ALEX: An Updatable Adaptive Learned Index
Intro
마이크로소프트에서 ALEX 라는 자료구조를 만들었다. 머신러닝을 통해 기존 DBMS에서 인덱싱에 사용하는 B+ Tree 보다 읽기/쓰기 속도가 4.1배 빠르고, 인덱스 크기가 2000배 작다고 한다. 사용 또한 어렵지 않아 std::map과 std::multimap을 그대로 대체할 수 있다고 한다. 어떻게 이게 가능한지 궁금해 발표한 논문을 찾아봤고, 부족한 지식으로 이해한 내용을 간략하게 요약해보려고 한다.
Learned Index
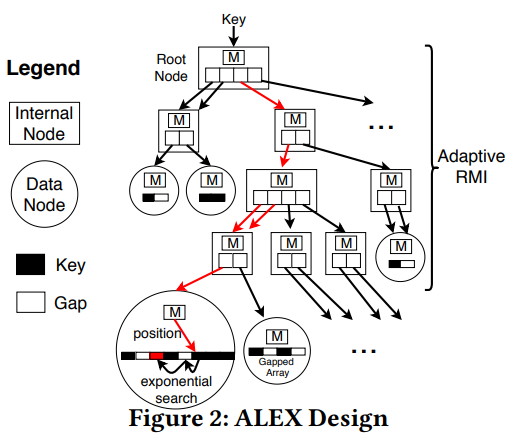
ALEX를 알기 위해선 먼저 Learned Index라는 것을 알 필요가 있다. Learned Index는 Kraska et el. 이 만든 모델로, 여러 계층의 머신 러닝 모델들로 이루어져 있다. 찾고자 하는 key가 주어졌을 때, 모델의 중간 노드는 어떤 어떤 하부 모델을 사용할지 예측하고, 리프 노드는 밀도 있게 압축된 배열에서 어디에 key의 위치를 예측한다. Learned Index의 모델들은 내부의 데이터로부터 학습한다. 주어진 데이터의 분포를 학습한 모델은 key의 위치를 충분히 정확하게 예측할 수 있고, 이는 커다란 성능 향상을 가져온다. 하지만 Learned Index는 읽기 전용 데이터만 지원하기 때문에 실제 DBMS에 적용하기엔 무리가 있다. 이 문제를 해결하고 Learned Index보다 더 빠른 자료구조를 만들기 위한 노력 끝에 탄생한 것이 ALEX 이다. ALEX의 핵심 내용은 크게 두 가지 이다. 하나는 어떻게 Learned Index 보다 빨라졌는가 이고, 다른 하나는 어떻게 데이터 추가/수정/삭제의 경우에도 모델의 정확성을 유지하는가 이다.
어떻게 더 빨라졌는가
Learned Index 보다 더 빠른 속도를 위해 ALEX는 보다 모델에 최적화된 전략을 도입했다. 그 중 하나는 데이터 노드에 Gapped Array 를 사용해 데이터가 추가될 때 마다 키가 이동하는 비용이 발생하는 것을 막은 것이다. Gapped Array 는 key를 배열에 저장할 때 주변에 빈 공간 (사실은 성능 향상을 위해 같은 key로 채워져 있다) 을 두어 새로운 key를 위한 예비 공간으로 사용하는 것이다. 또한 데이터를 추가할 때에도 모델에 기반한 삽입 을 통해 그 위치를 지정해 정확도를 높힌다. 높은 정확도는 곧 빠른 검색 속도로 귀결된다.
또한 예측이 정확하지 않을 때에는 (그래도 충분히 정확하다는 가정 하에) 찾은 위치에서 주변을 탐색하며 정확한 위치를 찾을 필요가 있다. 이 경우 Learned Index는 오차 범위를 정해놓고 그 내부를 binary search로 탐색해 key를 찾는다. ALEX는 exponential search를 사용하는데 모델이 정확할 경우 항상 binary search 보다 나은 결과를 보여준다.
모델의 정확성 유지
데이터가 변화는 환경에서 모델의 정확성을 유지하기 위해 다양한 (그리고 복잡한) 전략들을 사용한다. 그 내용을 전부 설명하기엔 공간도, 이해도도 부족하기 때문에 간단히만 적어본다. 가장 중요한 부분은 데이터가 변할 때 바뀐 부분만 선택적으로 모델을 재학습 시켜 적은 비용으로 정확도를 유지하는 것이다. 여기에 더불어 전략적으로 노드를 확장, 분할해 데이터 분포가 고르지 않거나 빠르게 바뀌는 와중에도 정확도를 유지한다. 실제 운용되는 데이터로 테스트 했을 때에도 성능이 유지가 되었고, 별도의 파라미터를 수동으로 설정할 필요도 없다고 한다.
ALEX는 새로운 데이터를 Insert 할 때 탐색과 동일한 방법으로 key의 위치를 찾는다. 만약 예측이 정확해서 Insert 할 수 있는 빈 공간을 찾았다면 그대로 key를 추가하면 된다. 예측이 틀렸을 경우엔 exponential search를 통해 적당한 위치를 찾는다. 문제는 빈 공간이 더 이상 없을 경우다. 빈 공간이 너무 줄어들게 되면 key가 들어갈 공간을 만들기 위해 다른 key 들을 shift 해야 하기 때문에, Gapped Array에서 약 80% 정도의 공간이 사용되면 확장을 시도한다.
확장을 위해서는 크게 Gapped Array의 크기를 늘리거나, 새로운 노드를 옆으로 혹은 아래로 생성하는 방법이 있다. 어떤 방법이 좋을지는 ALEX의 알고리즘이 더 모델의 오차가 적어지는 방향으로 결정한다. 오차가 더 적다는 것은 예측 후 원하는 key를 찾기 까지의 exponential search 수행 횟수가 더 적다는 것을 뜻한다. 배열이 크기를 늘리는 것은 모델을 변경할 필요가 없지만 오차가 점점 더 커진다. 예측한 계산 시간보다 50%이상 차이나게 오차가 벌어지면 새로운 노드를 생성하는 것이 경험적으로 좋은 성능을 보여준다고 한다. 노드를 생성해 데이터를 분리하면 각자 노드에서 자신이 가지고 있는 데이터로 새로 학습을 시작할 수 있다.
Outtro
Learned Index를 확장하는 것 외에도 원문은 어떻게 효율적으로 메모리를 사용하는지에 대해 많은 지면을 할애하고 있다. 머신러닝을 통해 기존의 Tree 구조 보다 더 많은 수의 선택지 속에서 정확히 원하는 위치를 예측해내는 것이 Learned Index의 성능의 비결이었다면, ALEX의 비결은 훨씬 더 유연한 구조를 최대한 작은 메모리 안에 집어넣음으로써 캐시 미스를 줄이는 것 같은 느낌이었다. 원문은 더 다양한 경우에 ALEX가 어떻게 동작하는지에 대한 설명과, 그렇게 동작하는 이유를 데이터로 뒷바침 해주고 있다.
물론 단점이 없는 것은 아니다. 극단적인 outlier key가 존재한다면 차지하는 메모리 공간이 불필요하게 커지고 속도 또한 느려진다. 또한 현재는 인 메모리 상에서만 싱글 스레드로 동작하며, key는 숫자만 사용할 수 있다. ALEX는 선형 회귀분석을 사용하기 때문에 key의 분포가 모델을 만들기 어렵게 분포되어 있다면 성능이 나빠질 수도 있다. 이러한 문제점들에 대해선 개선 및 연구가 진행될 것이라고 한다.
마지막으로, ALEX를 통해 이득을 보려면 학습 및 계산에 드는 비용이 key를 찾거나 업데이트 하는 비용에 비해 매우 작아야 할 것 같다는 생각이 들었다. 원문에서도 속도 측정을 위해서 사용한 데이터셋은 1억개의 key를 가지고 있었다고 한다. 결국 데이터베이스 이외의 용도로 사용하기엔 어렵다는 생각이다.
