Blocking, Non-blocking & Synchronous, Asynchronous
정보량
I(x) = -logP(x) (log 밑은 2, P는 확률)
만약 x과 {0,1} 이라면 정보량은 1이다. 정보량의 단위는 bit로 정의한다. 이렇게 1 bit가 나온 것이다.
컴퓨터
data를 처리하는 기계
OS
컴퓨터 H/W를 다루는 S/W, application program과 H/W와 USER간의 중간 매개체, 명확한 정의는 없다. 하지만 가장 일반적으로 "the one program running at all times on the computer" 으로 불린다.
kernel
OS의 구성요소이며 system program과 application program으로 나뉜다.
bootstrap program
first program to run on computer power-on
-> disk에서 OS를 가져와서 memory에 올린다.
interrupt
I/O device와 CPU가 통신하는 방법
ex) 키보드 A를 누르면 이 사실을 CPU에게 알림
H/W는 system bus를 통해 interrupt를 언제든 발생시킬 수 있다.
Instruction Register
instruction 저장하는 register
mov, add 같은 애들
Data Register
data 저장하는 register
정수값 저장
-> 메모리에서 DR에 정수가져오고 IR에 add 가져와서 ALU에서 계산하여 결과를 다시 메모리에 저장
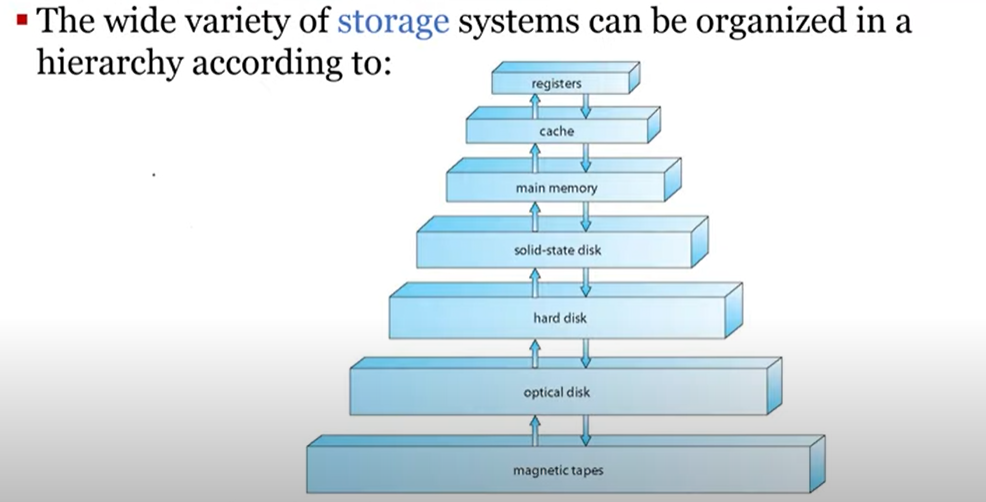
위로갈수록 빠르고 용량이 적음
multi programming
초기 컴퓨터는 cpu가 하나의 process를 처리완료 할 때가지 다른 process를 할당받지 못했다. multi programming은 process 처리 중간에 다른 process를 할당 받을 수 있게 하는 개념이다.
multitasking
CPU가 job을 계속해서 바꾸면 user 입장에서는 여러개의 process가 동시에 작동하는 걸로 느낀다. -> concurrency (뒤에 나오는 parrallelism과 비교해서 알아둘 것)
multiprocessing
여러 cpu로 작업을 동시에 처리하는것.
operation
- user mode: applicatoin 동작
- kernel mode: 중요한 h/w적인 작업은 kernel mode에서만 실행가능
-> incorrect한 program 동작을 막기위함
가상화
h/w 하나에 os 여러개 올리기

VMM: OS Scheduling 역할 ex) XEN, WSL(window system for linux)
User interface with the OS
- CLI(command line interface) -> cmd 창
- GUI(graphical user interface) -> windows, Mac os
- Touch-screen interface -> android, i-phone
프로그램은 OS와 어떻게 통신하나?
system call에 의해서, system call은 OS 의 API라고 불린다.
Process
실행중인 프로그램, 메모리에 올라간 프로그램, (CPU time, memory, files, I/O device 필요)
Memory는
- text section: 명령어들(code, program counter)
- data section: 전역변수
- heap section: 메모리 동적할당
- stack section: 함수 parameter, return addresses, 지역변수
으로 나뉜다.
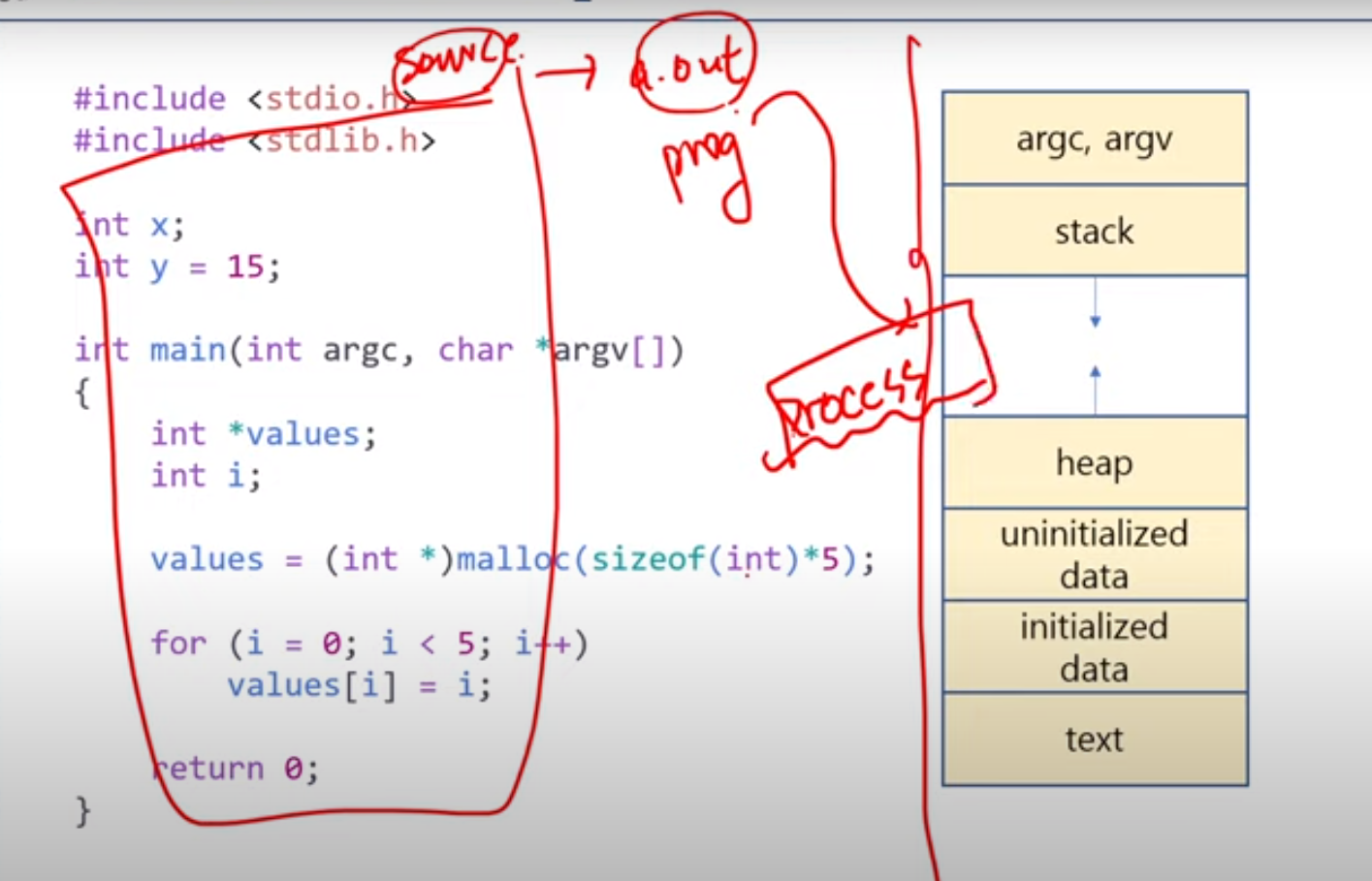
source code -> 컴파일하면 a.out(프로그램) 생성 -> 메모리에 올리면 -> process
Process 생명주기
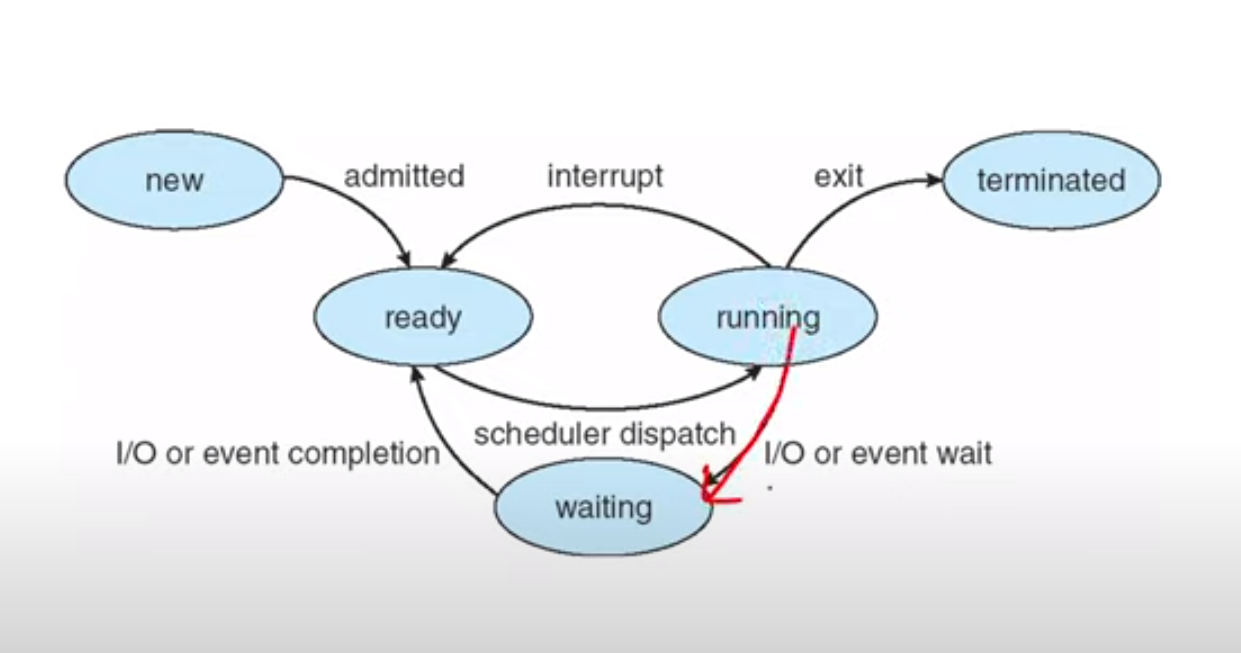
ready queue, waiting queue -> 둘 다 linked list로 구현
waiting queue는 보통 I/O별로 다르게 갖고 있음
PCB(Process Control Block)
process를 관리하는 구조체, 각 process에 필요한 정보 저장
- process state (new, ready, wait, running, ...)
- program counter (명령어의 메모리 주소 저장) -> 이걸보고 IR로 load
- CPU register (register 정보들 저장)
- cpu-scheduling info
- memory-management info
- accounting info (계정정보, 어떤 user가 create 했는지 같은 정보)
- I/O status info (어떤 자원에 lock을 걸어 놨는지 같은 정보)
program counter도 cpu register에 포함되는 개념.
cpu register와 program counter을 합쳐서 context 라 부름.
multiprocessing
OS의 핵심역할, 동시에 여러 프로그램 실행
timesharing
process간의 cpu core을 계속 변경하여 할당해서 user가 한번에 여러 program을 실행하는 것처럼 느낌.
context switch
context: PCB정보
현재 process context 저장
다른 process context 복구
Parent, Child process
tree 관계를 이룸, fork() 라는 system call에 의해 작동
fork(): 자기 주소 그대로 복사하고 계속 execution 하거나 child가 run 하는 동안 할 것이 없으면 child가 종료될 때 까지 wait queue에서 대기 -> interrupt 들어오면 ready queue로 이동, child process에서 fork()하면 0반환, 부모 process의 fork()는 child주소 반환
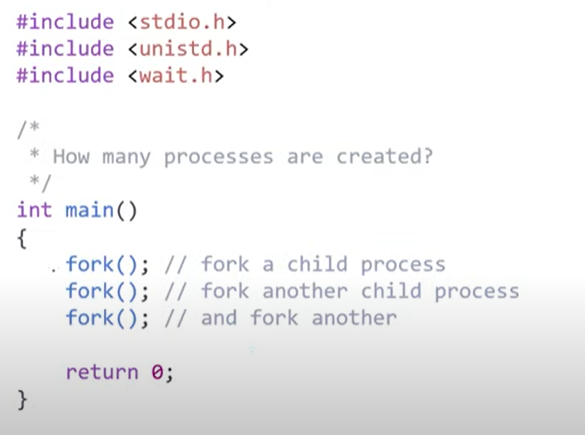
-> process가 7개 추가로 생성되어 8개가 됨
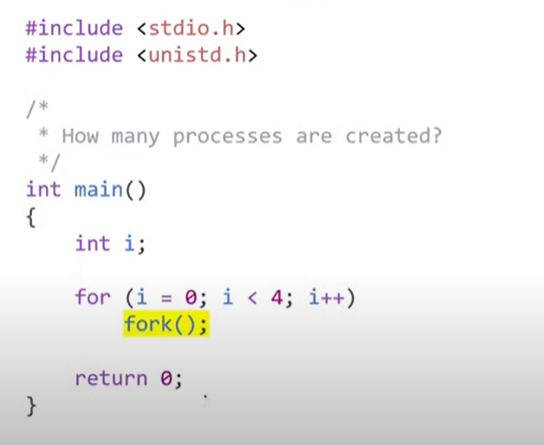
-> process가 15개 추가로 생성되어 16개가 됨
parent, child process의 실행
- [경우1]: 둘 다 동시에 실행됨
- [경우2]: 모든 child process가 종료될 때 까지 paraent process는 wait queue에서 대기함
parent, child process의 PCB
- [경우1]: 같은 일을 처리하는 process인 경우 같은 code를 참조한다. 따라서 PCBp(parent PCB)와 PCBc(child PCB)의 program counter는 같은 주소를 참조한다.
- [경우2]: program counter가 서로 다름 -> child가 새로운 program인 경우
orphan, zombie process
-
orphan process: 부모가 먼저 종료된 자식 process
-> 부모가 죽을 경우 init process가 부모가 되어 orphan process가 종료되고 zombie가 되는것을 방지 -
zombie process: 자식 process가 종료되었는데 부모 process가 자식 process의 종료상태(pid, 종료상태)를 회수 안한 상태.
-> 부모가 wait systemcall을 통해 회수하면 zombie process는 제거된다. zombie process가 쌓이면 source의 유출을 야기할 수 있으므로 제거해 줘야한다.
IPC
두 process는 서로 independent 하게 실행되거나 cooperating하게 실행된다. independent한 경우 데이터를 공유하지 않으며 cooperating하게 실행되는 경우 데이터를 공유한다. 이때 데이터를 IPC(Inter Process Communication) 으로 공유한다.
IPC에는 대표적으로 Shared Memory 방식과 Message passing 방식이 있다.
Shared Memory
Shared Memory 방식은 두 프로세스가 메모리의 일정부분을 공유해서 사용하는 것이다. 하지만 개발자가 이 buffer를 모두 관리해야 하므로 다:다 관계로 통신이 확장되면 관리가 힘들어진다. (하지만 사용안하는 것은 아니다.)
Message passing
반대로 Message passing 방식은 OS가 모든 역할(buffer 관리)을 맡아서 하므로 개발자는 data send, receive만 생각하면 된다. Message passing에서는 communication link를 통해 데이터를 주고 받는다. communication link는 다음과 같은 특성을 갖는다.
- direct / indirect
- 동기(synchronous) / 비동기(synchronous)
- automatic / explicit buffering
direct 방식
process 끼리 직접 전달, reciptent와 sender를 명시해 줘야한다.
send(P, message) // P 에게 메세지 전달
receive(Q, message) // Q 로부터 메세지 받음direct 방식에서는 link가 자동으로 생성되고 두 process 사이 1개의 link만 생성된다.
indirect 방식
message가 port를 통해서 전해진다. port주소를 명시한다.
send(A, message) // 포트A에 메세지 넣음
receive(A, message) // 포트A에서 메세지 꺼냄두 멤버가 port와 통신할 때만 link가 생성된다. 다대다 통신이 가능하다.
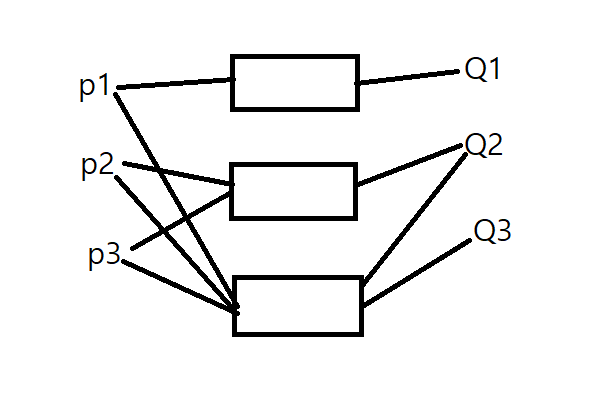
다음과 같이 여러 링크가 존재 가능하다.
USER가 (Create, Delete, Receive, Send)만 해주면 OS가 나머지는 알아서 처리해준다. 여기서 Create, Delete는 port에 대한 create, delete를 의미한다.
synchronous, asynchronous send/receive
Sync / Async / Blocking / Non-Blocking 간단 정리
출처: https://wbluke.tistory.com/49 [함께 자라기:티스토리]
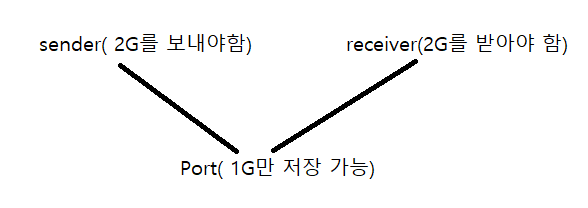
-
blocking send: r이 data 다 받을 때 까지 계속 data를 보내며 wait, 다른일 못함
-
nonblocking send: OS한테 2G data 주고 OS가 알아서 처리해줌, 다른일 함 그동안
-
blocking receive: 2G 다 받을 때 까지 wait, 다른일 못함
-
nonblocking receive: 다른 일 하다가 data들어오면 interrupt가 발생하고 그때 data 받음.
blocking - 동기
nonblocking - 비동기
결제시스템을 구현한다 생각해보자. 동기방식으로 구현할 경우 sender가 receiver가 data를 모두 받았음을 확인할 수 있으므로 안전한 결제가 가능하다. 하지만 비동기 방식으로 구현할 경우 receiver에서 중간에 error가 발생해도 안알려주면 모름으로 문제가 발생할 수 있다. 따라서 결제시스템은 동기방식으로 구현하는 것이 맞다.
Pipe
초기 Unix 시스템의 IPC Mechanism. 방향성이 없지만(입구,출구 개념이 없음) 그냥 사용하면 본인이 보낸 msg를 본인이 읽을 수 있으므로 한 쪽으로만 갈 수 있게 하여 unidirectional로 사용한다.
2개의 Pipe를 사용하여 Full-duplex로 사용, 편의상 parent-child 관계 사용, network에서는 동작 불가능 -> 그래서 나온 개념이 Socket이다.
socket : remote한 computer의 연결을 의미하는 pipe 형태의 connection. IP address와 port 번호로 network상의 computer 특정 가능. full-duplex 이므로 polling을 안해도 돼서 적은 오버헤드로 통신이 가능하다.
- ordinary Pipe: parent, child 관계로 두 process가 통신, unidirectional한 pipe 두 개로 통신
- named Pipe:: 다른 관계에서도 통신 가능, user로 부터 이름이 설정됨.
RPC: remote에 있는 함수를 호출하는 방식
Thread
light weight process. Thread ID, program counter, register set, stack을 포함. {code, data, file(heap)}은 공유, {register, stack, program counter}는 각자 갖는다.
client -요청-> server -넘김->threadserver가 thread에게 client의 요청을 비동기(nonblocking)방식으로 넘기면 server는 계속해서 listen을 excute 할 수 있다. thread 수의 한계 까지는 계속해서 listen이 가능하다.
Cache memory
캐시 메모리는 CPU에서 한번 이상 읽어 들인 메인 메모리의 데이터를 저장하고 있다가 CPU가 다시 그 메모리에 저장된 데이터를 요구할 때 메인 메모리를 통하지 않고 바로 값을 전달하는 용도로 사용된다.
프로세스 사이에서 공유하는 메모리가 하나도 없기 때문에 컨텍스트 스위칭이 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 한다.
쓰레드는 캐쉬 정보를 비울 필요가 없기 때문에 프로세스와 쓰레드의 컨텍스트 스위칭 속도의 차이는 이때 발생한다.
thread의 장점
-
responsiveness: nonblocking으로 처리시 execution 계속 진행가능
-
resource sharing: {code, data, file}을 공유하므로 process간 IPC보다 overhead가 적음
-
economy: process 하나 만드는 것보다 싸다. process context switch보다 thread context switch가 훨씬 간단하다.
-
scability: 확장성이 좋다.
multicore system의 도전과제
-
identifying task: 어느 task를 multi thread 처리할 것인가? -> 병렬처리로 해결가능한 task를 구분해야함.
-
balance: thread 마다 적절하게 task를 배분
-
data-splitting: data 쪼개기
-
data-dependency: data간의 의존성 처리
-
test-debugging이 굉장히 어려워짐.
암달의 법칙
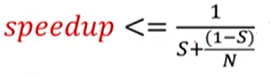
S: serial 하게 처리해야 하는 task 비율
N: core의 개수
병렬처리할 수 있는 tak가 많지 않으면 core 수를 늘려도 별 효과가 없음.
