status
...그러하다
급하게 낸 intership 지원서를 읽어보신 ai 멤버분들과 인터뷰가 있었다.
다행히 친절하셨다. 그 쓰레기같은 이력서를 봐주시다니...
여러 직군을 채용중이시던데,...
정규직 채용 지원했더라면 떨어졌으려나.
과연 내가 인턴으로 들어가서
원하는 직군을 가져 올 수 있을까.
또다시 나를 증명해야 할 시간
여러 학원을 뛰며 시범강의를 하며 고등부 강사로 도전하던 옛날 경험이 생각났다.
원래 스타트업이 그렇겠지만 다들 일당백 하실테니까.
생각보다 만만치 않겠구나
쉽지않은 시장이다.
... 그러하다
AS-IS
- 기존 flask에서 내가 쓴 loggin은 주로 아래와 같음
logger = setup_logger(__name__) # JSON 데이터 출력 (디버깅용) logging.info(f"Received data: {data}") except Exception as e: # 예외 발생 시 500 응답과 에러 메시지 반환 logging.error(f"Exception occurred: {str(e)}") return jsonify({"error": str(e)}), 500 - 처음엔 logging 도 스크립트 짜서 쓰려고 했는데 대실패.
- /utils/custom-logger 의 장점을 잘 못 느꼈다.
import logging있는 라이브러리 갖다쓰는게 어짜피 custom loggin 에러핸들링하며 만들어 쓰는것보다 시간이 덜 들었음
- /utils/custom-logger 의 장점을 잘 못 느꼈다.
- 기존 custom loggin//
alembic 쓰면서 자동으로 생성된 듯함
import logging
from logging.config import fileConfig
from flask import current_app
from alembic import context
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
# Interpret the config file for Python logging.
# This line sets up loggers basically.
fileConfig(config.config_file_name)
logger = logging.getLogger('alembic.env')
def get_engine():
try:
# this works with Flask-SQLAlchemy<3 and Alchemical
return current_app.extensions['migrate'].db.get_engine()
except (TypeError, AttributeError):
# this works with Flask-SQLAlchemy>=3
return current_app.extensions['migrate'].db.engine
def get_engine_url():
try:
return get_engine().url.render_as_string(hide_password=False).replace(
'%', '%%')
except AttributeError:
return str(get_engine().url).replace('%', '%%')
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
config.set_main_option('sqlalchemy.url', get_engine_url())
target_db = current_app.extensions['migrate'].db
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def get_metadata():
if hasattr(target_db, 'metadatas'):
return target_db.metadatas[None]
return target_db.metadata
def run_migrations_offline():
"""Run migrations in 'offline' mode.
This configures the context with just a URL
and not an Engine, though an Engine is acceptable
here as well. By skipping the Engine creation
we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the
script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url, target_metadata=get_metadata(), literal_binds=True
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online():
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
# this callback is used to prevent an auto-migration from being generated
# when there are no changes to the schema
# reference: http://alembic.zzzcomputing.com/en/latest/cookbook.html
def process_revision_directives(context, revision, directives):
if getattr(config.cmd_opts, 'autogenerate', False):
script = directives[0]
if script.upgrade_ops.is_empty():
directives[:] = []
logger.info('No changes in schema detected.')
conf_args = current_app.extensions['migrate'].configure_args
if conf_args.get("process_revision_directives") is None:
conf_args["process_revision_directives"] = process_revision_directives
connectable = get_engine()
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=get_metadata(),
**conf_args
)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
- ts 의 인터페이스 처럼 component 화 해서 가져다 쓰는 util이라고 이해했는데 명제는 아래와 같다고 함
로깅은 어떤 소프트웨어가 실행될 때 발생하는 이벤트를 추적하는 수단입니다. 소프트웨어 개발자는 코드에 로깅 호출을 추가하여 특정 이벤트가 발생했음을 나타냅니다. 이벤트는 선택적으로 가변 데이터 (즉, 이벤트 발생마다 잠재적으로 다른 데이터)를 포함할 수 있는 설명 메시지로 기술됩니다. 이벤트는 또한 개발자가 이벤트에 부여한 중요도를 가지고 있습니다; 중요도는 수준(level) 또는 심각도(severity) 라고도 부를 수 있습니다. (Reference)
AI_loggin 이란 - ai 에서 message 보내는 eventTrigger 용 (lambda) 활용법 알아보기
Todo
- ai+ backend 공부
- 1순위 ) pytorch ,tensorflow, fast-api 에 대한 경험, logging 재확인 및 공부
- 동시 진행 ) regex, ai machine 관련 python 라이브러리 확인 및 공부
- 간단한 application/ 앱(ios) 웹 개발 및 적용
- java 도 쓰신다고 함 (이건 supercoding 사용하자!)
- 솔루션 이해 : datadog, airflow
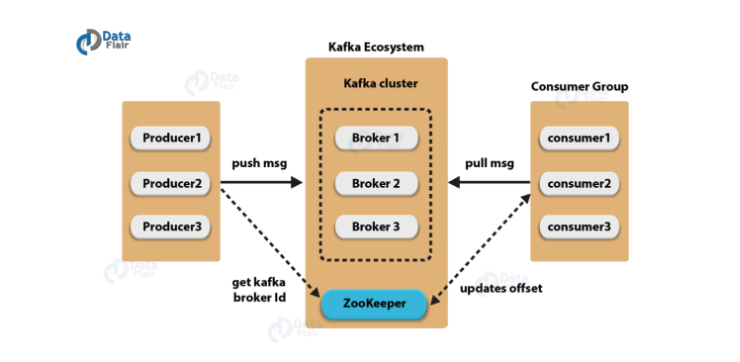
kafka
kafka
데이터 topic 여러개
topic 내 partition (메모리 파티션 나누는듯)
produce 처리해야 할 일 을 저장하는 database
partion 여러개로 병렬 처리 한다
병렬처리 =속도 빨라짐
여러 partition = node
각각의 offset (0x000?) 각각의 registry 공간에 data 넣음ㅁ
kafka consumer 토픽내 하나이상의 topic을 여러개 갖고옴
customer 은 worekrnode 임 자체적으로 추적하고, 중단된 phase 등 범위를 읽어옴 acid 하게 읽어온다고 함
데이터 관리 - control plain - kafka cluster broker들을 여러개 갖고있으 중개인 거래담당자가 여러개의 borker가 data partion 관리 / 복제/장애조치
처리량 안정성 ha 관리등 확장가능
zoo keeper kafka 분산 형상 관리 도구 topic 은 메타데이터raw data 임
구성, topic metadata, broker status, consumer group 관리 ,broker 관리 추가및 제거 topic 추삭 등 kafka
정확하게 말하면 partion
