goal:
- summerize가능한 ai모델 로컬 에서 써보기
ai model learning
naver cloava 활용
아쉽게도 대부분 ai 모델이 위와 같이 고급(?)기능을 제공하는 경우 유료임.
네이버 조차 정식 서비스 launching 후 신청해야
데모가 아닌 실제 활용가능한 모델 쓸 수 있었음..
매번 테스트 앱 키고 끄는게 번거로워 작동 테스트만 진행후 종료
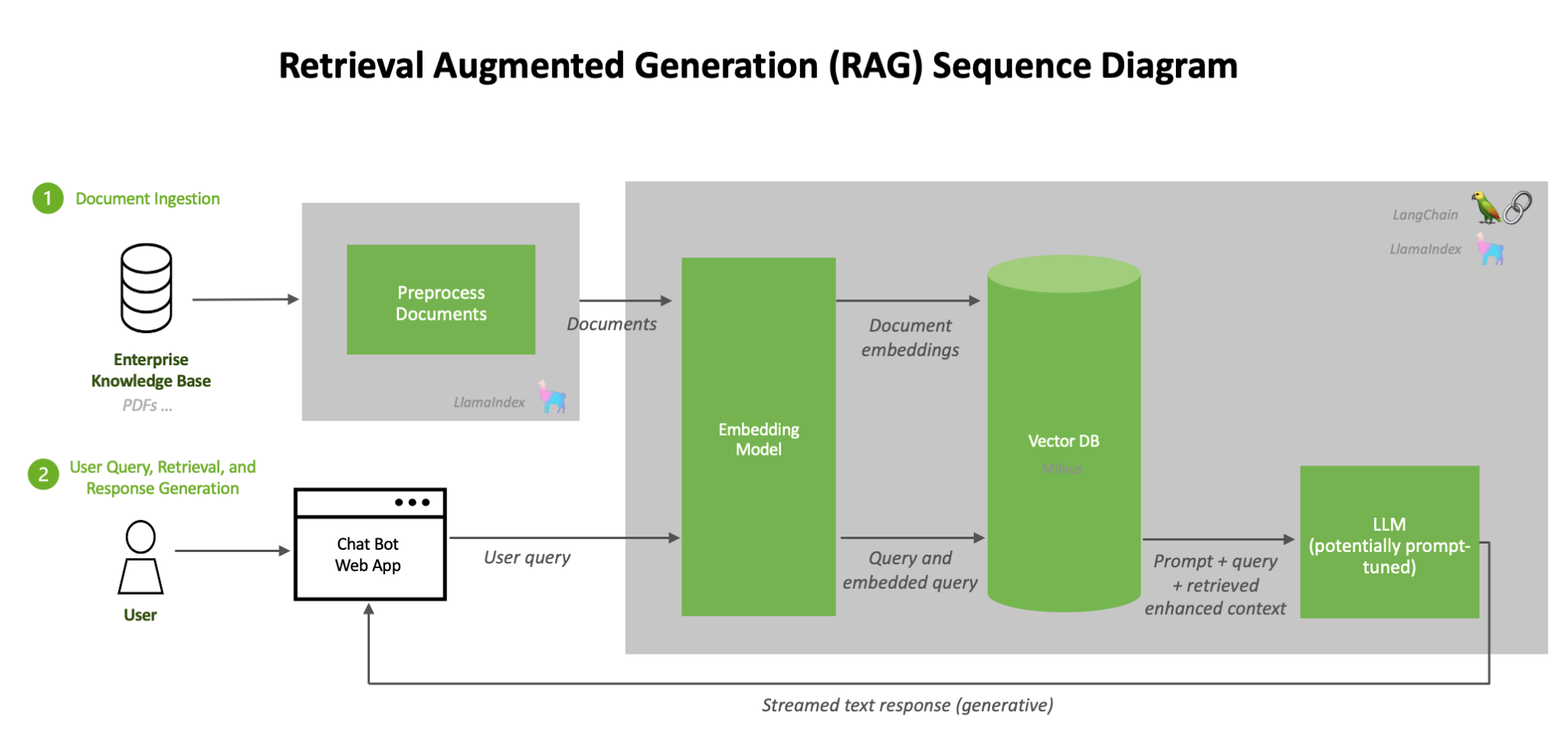
LLM 데이터 파이프라인의 일반적인 흐름
- 데이터 수집 및 전처리
다양한 소스에서 텍스트 데이터를 수집합니다1.
데이터 정제: 불필요한 문자 제거, 토큰화 등의 작업을 수행합니다 - 데이터 변환 및 강화
Tagging: 데이터에 메타데이터를 추가합니다.
Summarization: 긴 텍스트를 요약합니다.
Translation: 필요한 경우 다른 언어로 번역합니다. - 모델 처리
LLM 모델을 통해 데이터를 처리합니다.
결과를 정제(Refine)하고 평가(Estimate)합니다. - 데이터 전송 및 저장
처리된 데이터를 Kafka 등의 메시징 시스템을 통해 전달합니다.
필요한 경우 데이터베이스에 저장합니다. - 모니터링 및 피드백 루프
모델 성능을 지속적으로 모니터링합니다.
필요한 경우 모델을 재학습하거나 파인튜닝합니다.
- 각 모델별 스크립트가 짜여있길래 왜 굳이 모델이 있는데 또 kafka에서 처리를 하나라는 의문이 있었는데
기능분리를 한 것으로 이해됨
다만 해당 ai모델의 파이프라인 + pub/sub하는 kafka의 유기적인 관계다 보니, 각 ai 알고리즘이 잘 작동하는게 핵심임.
위 모델이 작동여부에 따라 양질의 데이터가 잘 consume 되고 produce 할 수 있었다.
ai model 활용 예시
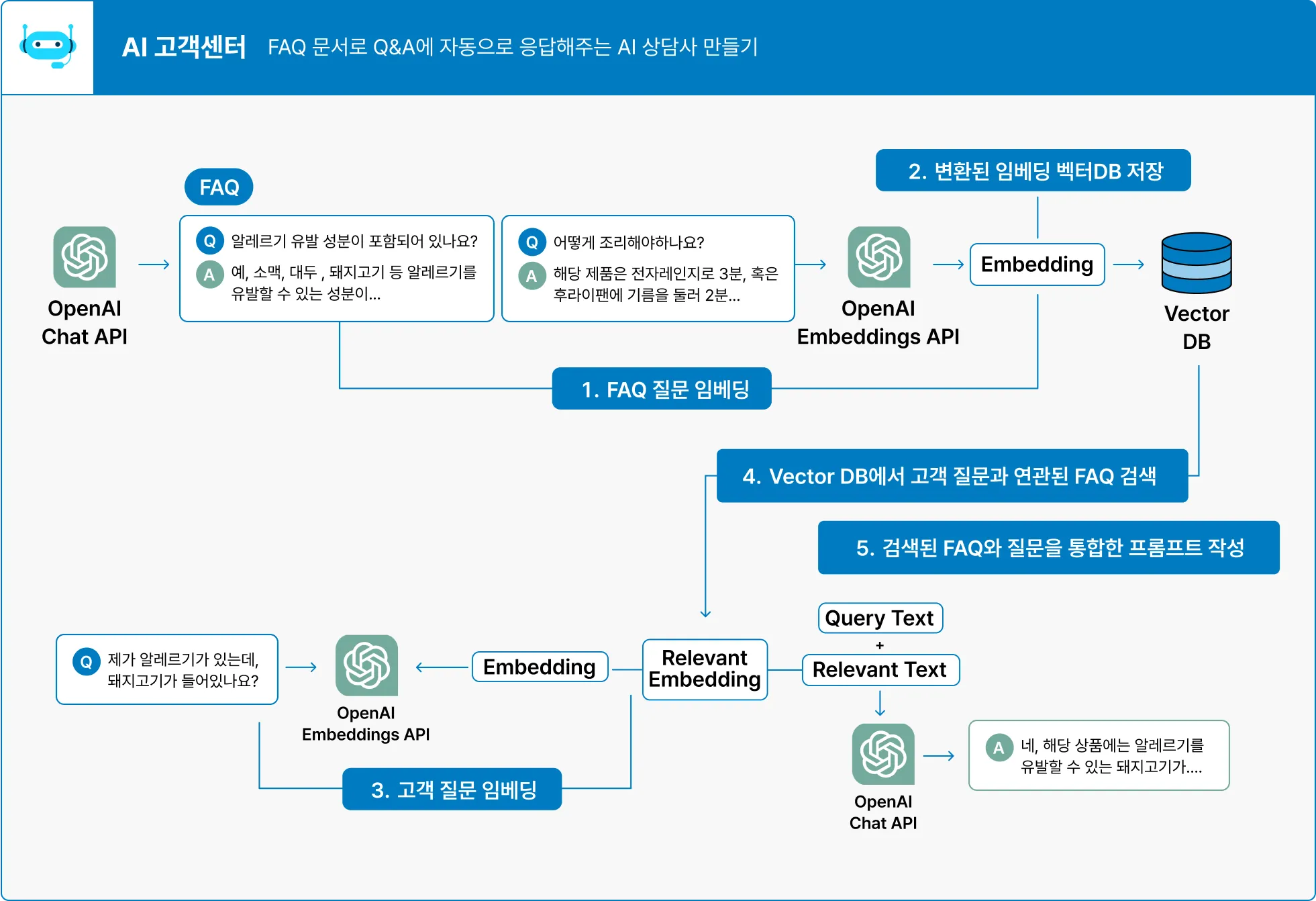
프롬프트를 받아와서 이미 한번 model에서 promt 에 맞게 작동함
query: 왜 Rule 이 필요할까
ai 모델이 생각보다 양질의 데이터를 프롬프트를 써도 잘뽑아내진 못한다고 한다 (현직자 말씀)
전처리를 해도 + 후처리를 통해 한번더 필터링하는 듯.
(이게 fine tuning인가)
그외
kafka debug
-
그룹 아이디 추가하는 이유 : 컨슈머 그룹 내에서 컨슈머 간 메시지 분배 관리
-
ERR ) consumer가 offset을 못 읽는 에러 발생.
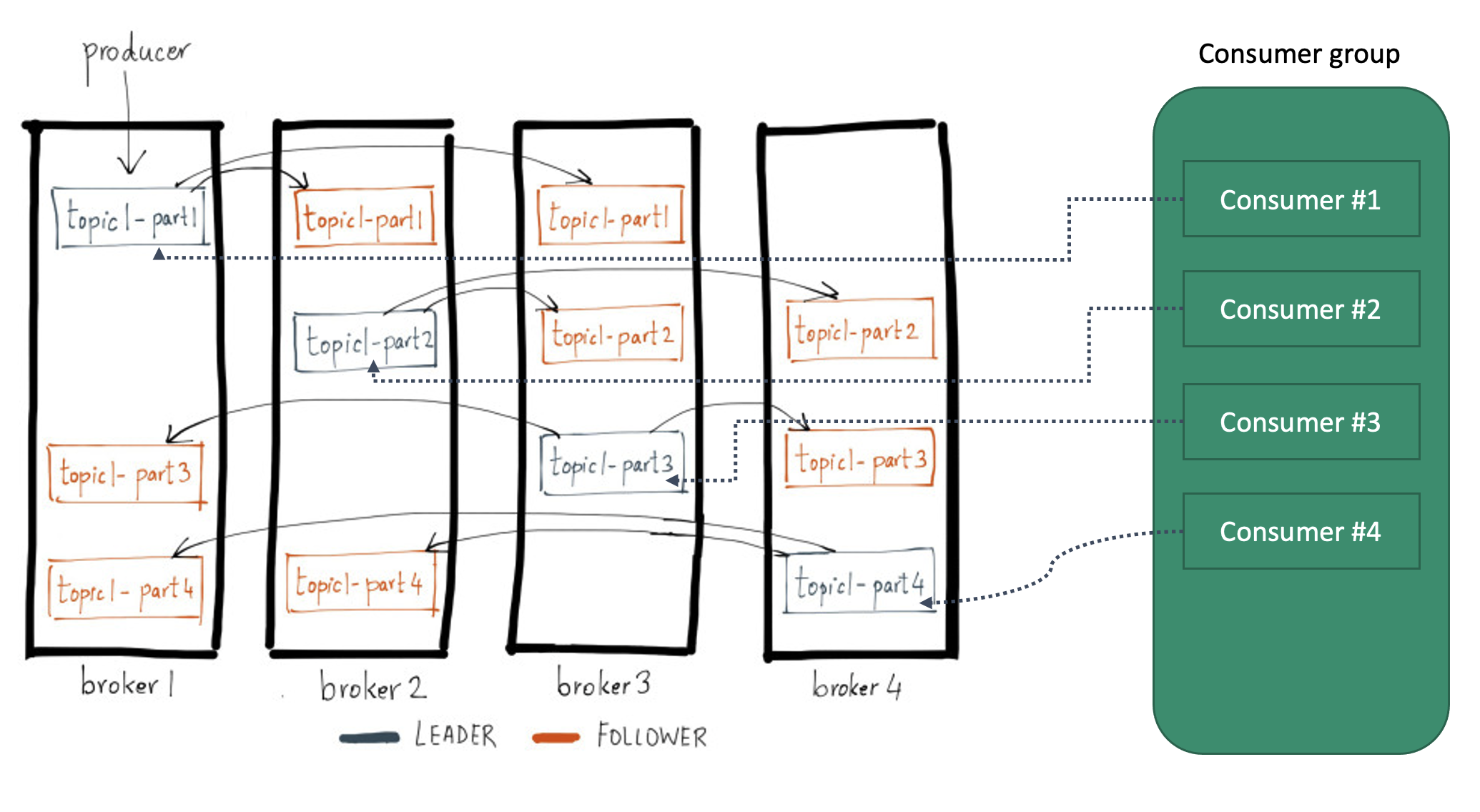
- debug_1 offset 및 partition 확인필요
- offset 끼리 비교해서 강제로 이동 조건
- offset 이 안바뀌어서 수동으로 옮기는 중/ 이후 offset 을 추적하지 않아도 아래 설정으로 바꾸니 문제해결
for topic_partition in self.consumer.assignment():
current_offset = self.consumer.position(topic_partition)
end_offset = self.consumer.end_offsets([topic_partition])
if current_offset < end_offset:
all_offsets_reached = False
break
if all_offsets_reached:
self.logger.info("모든 메시지 처리 완료: poll loop 종료")
break
else:
self.logger.info("poll 대기 중")
await asyncio.sleep(1)
continue
all_offsets_reached = True
auto.offset.reset = earliest(처음부터 읽는다) / latest/ noneoffset 추적 로직
모든 조건 통과시 메시지 전달 (polling time , message data가 실제할 경우등)
중복이 아닌 메시지만 처리 예약(목표)
topic, record.offset 두 키로 현재 처리 중인 메시지 기록 후 중복 메시지 스킵
OrderDict로 처리 순서 유지하며 관리
record.value를 직접 task에 append 시 processed_offset에서 중복 확인 어려움
중복 여부는 topic pattern, offset 기준으로 확인
record.value로는 중복 확인 어렵고, 처리 완료 후 커밋할 오프셋 특정 어려움 (value 만 나오므로)
consumer commit 메시지와 처리된 레코드(pre_record) 간 정확한 일치 불가능
비동기 작업과 프로듀서 작동 간 타이밍 문제 발생 가능성 높음 (asyncio, kafkaproduce간)
process_offsets 크기 관리 실패 시 메모리 누수 가능성 있음
이러한 이유로 별도의 method 필요
logger에 디버그 용 코드 추가 exc_info=True
코루틴
async def process_record(self, data):
try:
value =data.value
self.logger.info(f"Processing record: {value}")
await asyncio.sleep(0.1) 처리 시간 예제
return value
except Exception as e:
self.logger.error(f"Error processing record: {e}")
return None
코루틴 객체를 프로듀서에 전달
task는 튜플임으로 언패킹 연산자 이용하여 개별인수로 분리후 함수에 전달
비교
1. create_tasks
사용해보니 create_tasks 사용시 중복관리 세밀한 디버그 가능 대신 예외처리및 각 코드가 길어짐
create_tasks 사용시 중복관리 세밀한 디버그 가능 대신 예외처리및 각 코드가 길어짐
특징
- 개별 태스크 생성: create_task를 통해 각 메시지를 비동기 작업으로 즉시 예약.
- 중복 확인 용이: record 자체를 tasks에 추가하므로 processed_offsets를 통해 중복 여부를 명확히 판단.
- 디버깅 및 로깅: create_task 생성 시 즉시 로깅 가능, 작업 진행 상황을 세밀히 추적 가능.
- 타이밍 문제 해결: 메시지를 처리하면서 태스크의 실행 타이밍을 세밀히 조정 가능.
장점
- 디버깅 편리성: 각 태스크가 명시적으로 생성되어, 로깅과 디버깅이 간편.
- 중복 관리: processed_offsets와 연계해 정확히 관리 가능.
- 실시간 실행: 메시지를 처리하는 동시에 태스크가 예약되어, 이벤트 루프의 활용도가 높아짐.
단점
- 코드가 비교적 장황.
- asyncio.create_task로 태스크를 관리하려면 추가 코드가 필요.
- gather(tasks*)
tasks = [self.process_record(record) for record in records]
results = await asyncio.gather(tasks)
특징
- 태스크 리스트 생성: 리스트 컴프리헨션을 사용해 모든 코루틴을 한 번에 리스트로 생성.
- 간결한 코드: tasks에 코루틴 객체를 추가하고 한 번에 실행.
- 로깅 제한: 개별 태스크 생성 시점에 로깅이 어려움. 코루틴 내부에서만 가능.
장점
- 코드 간결성: 한 줄로 코루틴 리스트 생성 및 실행.
- 유지보수 용이: 코드 재활용성과 가독성이 높아짐.
- 성능 차이 없음: asyncio.create_task와 동일하게 비동기 실행.
단점
- 디버깅 불편: 태스크 생성 단계에서 로깅이 제한됨.
- 중복 관리 복잡: record 자체를 추가하는 경우, processed_offsets와의 연결이 불분명.
- 타이밍 제어 부족: 태스크가 예약되지 않고 실행이 gather 시점에서 시작됨.
그외
Gather , unpacking comprehension 사용
Orderdict :
- 메시지 순서대로 처리해줌 k- v.쌍으로
Output
([('key','value'),('key','value'),('key','value')])query: 메시지는 왜 유실될까?
