포인트 위주로 정리
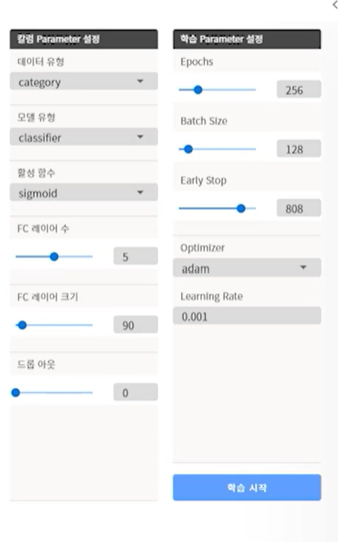
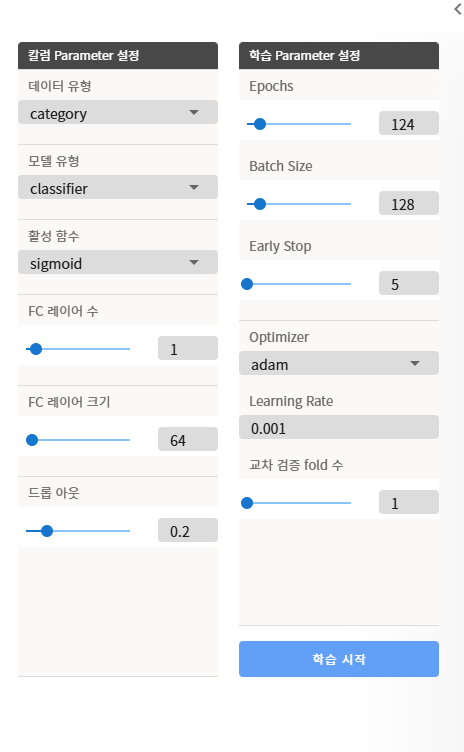
학습파라미터 설정
- 초기
- FC레이어 수 : 1
- FC레이어 크기 : 64
- Epochs : 20
- Batch Size : 128
- Early Stop : 5
- 드롭아웃 : 0 (과적합확인후 0.2~0.3)설정
- Optimizer : adam
- Learning rate : 0.001(발산, 멈추는지 확인후 조정)
모델 학습 및 평가
-
내 모델
-
-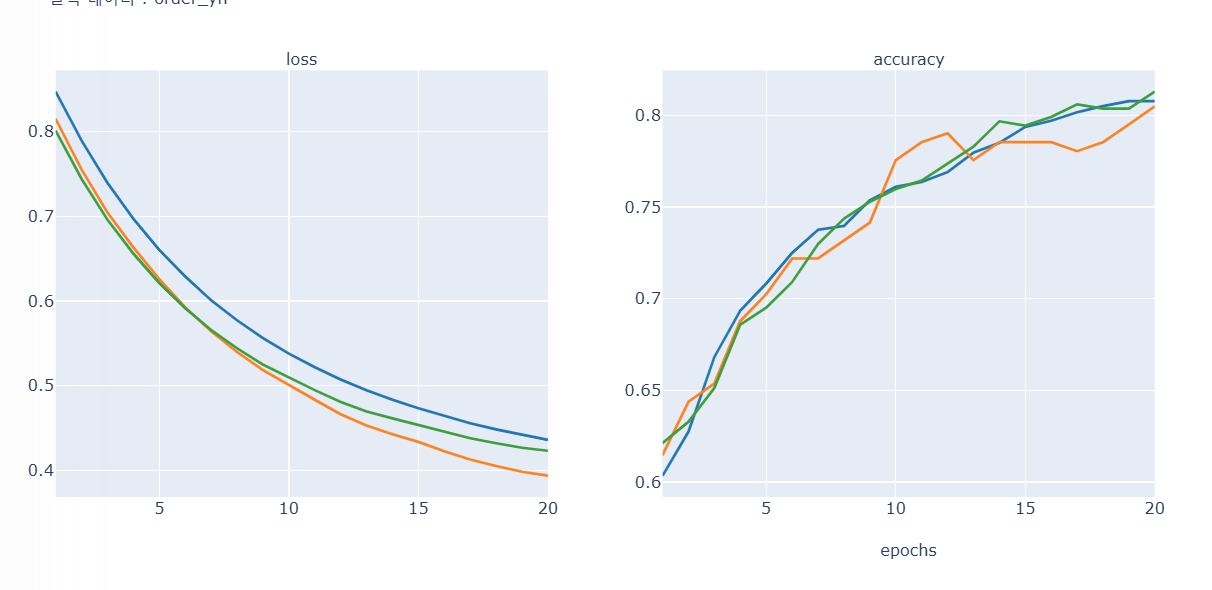
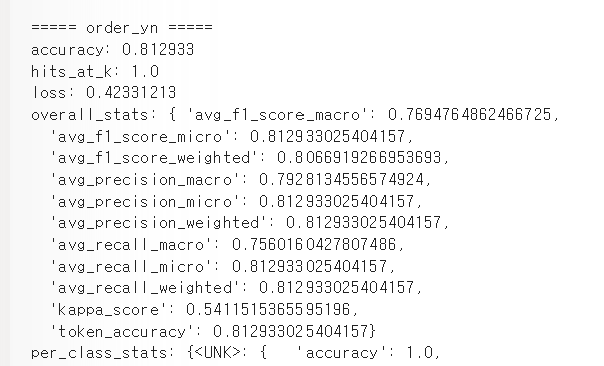
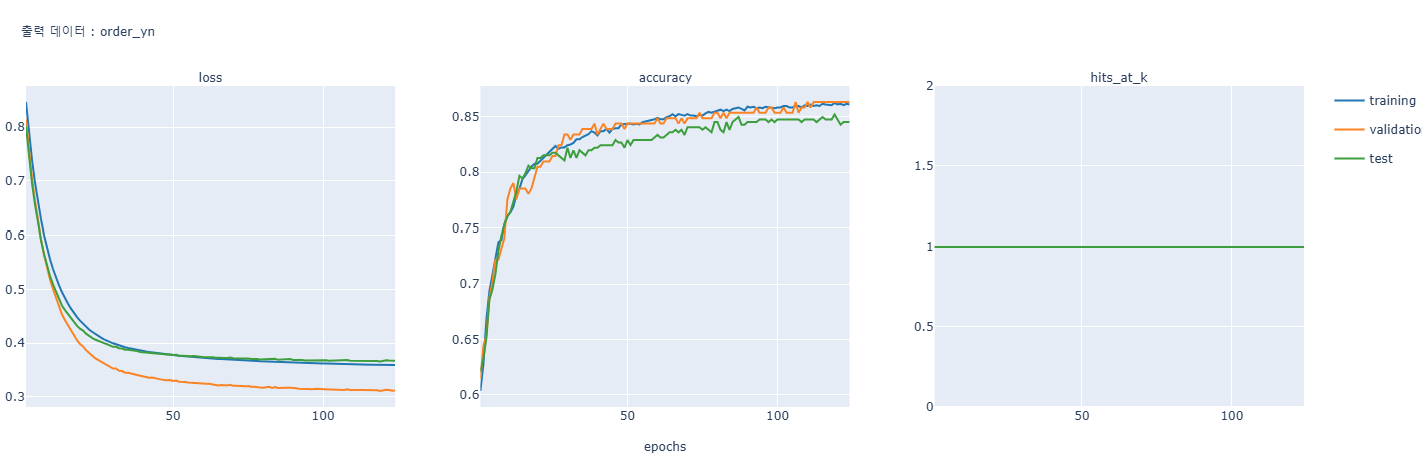
- 분류형 -> 인코딩, standard scailing 다 적용한 상태 - 오히려 강의 보다 정확도가 낮게 나오는 것 확인 가능 - 다만 Train Loss는 증가하지만 Valid Loss가 감소하는 상황은 바람직한 상황 특히 일반화 성능이 개선되고 있는 좋은 신호로 해석도 가능 - 기본적으로 valid 수치가 높은게 올바른 형태 따라서 개선의 여지가있다고 판단 - 해결: epochs를 늘리고 드롭아웃과 얼리스탑같은 과적합 방지를 적용해 정확도를 0.85가지 올렸음 - 알게된점: 스케일링 인코딩 적용한 내 모델과 스케일링 인코딩 적용안한 강의 모델의 정확도가 큰 차이가 없음 따라서 실제 실습에서 무조건 인코딩과 스케일링을 적용할 필요는 없어보임 다만 이상치에 대한 판단에 따른 결측치와 스탠다드는 필요해보임 강의에는 이상치에 따른 판단을 안했지만 내모델은 판단이 들어가서 판단을 해서 하는것이 더욱 좋아보임 어차피 정확도는 같으므로 - 0.852194, - 개선 모델 정확도 - 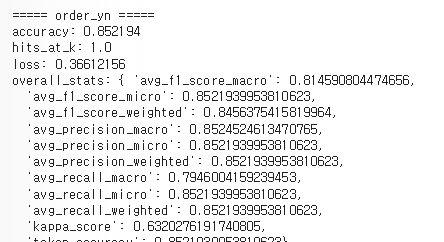 - 강의 모델 정확도와 정확히 일치 상황에 따라 결측치, 스케일링 했지만 차이가 많이 안남, 강의모델은 스케일링 처리가 안된것 사용 결측치만 되어있는거 사용 무조건 스케일링 인코딩한다고 정확도가 올라가지않음을 알수있음 - 수치형의 회귀모델의 경우 스케일링이 영향을 많이 주지만 분류형 모델의 경우는 영향을 많이 안줘서 이런 결과가 나온것같음, 분류모델을 할때는 스케일링에 힘을 줄필요가 없어 보임 - 로지스틱 회귀, SVM, KNN, K-means, NN은 영향을 많이 받음 - 트리기반모델- 의사결정, 랜덤포레스트, XGBoost, LightGBM 은 영향 많이 안받음 - 해서나쁠거는 없으므로 스케일링, 인코딩을 하는것이 바람직해보임 한것과 안한것을 비교하는게 좋음과적합예
-
-
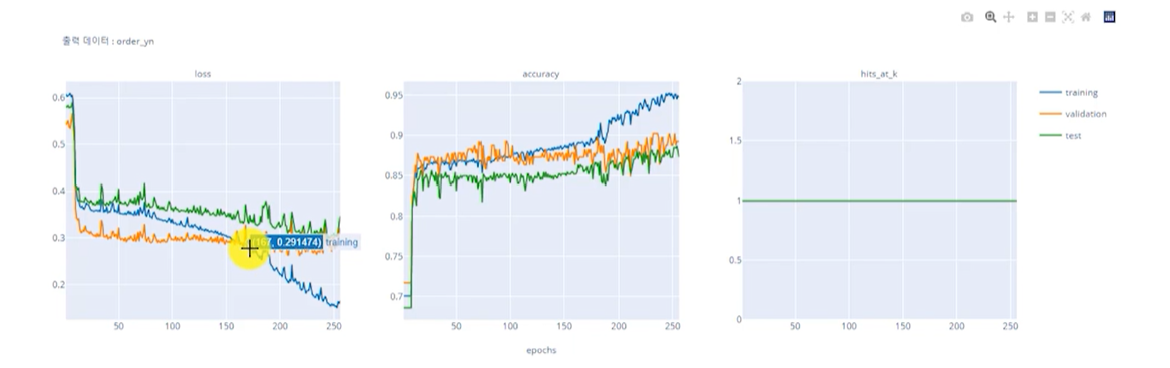
옳은예

Back-end Developer를 목표로 하고 있는 전진구입니다.