TIL_46.md
고통의..습작
살려주세요
-
Collection : 순서 집합 저장공간
- 특징 : 일관된 api
일관된 method
- 특징 : 일관된 api
-
Garbage collection 의 구조 :
필요없어진 메모리(원시값, 객체 함수 모두 메모리차지 하는 모든것?)을 자동 삭제해 준다- 특징 : 접근가능한 value 가 아닌 접근 불가능 상태의 값을 제거!
Reachablity
Java Garbage Collection - 누구세요? : background process in the JavaScript engine / 자바에서는 다르게 정의
- 어떻게 쓰임 ?
자동적 수행, 보이진 않음. 때문에 강제할 수 없음.
- 특징 : 접근가능한 value 가 아닌 접근 불가능 상태의 값을 제거!
-
example code
let user = {
name: "John"
};
user = null;- 시각화
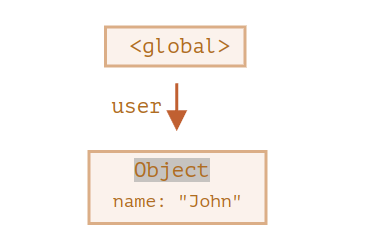

Reference에 따라 논리구조를 자동으로 인식해 삭제를 해줄수도 있다
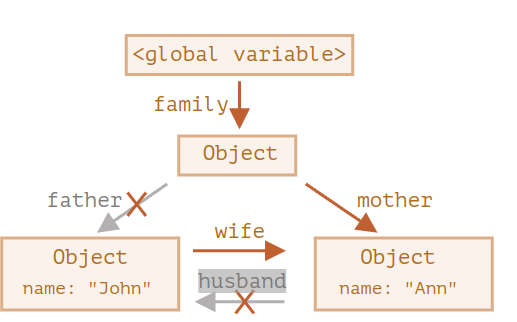
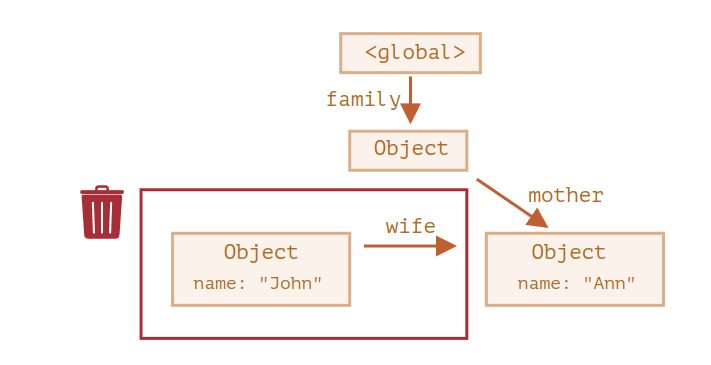
- 주의할 점 :
Being referenced is not the same as being reachable (from a root): a pack of interlinked objects can become unreachable as a whole.
참고된다는 것이 꼭 root 노드로부터 접근 가능한 상태인 것은 아니다! join된 객체 압축 저장소(?) 또한 전체가 접근 불가능 상태가 될수도 있음.
List : 선형구조, '선'이라서 데이터를 조회할 때, 순서가 있다.
SET : 중복이 안됀다. 알고리즘내 obj <-> array 병용해서 쓸때
Queue: FIFO
MAP : 키 -값 구조, 키는 중복 불가 값 - 데이터 중복 가능
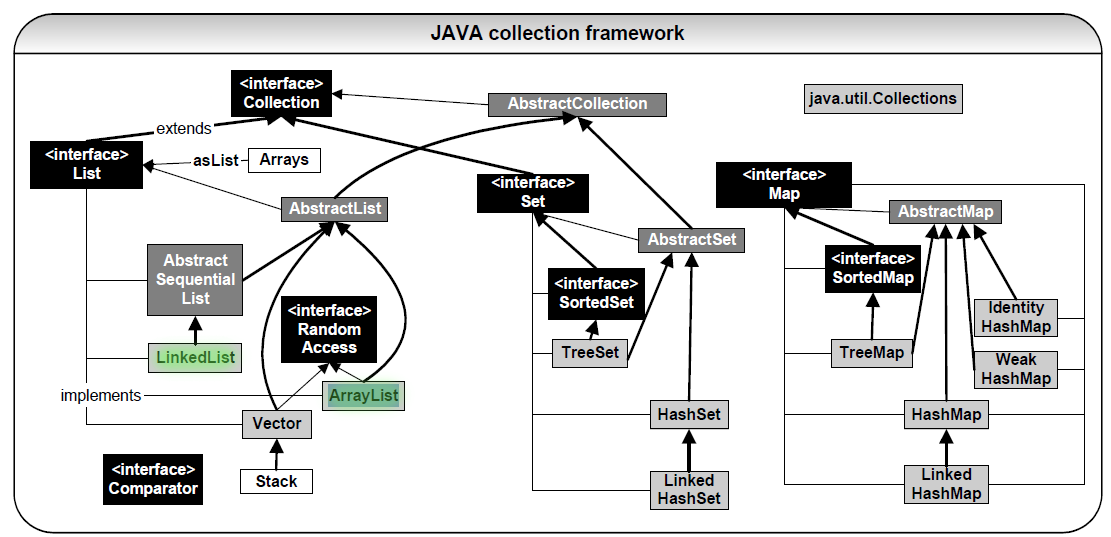
list
-
linkedlist vs ArrayList
-
arraylist : 동적
- 특징 : 배열에서 많은 움직임이 필요할때
- 장점 : 인덱스를 이용해 데이터에 접근하기 때문에 배열의 크기와 관계없이 O(1)시간 내에 빠르게 데이터에 접근할 수 있다
-
Linkedlist : 정적
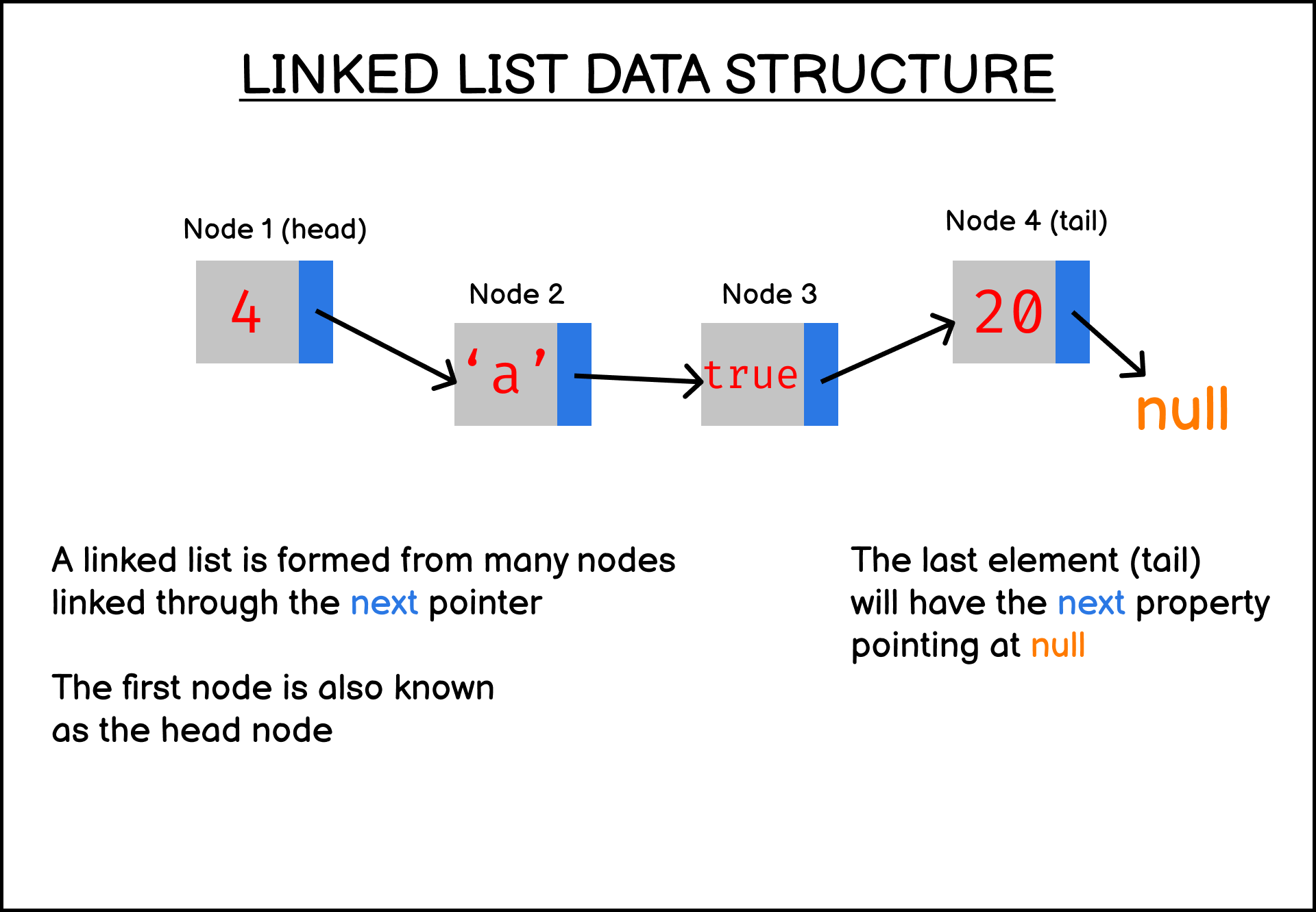
-
특징 : 각 요소를 노드라 부른다 (
왜죠?)- 노드 뜻 : 기초적인 단위이다. 노드는 대형 네트워크에서는 장치나 데이터 지점(data point)을 의미한다. 개인용 컴퓨터, 휴대전화, 프린터와 같은 정보처리 장치들이 노드이다. 인터넷에서 노드를 정의할 때 노드는 IP 주소를 보유한 어떠한 것도 될 수 있다. (출처:위키)
-
장점:
- 비어 있는 메모리에 꼭 맞는 각각의 데이터들을 따로따로 저장해주기 때문에 메모리를 낭비할 가능성이 적다
- 데이터 추가 : 참조자만 바꾼다, 새로 메모리 할당후 빠르게 수행, 위치와 관계가 없음
- 데이터 삭제 : 참조자만 삭제, 메모리 낭비없이 효율적 처리, link만 끊어낸다
-
단점 :
표준 배열 보다 느릴수 있다- 순차적으로 첫 번째 값부터 다음 값들을 타고 가야하기 때문에 데이터에 접근하는데 있어서
O(n)의 시간 복잡도가 걸림.
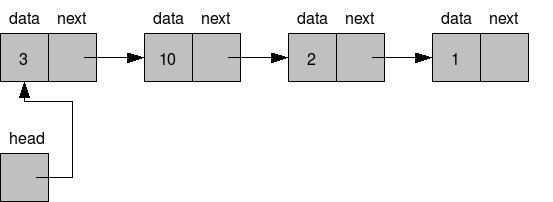
- 순차적으로 첫 번째 값부터 다음 값들을 타고 가야하기 때문에 데이터에 접근하는데 있어서
-
특징
- 노드 /헤드 /테일
- 포인터 = 참조값 (인덱스..?)
- 주소 참조 = 노드 저장
- 알고리즘: 트리, 그래프
배열
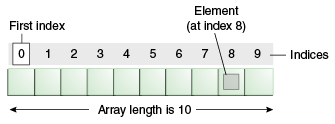
-
특징
- 정적 배열 /동적 배열
- 정적: 크기를 바꿀 수 없는 자료구조
- 동적 : 크기 바꾸기 쌉가능
- 인덱스 넘버를 활용할 수 있다.
- 길이가 고정되서 그 길이 이상이 되는 자료를 왠만해선 사용할 일이 없다 = rdbms 에 최적화?
- 연속된 데이터를 아무 가공없이 임시로 저장하는 장소로 사용한다.
-
시간 복잡도 (동적 배열 기준, index 사용시 가정 )
-
사이즈를 늘이는 2가지 경우
- 하나씩 늘이는 경우 : 메모리 최적화 , 시간복잡도 증가
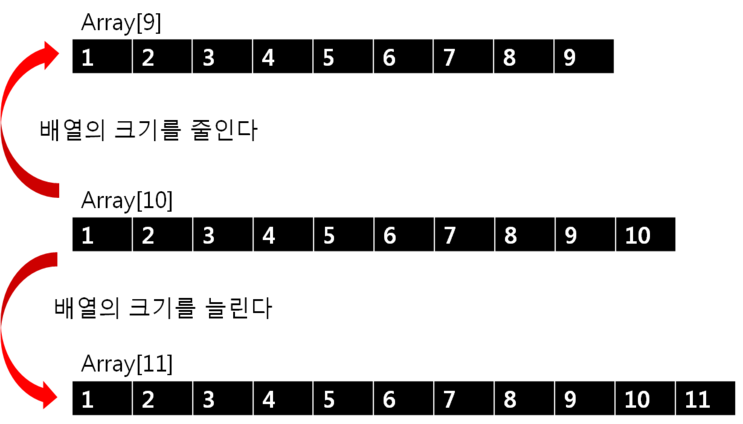
- 크기를 늘려야 될 상황 : size를 2배로 늘이는 경우
- 삭제시 1개씩 줄인다 / ? 이유는 확인중..
- 하나씩 늘이는 경우 : 메모리 최적화 , 시간복잡도 증가
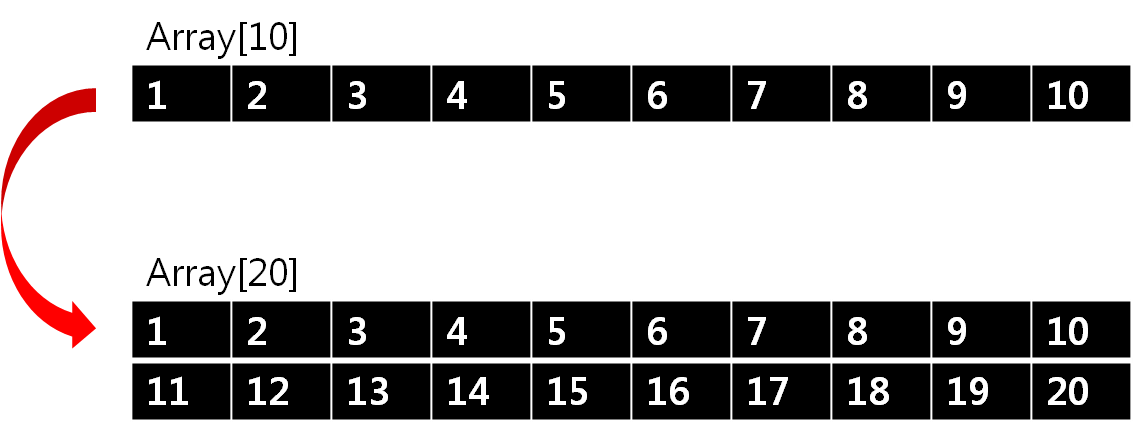
-
Default : 정적 배열의 시간복잡도와 똑같습니다.
-
내부적으로는 동적 배열도 정적배열을 사용하고 있는 것
-
데이터 접근, 저장시에는 O(1)이, 데이터를 탐색하는데는 O(n)이 걸린다.
- 검색
주소값을 설사 모르더라도 인덱스 넘버로 접근할 수 있기 때문에 특별한 알고리즘없이 한번만에 접근할 수 있습니다.
시간복잡도: O(1)로 최적의 효율 - 갱신
시간 복잡도 : O(1)로 최적의 효율 - 추가
- 배열에 아직 데이터를 저장할 수 있는 공간이 존재해 배열의 길이를 늘려줄 필요가 없을 때
임의접근방식으로 마지막으로 저장된 데이터 값에 접근해 그 뒤에 데이터를 저장하면 되므로O(1) - 배열이 꽉 차서 더 긴 새 배열을 만들어줘야 할 때
삽입은O(1)이지만, 이미 있던 데이터를 전부 밀어버려야 해서O(n)
- 배열에 아직 데이터를 저장할 수 있는 공간이 존재해 배열의 길이를 늘려줄 필요가 없을 때
- 삭제
정의 :그 뒤의 값들이 삭제된 데이터를 덮어쓰는 과정
하나를 삭제하면 그공간만큼을 당겨야 함으로O(n)
- 검색
-
요약 : 정적 배열에서 하지않는 배열을 삭제 / 추가하는 작업 = 시간복잡도 상승
- 비교:
- 동적 배열 ) arraylist
- 데이터 추가 삭제 arraylist < linkedlist
(linkedlist에서 맨 뒤의 값에 다음 값의 주소정보를 추가 ,삭제만 해주면 되므로 시간복잡도O(n)) - 데이터 검색 arraylist>linked list

🏠TECH & GOSSIP