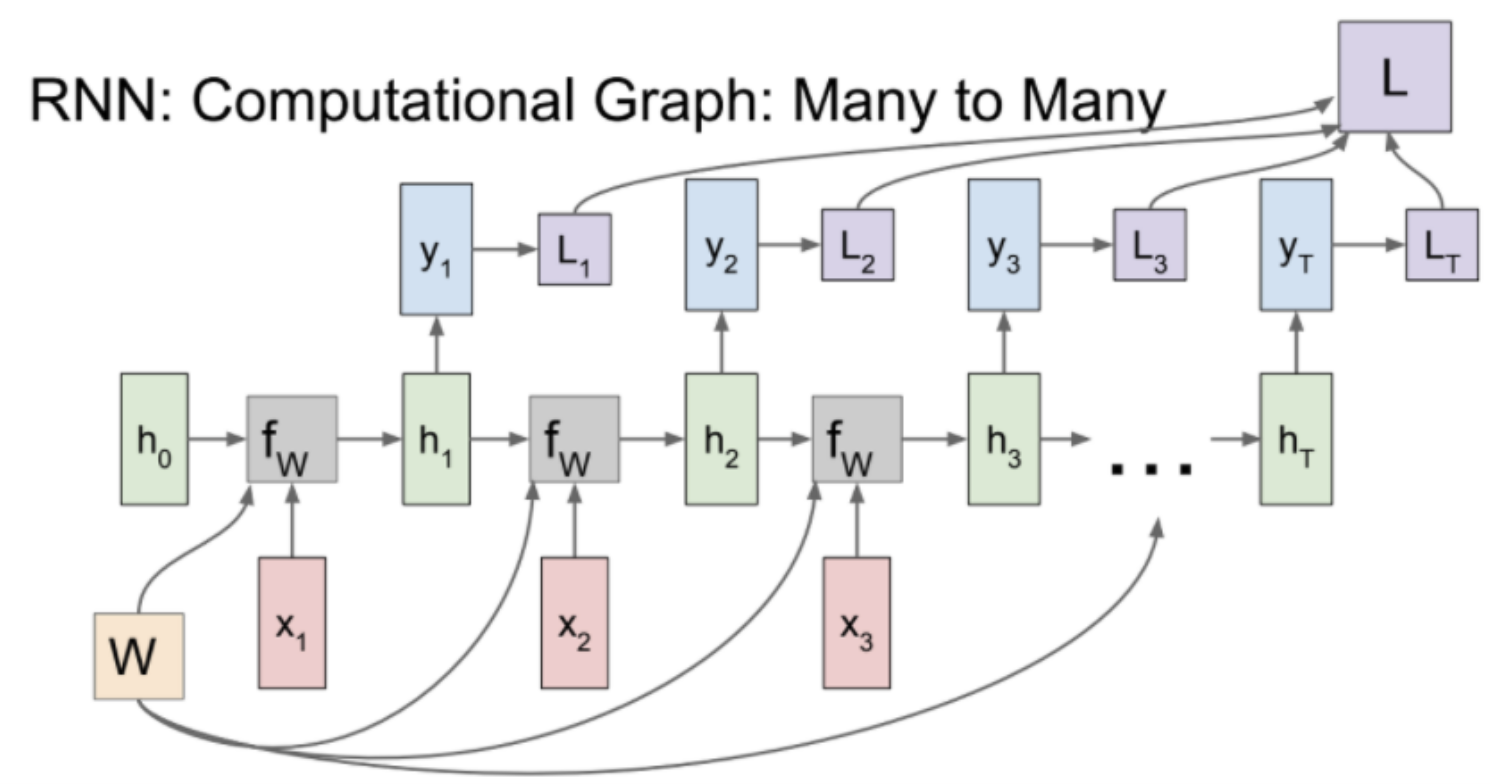
Vanilla RNN Many to Many를 Computational Graph에 그리면 위 그림과 같다.
구체적으로 input x가 여러개 들어오고, output으로 여러개가 출력되는 many to many 구조를 예로 살펴보면 시간에 따라 연속적인 입력값이 hiden state로 들어오고 모두 같은 가중치(Wh)를 사용하는 것을 알 수 있다.
또한 hidden state가 반복적으로 사용됨에 따라 출력값도 연속적으로 나오는 것을 볼 수 있다. 이때 각 출력값 마다 loss를 계산해 최종 loss에 합산한다.
Sequence to Sequence
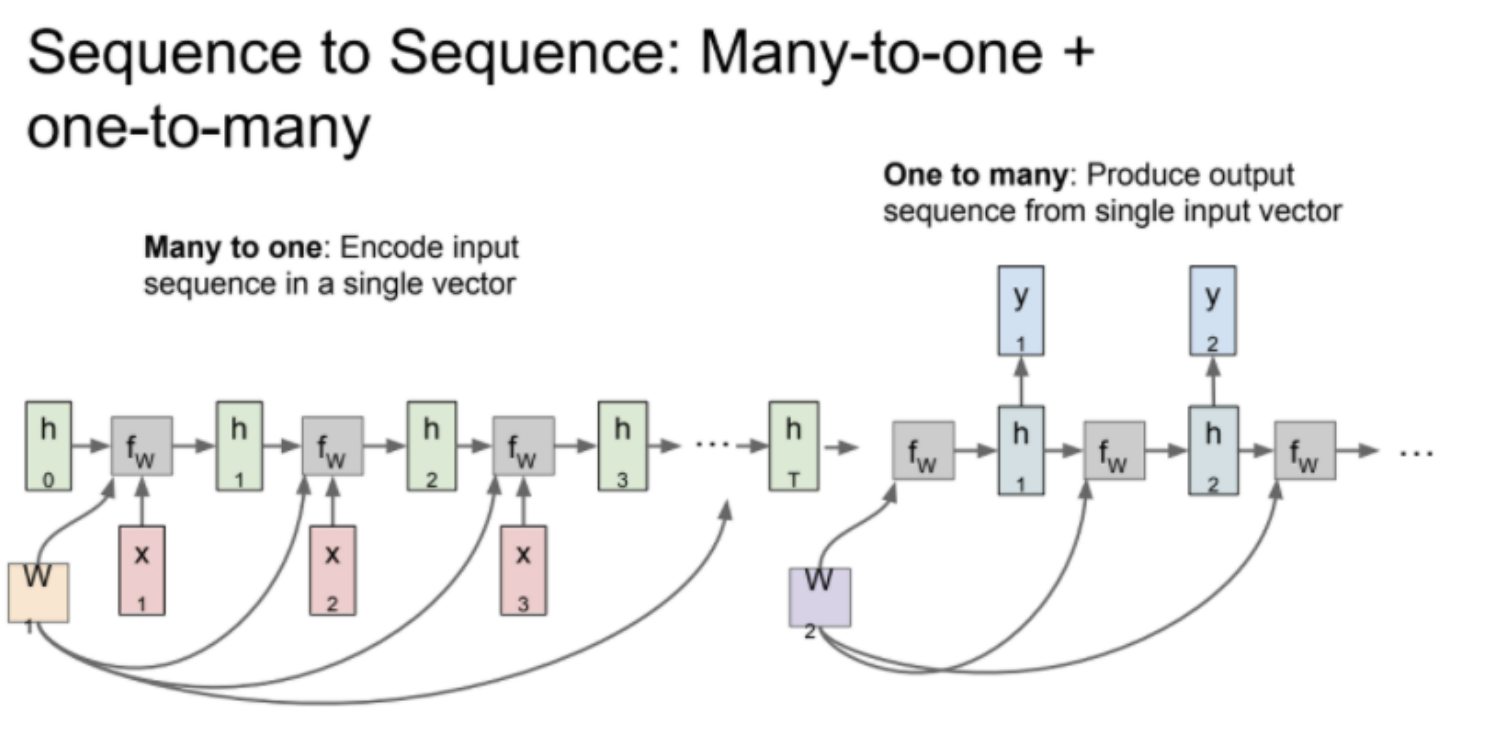
Sequence2Sequence 구조다. Many to one -> one to Many이다.
Many to one은 Encoder, one to Many 는 Decoder가 되는 구조이다.
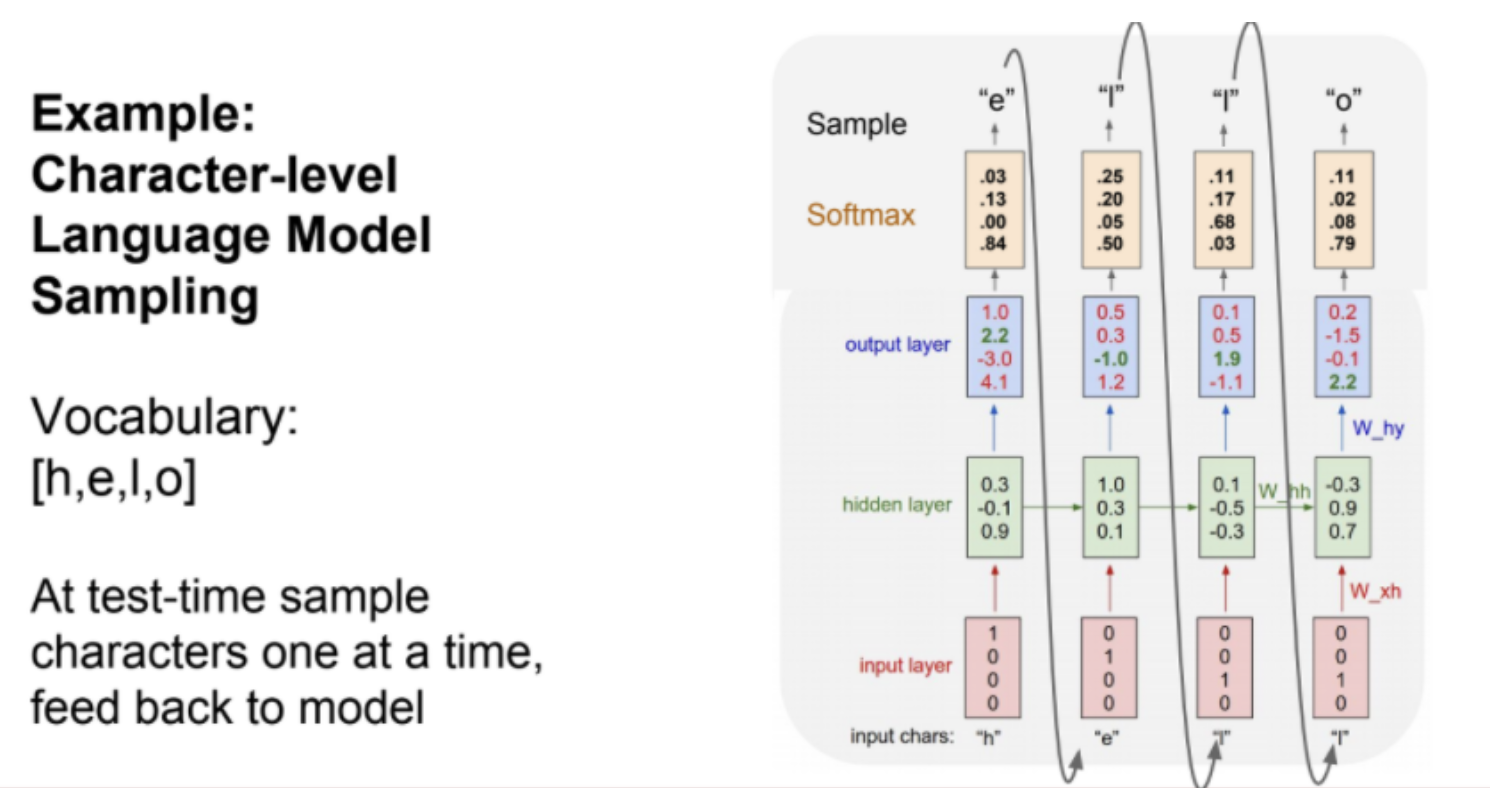
hello라는 문자열로 예를 들어 설명해보자.
helo 를 입력했을 때 o를 예측하는 것이 목표다. 문자를 one-hot Encoding으로 바꾸어 입력하고 hidden state를 반복적으로 거친다. 그리고 softmax 함수를 사용해 스코어를 확률분포로 표현하였다. 확률분포를 사용한 이유는 모델의 다양성을 위해서다.
그런데 RNN을 이용해 학습을 진행하다 보면 sequence 길이가 긴 데이터의 경우 backpropagation through time(출력 값들의 loss를 계산하여 최종 loss 를 얻을 때까지 걸린 시간) 이 길어지는 문제가 발생할 수 있다.
이러한 경우 전체 문장을 잘게 쪼게서 각 단위별로 loss를 계산하는 방식을 사용한다.
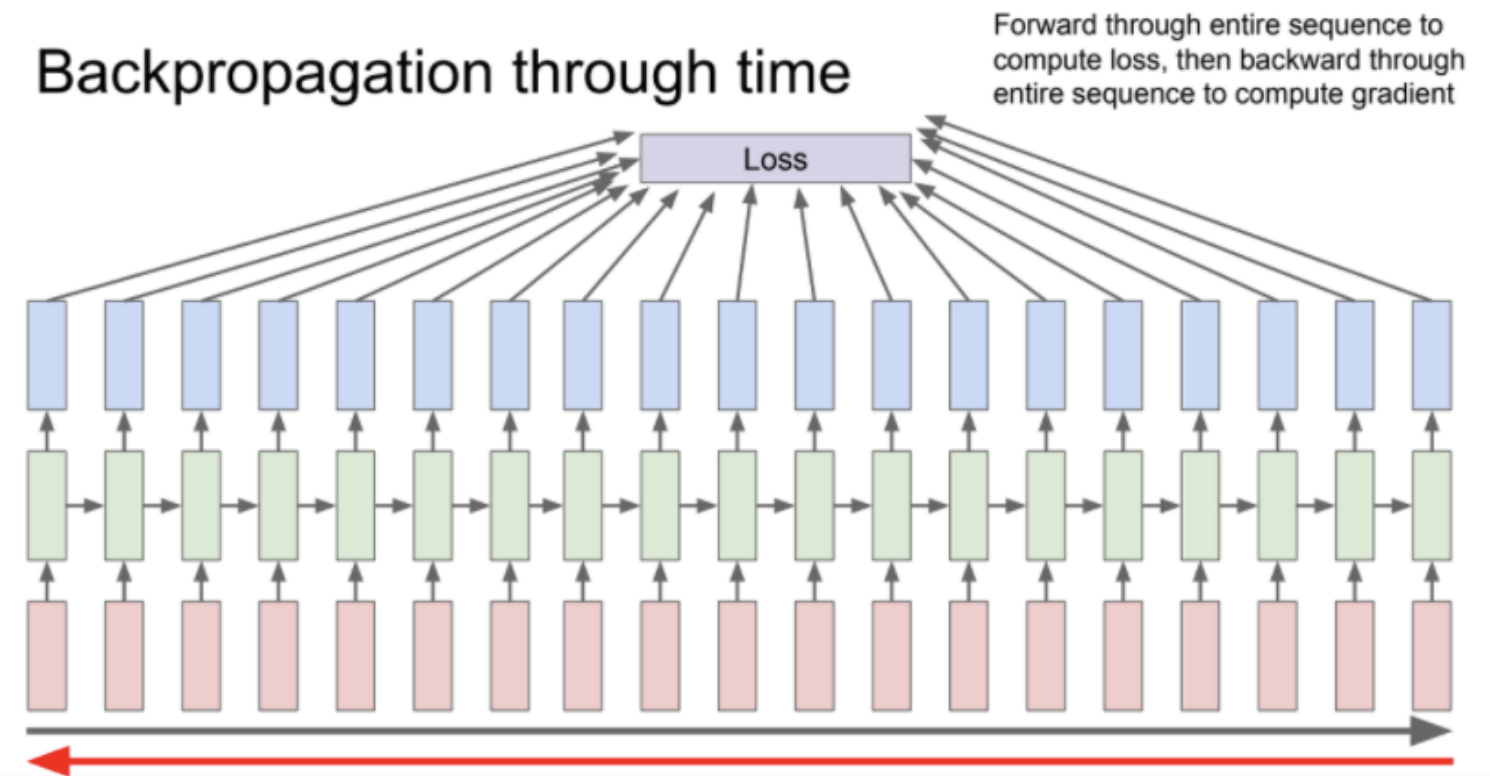
Image Captioning
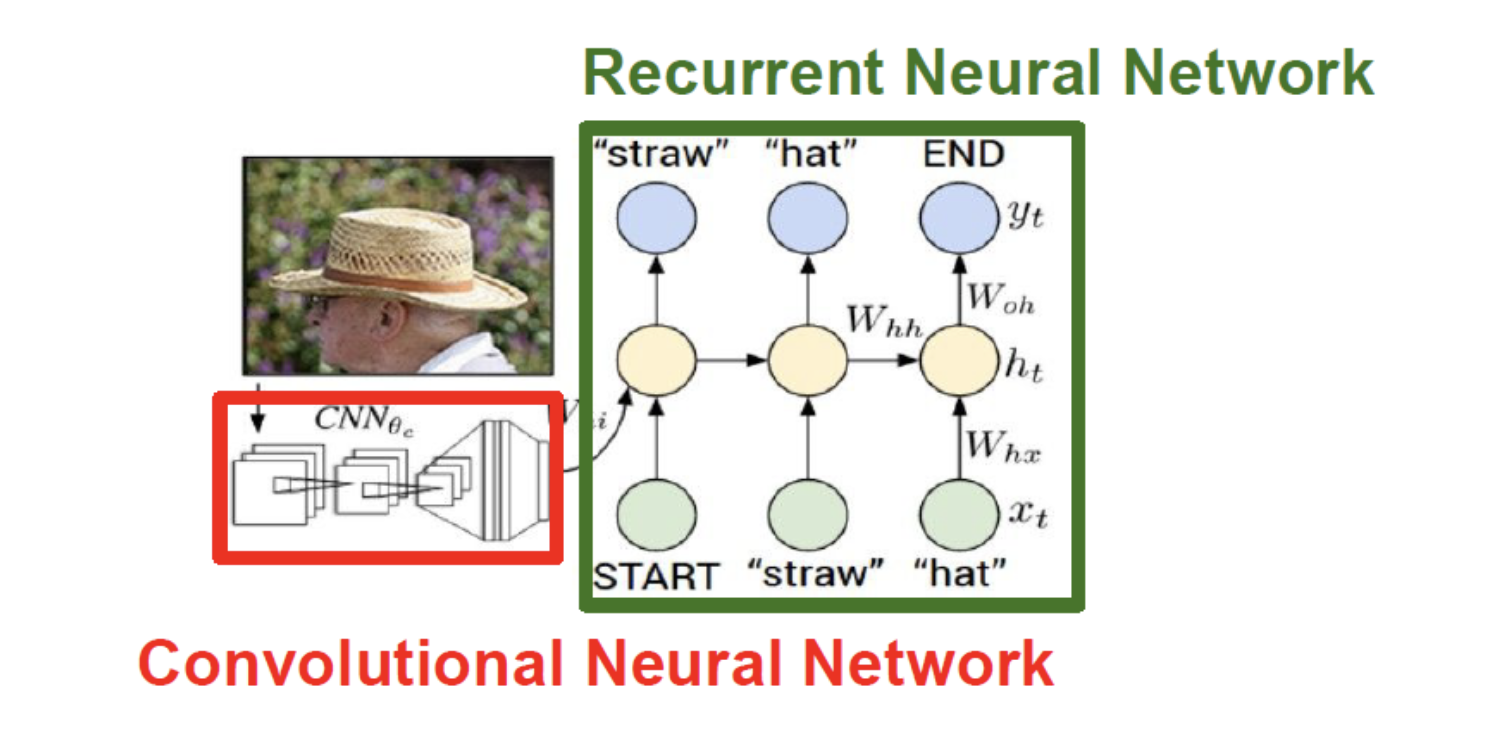
이미지는 CNN을 통해 Vector상태로 출력된다. 그리고 RNN에 초기 step input으로 들어간다.
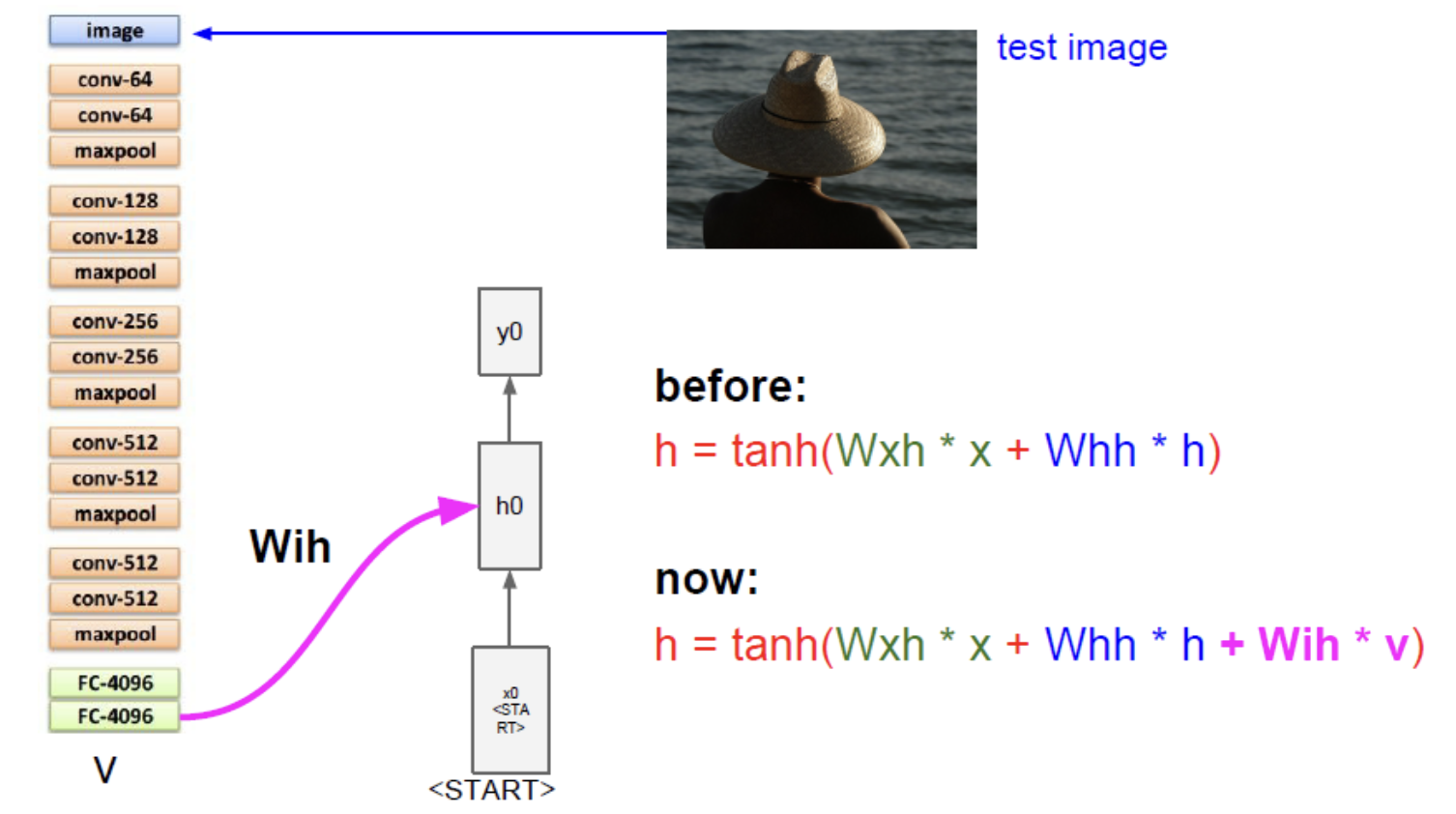
이때 RNN은 기존 RNN과 다르게 Wih라는 image weight를 가진다. hidden state를 계산할때 하나의 weight를 추가로 같이 계산해준다.
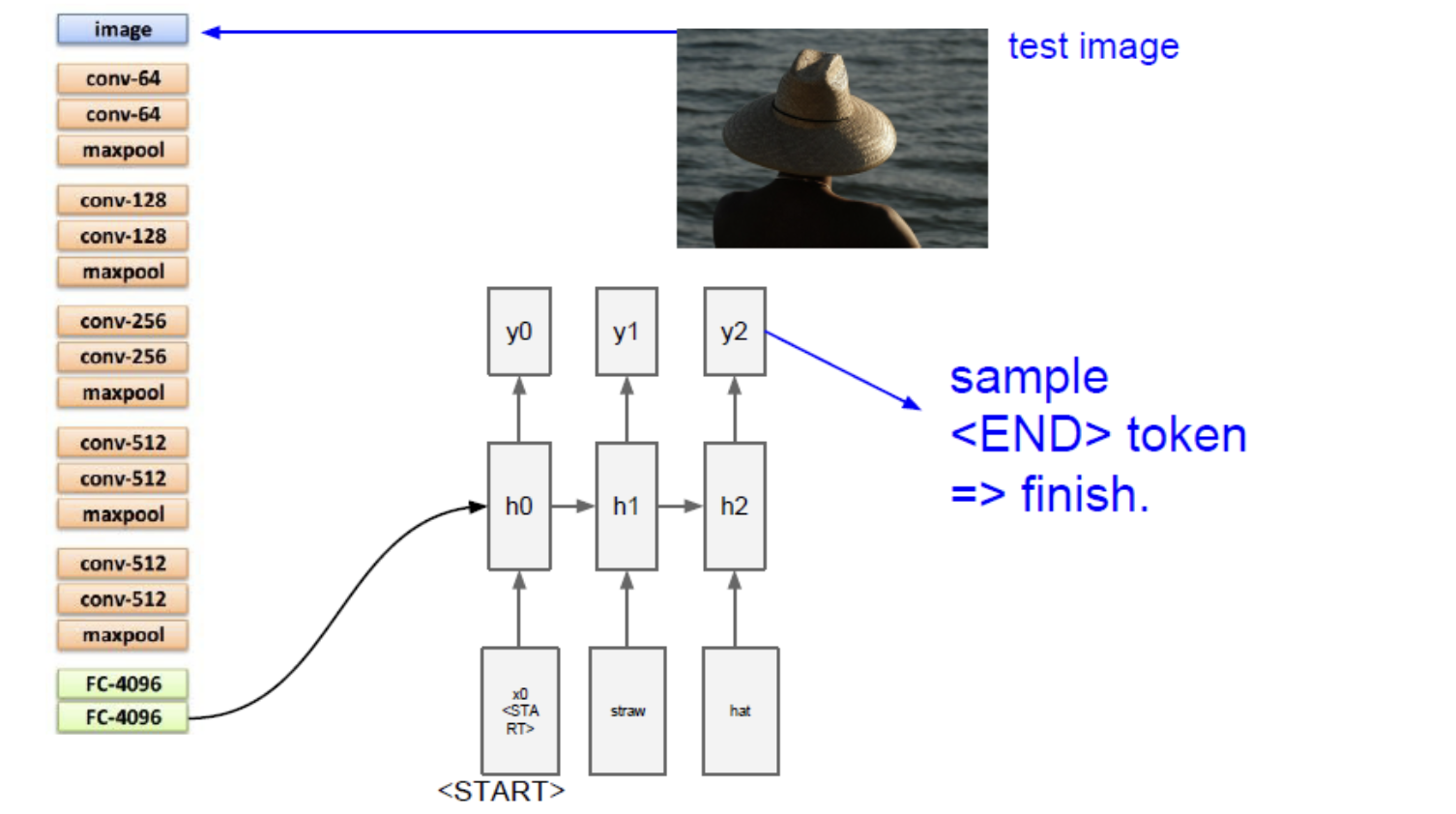
마지막 END token이 들어오면 끝이나고 image에 대한 caption을 완성한다.
학습이 끝나고 Test time에는 모델이 문장 생성을 끝마치고 토큰을 샘플링한다. 이 Task를 위한 가장 큰 데이터 셋은 Microsoft COCO 데이터셋이 있으며 이 모델을 학습시키기 위해서 natural language model과 CNN을 동시에 backprop 할 수 있다.
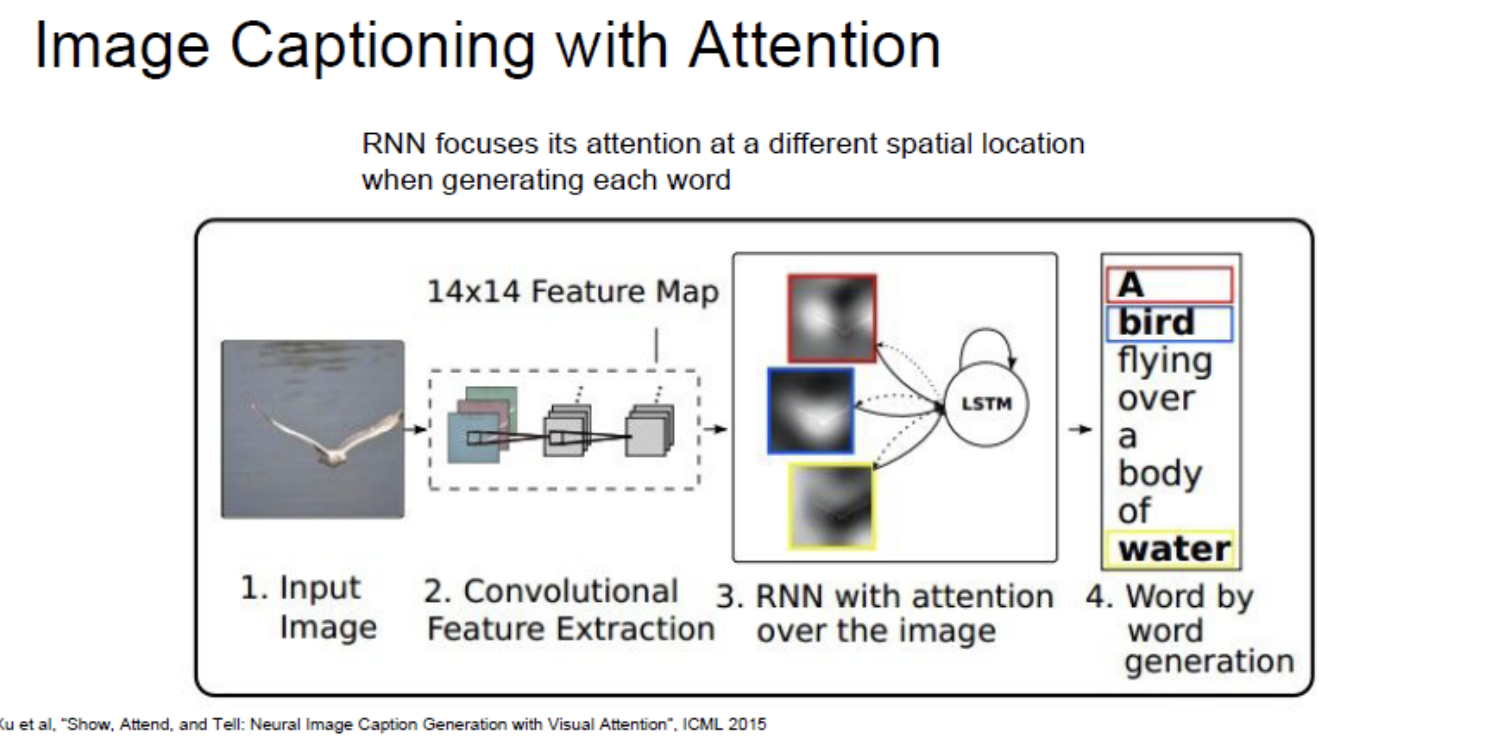
또한 Attention을 활용한 Image Captioning도 있다.

RNN의 문제점
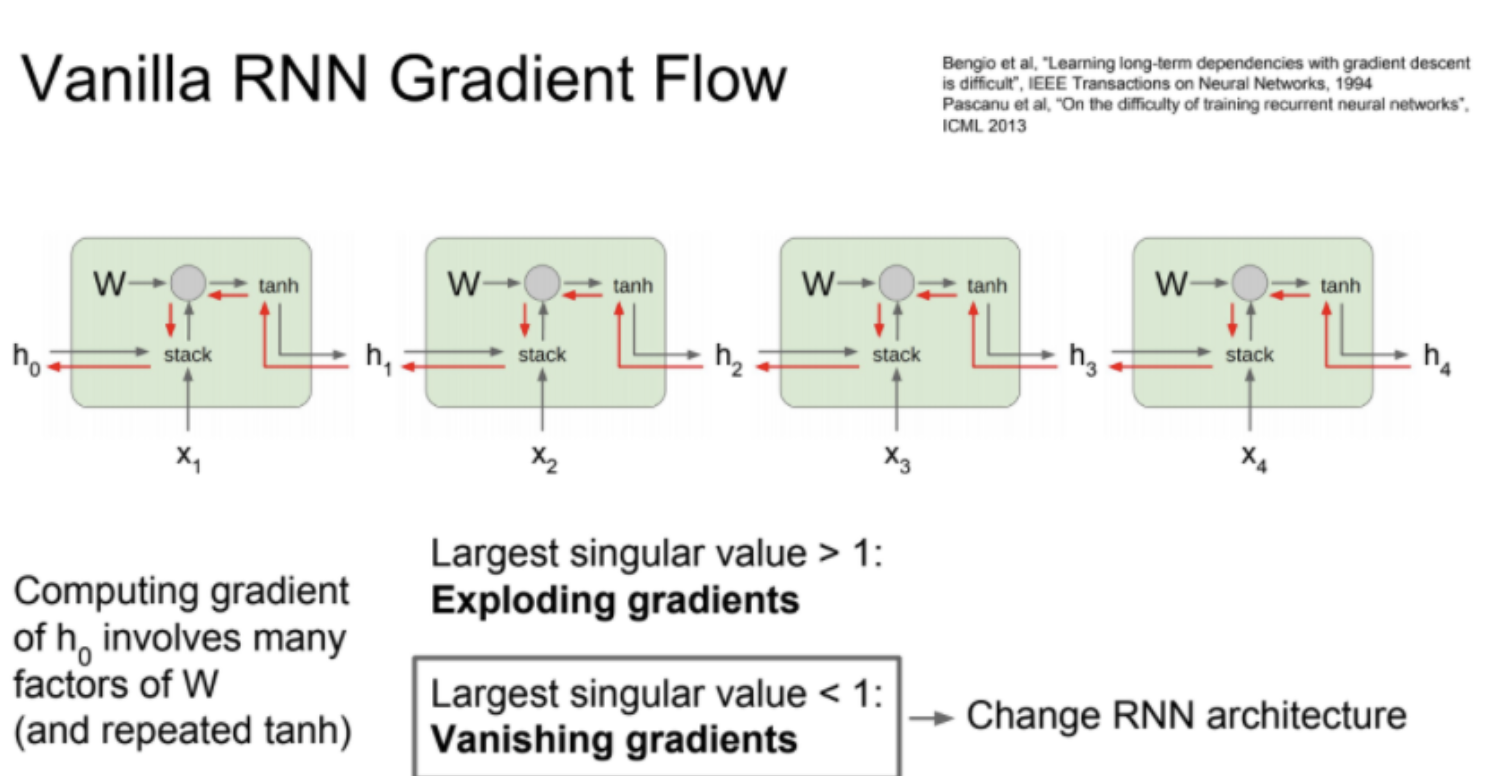
RNN은 여러 Sequence Cell을 쌓아 Back prop 과정에서 모든 cell을 통과할 때 가중치 행렬 W의 transpose factor가 곱해져 특이값이 1보다 커져 exploding gradient가 발생하거나, 1보다 작아져 0이 는 vanishing gradient 문제가 발생한다. gradient clipping이라는 방법을 사용해 해결 할 수 있지만, 아키텍쳐를 새로 디자인 한 모델이 등장한다.
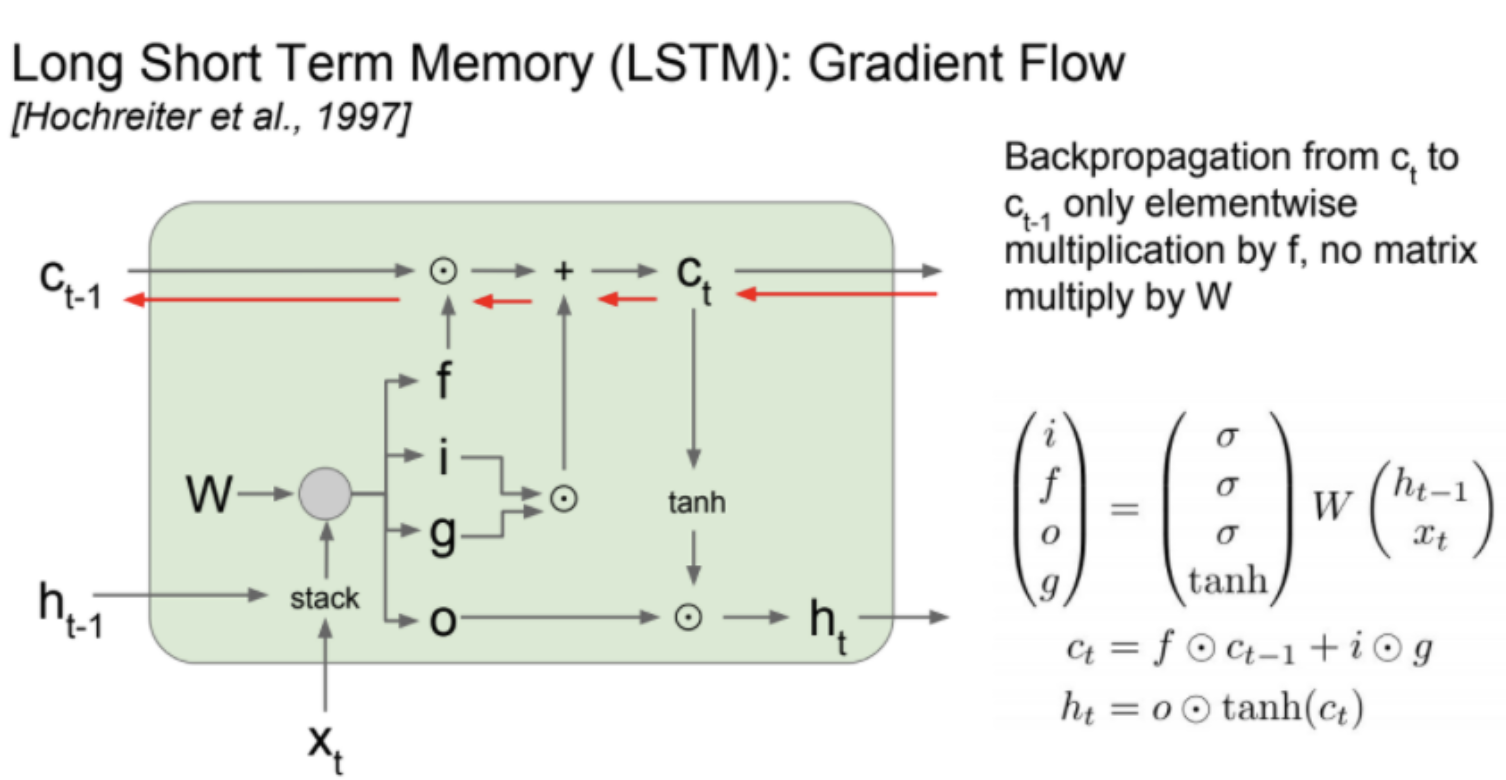
Long Short Term Memory(LSTM)
이러한 RNN의 gradient exploding/vanishing 문제를 해결하기 위해 LSTM(Long Short Term Memory)가 등장한다.
LSTM은 RNN에 4개 gateway를 추가한 모델이다. hidden state를 스택하고 4개의 gate로 가중치 행렬을 곱해다.
- i 는 input gate로 cell 에서의 입력에 대한 가중치
- f 는 forget gate 이다. 이전 스텝 cell에 정보를 다음 스텝으로 넘어갈때 지지를 정하는 가중치다.
- o 는 output gate로 cell state 를 얼마나 밖으로 출력할 것이냐를 정한.
- g 는 gate gate 로 input cell 을 얼마나 포함시킬지를 정한다.
RNN보다 좋은 2가지 점
- f와 곱해지는 연산이 matrix multiplication이 아닌 element-wise.
full matrix multiplication 보다 element wise multiplication이 더 낫다. - element wise multiplication을 통해 매 스텝 다른 값의 f와 곱해질 수 있다는 점입니다.
앞서 vanilla RNN의 경우에는 동일한 가중치 행렬(ht)만을 계속 곱했다. 이는 exploding/vanishing gradient 문제를 일으켰었는데, 반면 LSTM에서는 f가 스텝마다 계속 변하기 때문에 LSTM은 exploding/vanishing gradient 문제를 더 쉽게 해결한다.
f는 sigmoid에서 나온 값이므로 element wise multply가 0~1 사이의 값입니다.f를 반복적으로 곱한다고 했을 때 더 좋은 수치적인 특성으로 변한다.
vanilla RNN의 backward pass에서는 매 step에서 gradient가 tanh를 거쳤으며 LSTM에서도 hidden state ht를 출력 yt를 계산하는데 사용한다.
만약 LSTM의 최종 hidden state ht를 가장 첫 cell state(c0)까지 backprop하는 걸 생각해보면, RNN처럼 매 스텝마다 tanh를 거칠 필요가 앖으며 단 한 번만 tanh를 거치면 된다.
RNN과 LSTM의 weight upgrade
가중치 W에 대한 Local gradient는 해당 스텝에 해당하는 현재의 cell/hidden state로부터 전달된다. vanilla RNN의 경우 각 스텝의 가중치 행렬 W들이 서로 영향을 미쳤다.
반면 LSTM의 경우에는 가령 아주 긴 시퀀스가 있고 그레디언트가 맨 끝에서부터 전달되기 시작된다고 했을 때, 이 시퀀스의 backprop 과정에서 각 스텝마다 w에 대한 locla gradient가 있을 것이다.
W의 local gradient는 cell/hidden state로부터 흘러옵니다. LSTM의 경우 cell state가 gradient를 잘 전달해주기 때문에 w에 대한 local gradient도 훨씬 더 깔끔하게 전달됩니다.
LSTM은 gradient Exploding/vanishing 문제를 완전히 해결?
f의 경우 출력이 0~1이니 항상 1보다 작으므로 gradient가 점점 감소할 수 있다.
그래서 해결 방법으로 f의 biases를 양수로 초기화 시키는 방법이 있다. 이 방법을 이용해서 학습 초기에 forget gate의 값이 1에 가깝도록 해준다. 1에 가까운 값이기 때문에 적어도 학습 초기에는 gradient의 흐름이 비교적 원활합니다.
그리고 학습이 진행되면 f의 biases가 적절한 자기 자리를 찾아갑니다.
물론 LSTM에서도 vanishing gradient 문제가 발생할 수 있다. 하지만 vanilla RNN 보다 덜 민감한 이유는 매 스텝마다 f가 변하기 때문이고, 두 번째 이유는 LSTM에서는 Full Mat-mul이 아닌 element-wise multiplication을 수행하기 때문이다.
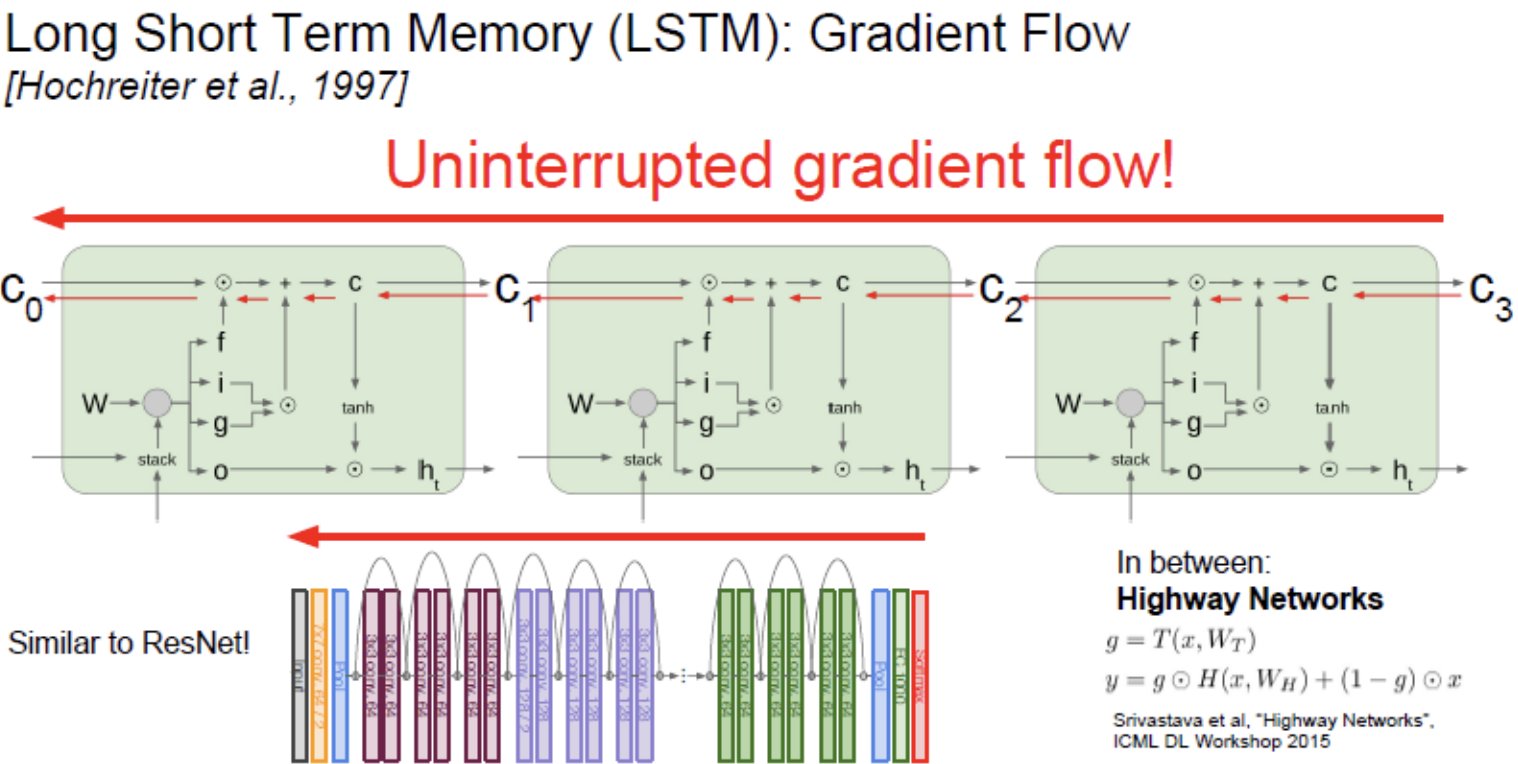
ResNet의 Backward pass에서 identity connection이 아주 유용했는데 Identity mapping이 ResNet gradient를 위한 고속도로 역할을 했다.
LSTM도 동일한 intuition이라 ResNet과 비슷하다 볼 수 있다. LSTM의 Cell state의 element-wise mult가 그레디언트를 위한 고속도로 역할을 하기 때문이다.
