데이터베이스 Pool
connection pool
thread에서 DB에 접근하려면 connection이 필요하다. connection pool은 connection을 여러개 생성해놓고 필요할때마다 꺼내서 쓰는 기법, 또는 connection을 저장해놓은 공간(캐시)를 말한다.
DB 접근 단계
-
web컨테이너가 실행되면 DB와 연결된 connection 객체들을 생성하여 pool에 저장한다.
-
DB에 요청 시, pool에서 connection 객체를 가져와서 DB에 접근한다. 이때 connection이 부족하면 대기한다.
-
끝나면 pool에 반환한다.
장점
-
매 연결마다 connection 객체를 생성하고 소멸시키는 비용을 줄일 수 있다.
-
미리 생성된 connection을 쓰므로 DB 접근시간을 단축시킨다.
-
connection 수를 제한해서 메모리와 DB에 걸리는 부하를 조정한다.
단점
- connection 수가 정해져 있어서 많은 DB요청이 들어오면 대기 시간이 길어진다.
Thread Pool
connection pool처럼 미리 생성한 thread를 저장해두고 재사용한다.
WAS에서의 thread pool, connection pool
was에서 thread pool과 connection pool 내의 thread와 connection의 수는 직접적으로 메모리와 관련이 있으므로 많이 쓰면 쓸 수록 메모리를 많이 점유하게 된다. 그렇다고 적게 저장하면 server에 많은 요청이 들어올 때 latency가 심하게 생긴다. (자원이 부족하여 대기하므로)
보통 thread 수가 connection수 보다 많은게 좋다. 모든 요청이 DB 작업이 아니기 때문이다.
Transaction
DB 상태를 변환시키는 하나의 논리적인 작업 단위이다. 하나의 transaction은 commit 되거나 rollbak되어야 한다.
transaction -> tr로 줄이겠다.
-
commit: tr에 대한 작업이 성공적으로 끝나 DB와 다시 일관된 상태에 있을 때, tr 관리자에게 알려준다. db buffer의 내용을 실제 db에 반영
-
rollback: tr이 비정상적으로 종료되어 db의 일관성이 깨졌을 때, 그전가지 행한 연산을 undo 하는 것이다. atomicity을 지키기 위함이다.
Transaction의 ACID
-
atomicity(원자성): 모든 연산이 commit되거나 rollback 되어야 함. 모든 연산이 수행되거나 다 취소되거나.
-
consistency(일관성): tr 후에 DB가 일관된 상태를 유지해야 한다.
-
isolation(독립성): tr가 실행 도중에 변경한 data는 tr이 완료되기 전까지 다른 tr들이 참조할 수 없다.
-
durability(내구성): 예기치 못한 시스템 장애 또는 정전 시 마지막으로 알려진 상태로 복구하는 기능을 필요로 합니다.
Transaction 격리수준
Isolation Level: tr에서 일관성이 없는 data 허용하도록 하는 수준. atomicity와 isolation을 수행하기 위함이다.
locking에는 shared lock과 exclusive lock이 있다.
-
shared lock: 읽기 잠금, s lock은 추가 가능, x lock은 불가능
-
exclusive lock: 쓰기 잠금, s lock과 x lock 둘 다 추가 불가능
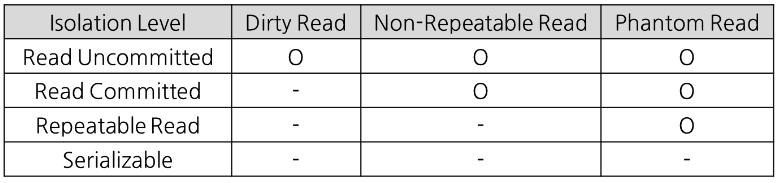
먼저 consistent read의 개념을 잡고 가자. select을 수행할 때 현재 db가 아닌 특정시점 db의 스냅샷을 읽어오는 것을 말한다. 이때 스냅샷에는 commit된 내용만 적용된다.
이를 구현하기 위해서는 row를 읽어올 때마다 lock을 걸면 간단히 해결되지만 동시성이 사라져 성능문제가 심각해진다. InnoDB에서는 쿼리를 수행할 때 마다 log를 저장하고, consistent read할 때 이 log를 통해 특정시점의 db의 스냅샷을 복구하는 방법을 사용한다.
-
Read uncommitted: 각 tr의 변경 내용을 commit이나 rollback에 상관없이 다른 tr에서 값을 읽을 수 있다. select연산을 수행하는 동안 해당 data에 s lock이 걸리지 않는 level 이다.
-
Read committed: commit이 이루어진 transaction만 조회가 가능하다. select 수행하는 동안 해당 data에 s lock이 걸리는 level
read committed에서는 트랜잭션으로 select연산을 수행할 때와 그냥 수행할 때 차이가 없지만 repeatable read에서는 차이를 보인다. 따라서 repeatable read 격리수준에서는 트랜잭션 범위 내애서만 select 쿼리가 작동한다. 트랜잭션 시작시점을 기준으로 스냅샷 저장. 이러한 것을 안지키면 데이터의 정합성이 깨지게 되고 이로 인해 버그가 생기면 찾기가 쉽지않다.
- repeatable read: MySQL에서 기본으로 사용되는 격리수준. 반복해서 read operation을 수행하더라도 읽어 들이는 값이 변화하지 않는 정도의 isolation을 보장하는 level이다. tr은 처음으로 select을 수행한 시간을 기록한다. 그리고 그 이후에는 모든 select 마다 해당 시점을 기준으로 consistent read를 수행한다. 그러므로 tr 도중 다른 tr이 commit 되더라도 새로이 commit 된 데이터는 보이지 않는다. 첫 read 시의 snapshot을 보기 때문이다. InnoDB기준으로는 Phantom read가 일어나지 않는다. 해당 tr이 참조할 수도 있는 모든 data에 gap lock을 걸기 때문.
innoDB 스토리지 엔진은 트랜잭션이 Rollback될 가능성에 대비하여 변경되기 전 레코드를 undo 공간에 백업해두고 실제 레코드 값을 변경한다. 따라서 데이터를 변경할 때 해당 데이터를 만든 트랜잭션이 아직 실행중이면 undo 영역에 백업을 하는 것이다.(MVCC) 이것이 트랜잭션을 최대한 짧게 실행시켜야 하는 이유이다. undo 영역에 백업 데이터가 많아질 경우 db의 성능이 떨어질 수 있기 때문이다. 또한 undo 영역의 백업 data는 스토리지 엔진의 판단하에 불필요한 data를 주기적으로 삭제한다.
- seriaziable: 위의 표에 나타나는 모든 문제가 일어나지 않지만 성능문제가 나타나고 dead lock이 쉽게 발생할 수 있다. 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서 절대 접근할 수 없다. innoDB에서는 repeatable read에서도 이미 phantom read가 일어나지 않으므로 굳이 serializable을 사용할 필요성은 없어보인다.
MVCC(multi version concurrency control)
-
목적: 잠금을 사용하지 않고 일관된 읽기를 제공하는 것.
-
innoDB에서는 undo log를 사용하여 기능을 구현.
-
multi version의 의미는 하나의 record에 대해서 여러 개의 버전이 동시에 관리된다는 의미이다.
-
아직 commit 또는 rollback되지 않은 상태에서 다른 사용자가 작업중인 data를 조회하면 어떻게 조회할까? -> 격리 level에 따라 다르다. read uncommitted에서는 버퍼 풀이나 disk에서 처리중인 data를 조회하지만 read committed 이상의 격리레벨에서는 undo 영역의 data를 반환한다.
-
즉 mvcc란 하나의 record에 대해 여러 버전이 존재하고 상황에 따라 특정 버전의 data가 선택되어 보여지는 구조이다.
Data Integrity(무결성)
data의 일관성, 정확성, 유효성이 유지되는 것으로 4가지 종류가 있다.
-
Entity integrity: 모든 table은 PK로 선택된 column을 가져야 한다. PK로 선택된 column은 unique하고 not null이어야 한다.
-
referential integrity: referential 관계에 있는 두 table의 data가 항상 일관된 값을 갖도록 유지한다. (밑에 외래키부분에서 다시 한번 다룬다.)
-
domain integrity: table의 각 column에 대한 integrity. data type, null 값 허용등에 관한 사항을 다룬다. 기본적으로 해당 column에 올바른 data가 들어갔는지 확인한다.
-
integrity rule: data integrity를 지키기 위한 모든 제약사항이다.
Key 종류
-
Super Key: row가 unique하게 지정되어야함. 이러한 성질을 만족하는 column들의 부분집합.
-
Candidate Key: Unique와 최소성을 만족하는 column의 부분집합. PK가 될 수 있는 후보들
-
Primary Key: Candidate Key 중에 선택된 Key, not null, 값이 자주 변경되지 않고 단순한 것을 선택한다.
-
Alternate Key: Candidate Key 중 PK를 제외한 모든 Key
-
Composite Key: 여러 column을 포함하는 Key
-
Foreign Key: 한 table의 Key 중에서 다른 table의 record를 유일하게 식별할 수 있는 Key
Foreign Key 특성
-
중복된 값, null 값 가능
-
참조되는 table에서 유일한 값의 column을 참조해야 함.
-
참조되는 table에 존재하는 값을 가져야 함. Null은 가능.
Foreign Key의 Referential Integrity
외래키를 지정할 때 Referential Integrity을 지키기 위해 필요에 따라서 몇가지 제한사항을 넣는다.
-
Restricted: record 변경/삭제 query가 들어왔는데 해당 record를 참조하는 개체가 있으면 query를 취소한다.
-
Cascade: record 변경/삭제 query가 들어오면 해당 record를 참조하는 개체도 변경/삭제 한다.
-
Set Null: record 변경/삭제 query가 들어오면 해당 record를 참조하는 개체에서 해당 값을 null로 변경한다.
Normalization(정규화)
목적 : table간 중복된 data를 허용하지 않는다. integrity를 유지하고 DB 저장 용량을 줄인다.
[DB] 8. 정규형 (1NF, 2NF, 3NF, BCNF)
-
삽입 이상(insertion anomalies) 원하지 않는 자료가 삽입된다든지, 삽입하는데 자료가 부족해 삽입이 되지 않아 발생하는 문제점
-
삭제 이상(deletion anomalies) 하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제점
-
수정(갱신)이상(modification anomalies) 정확하지 않거나 일부의 튜플만 갱신되어 정보가 모호해지거나 일관성이 없어져 정확한 정보 파악이 되지 않는 문제점
정규형: 특정 조건을 만족하는 테이블의 스키마 형태
1정규형: row의 모든 column이 atomic value
2정규형: pk를 제외한 모든 column이 pk에 완전 함수 종속
3정규형: pk를 제외한 모든 column이 그 외 다른 column을 결정할 수 없음
BCNF: 모든 determinant는 후보키여야함.
정규화의 단점
relation 분해로 인해 join 연산이 많이 필요해져서 query를 수행할 때 latency가 발생한다.
De-normalization (비정규화)
하나 이상의 table에 data를 중복 배치하는 최적화 기법이다.
시스템의 성능 향상, 개발 및 운영의 편의성을 위해 정규화된 data 모델을 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배하는 행위이다. [나무위키]
비정규화의 장점
-
select operation 과정에서 join연산이 적어져 처리속도가 빨라진다.
-
query가 간단해지면 버그가 생길 확률도 줄어든다.
비정규화의 단점
-
data를 수정/삽입 하는데 드는 비용이 증가한다. data가 여러 table에 중복 배치되어 있기 때문이다.
-
코드 작성도 어려워지고 일관성이 깨질 수도 있다.
-
중복되는 data만큼의 저장 공간이 더 필요하다.
비정규화는 언제 사용되는가?
-
disk에 I/O 요청이 많아져서 조회시에 성능 저하가 일어날 때
-
column 끼리 거리가 너무 멀어 join으로 인한 성능 저하가 일어날 때
대상
-
자주 사용되는 table에 access하는 process의 수가 가장 많고, 항상 일정한 범위를 조회할 때
-
성능상 issue가 있는 경우
-
join을 너무 많이 사용해서 data 조회가 기술적으로 어려운 경우
주의점
-
과도하게 적용하면 data integrity가 깨질 수도 있다.
-
update / insert / delete 시 여러 table에 대해 처리해야 해서 latency가 발생한다.
Indexing
개념 : 지정한 column을 기준으로 메모리 영역에 table에 대한 일종의 목차를 생성
사용 이유 : select operation 수행 시 indexing 이 없다면 완전 탐색을 해야한다. indexing을 하면 indexing column에 대한 index table을 따로 만들어서 O(logN)시간에 조회하고자 하는 row의 PK를 알아올 수 있다.
동작
1. index table(메모리)에서 where에 포함된 값 검색
2. 해당 값의 PK획득
3. PK 값으로 disk의 원본 table에서 값을 조회한다.왜 Hash table이 아니고 b+ tree인가?
Hash map은 동등연산자만 처리 가능하고 부등호 연산이 불가능 하기 때문
주의점
-
insert / update / delete가 많은 table에서는 b+ tree를 수정이 많이 일어나 오히려 성능저하가 생길 수 있다.
-
data 중복이 높은 column은 index로 만들어도 별 소용이 없다. 예를들어 성별같은 것이다.
다중 column indexing
-
cardinality가 높은 순서로 indexing 해야 효율적이다. cardinality가 높다는 뜻은 데이터 중복이 적다는 뜻이다.
-
다중 column indexing table에서 n번 째 column은 n-1번 째 column에 의존하여 정렬되어 있다.
-
index 성능의 향상은 disk에 얼마나 덜 접근하게 만드느냐, index root에서 leaf까지 오고가는 횟수를 얼마나 줄이냐 에 달려있다.
-
index는 공간을 차지하므로 너무 index가 많아지면 optimizer가 잘못된 index를 선택할 확률이 커진다. 따라서 3~4개 정도의 index가 적당하다.
-
여러 column으로 indexing 할 때 첫 번째 index만 where에 포함되면 문제없이 작동한다.
인덱스 키 값의 크기
InnoDB에서 disk에 data를 저장하는 기본단위는 Page이다. index도 Page 단위로 작동한다.
Page는 크기가 16KB로 고정되어 있다. 만약 본인이 설정한 index가 16B이고 자식노드 주소가 12B라면
16*1024 / (16+12) = 585로 하나의 Page에 약 585개의 data가 저장될 수 있다. 만약 index가 32B라면 같은 방식으로 계산했을 때 372개만 저장이 가능하다.
조회결과로 500개의 row를 읽어야 한다면 index가 16B 인 상황에서는 1개 Page로 조회가 가능했지만 32B 에서는 2개의 Page에서 읽어오므로 성능저하가 발생한다.
따라서 key 값의 크기는 최대한 작게 관리해야 한다. 키값이 커지는 경우 이전과 같은 성능을 나타내기 위해서는 b-tree의 depth가 깊어져야 하는데 이럴경우 디스크 읽기가 더 많이 필요해져 성능이 악화된다. 아무리 대용량 db여도 b-tree의 depthsms 5이상으로 깊어지기 힘들다.
클러스터 vs 논클러스터
