Apache Kafka
- 분산형 이벤트 스트리밍 플랫폼
- 고속으로 데이터를 전송, 저장 및 처리 가능
- 대용량의 실시간 데이터 스트리밍을 처리하기 위해 개발되었으며, 주로 로그 수집, 메시지 큐잉, 실시간 분석 등의 용도로 사용
기본 구조
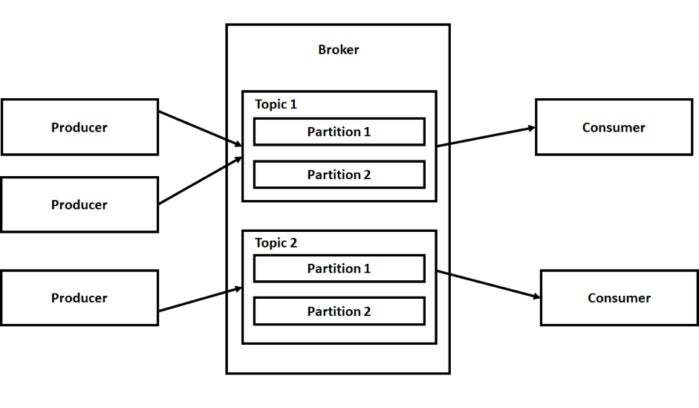
1. 프로듀서(Producer)
- Kafka에 메시지를 발행하는 역할
- 다양한 데이터 소스에서 데이터를 수집하여 Kafka의 특정 토픽에 메시지를 발행
2. 컨슈머(consumer)
- Kafka에서 특정 토픽을 구독하고, 해당 토픽의 메시지를 읽어가는 역할
- 하나 이상의 토픽을 구독할 수 있으며, 토픽의 파티션을 동시에 소비할 수 있음
3. 토픽(Topic)
- Kafka에서 데이터를 분류하는 단위
- 프로듀서는 메시지를 특정 토픽에 발행하고, 컨슈머는 토픽을 구독하여 메시지를 소비함
- 토픽은 여러 파티션으로 나뉘어질 수 있고, 이를 통해 데이터를 병렬로 처리할 수 있음
4. 파티션(Partition)
- 토픽의 논리적 분할 단위
- 각 파티션은 순서가 보장된 메시지 스트림을 제공하며, 브로커가 클러스터 내에서 파티션을 분산하여 저장
5. 브로커(Broker)
- Kafka의 핵심 컴포넌트로, 프로듀서로부터 메시지를 받아 저장하고, 컨슈머에게 메시지를 전달하는 역할
- 다수의 브로커가 모여 클러스터를 형성하며, 높은 가용성과 내결함성을 제공
6. 클러스터(Cluster)
- 여러 대의 브로커가 모여 하나의 Kafka 시스템을 구성하는 집합체
- 데이터의 복제와 분산 처리를 통해 안정성과 확장성을 높임
주요 특징
1. 고가용성
- 데이터 복제를 통해 장애가 발생해도 데이터 손실 없이 운영을 지속할 수 있다.
2. 확장성
- 브로커와 파티션을 추가함으로써 손쉽게 확장이 가능
- 수평 확장을 지원하여 대규모 데이터 처리에 적합
3. 내결함성
- 복제와 분산 처리로 장애 발생 시에도 데이터 유실을 최소화하고 시스템의 안정성을 보장
.4 높은 처리량
- 고성능 데이터 처리 엔진을 통해 초당 수백만 건의 이벤트 처리가 가능
- 배치 처리 및 실시간 스트리밍 처리 모두를 지원
5. 유연한 데이터 처리
- 스트림 프로세싱 라이브러리인 Kakfa Streams를 통해 실시간 데이터 처리를 지원하며, 다양한 데이터 파이프라인을 구성할 수 있음
사용 사례
- 로그 및 이벤트 수집
- 애플리케이션 로그, 사용자 활동 로그 등을 실시간으로 수집하고 분석할 수 있음
- 메시지 큐
- 분산 메시지 큐로서, 시스템 간의 비동기 통신을 지원
- 실시간 분석
- 실시간 데이터 스트림을 분석하여 실시간 대시보드나 경고 시스템을 구축할 수 있음
- 데이터 통합
- 다양한 소스의 데이터를 중앙 집중화하여 데이터 웨어하우스나 데이터 레이크로 통합할 수 있음
Apache Kafka는 데이터 처리 및 실시간 스트리밍 요구를 충족시키기 위해 설계된 강력한 플랫폼이다. 이를 통해 기업은 데이터를 실시간으로 수집, 처리, 분석하여 비즈니스 인사이트를 도출할 수 있다.
Apache Kafka와 Apache Zookeeper의 관계
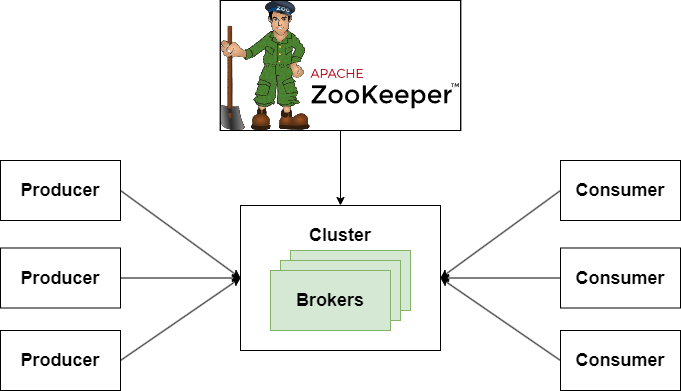
Apache Kafka와 Apache ZooKeeper는 초기부터 긴밀하게 통합되어 작동해 왔으며, Zoopeeker는 Kafka의 클러스터 관리와 메타데이터 관리를 담당하는 중요한 역할을 수행했다.
그러나 최신 버전의 Kafka는 KRaft 모드를 도입함으로써 Zoopeeker에 대한 의존도를 줄이고 자체적인 메타데이터 관리 기능을 제공하기 시작했다. 이는 Kafka의 운영을 단순화하고, 일관성을 향상시키며, 운영 부담을 줄이는 데 기여하고 있다.
