-> getAllStore 알고리즘 issue[1] 보러가기
직접 dummy data를 넣고 index에 따른 query 실행시간, api 실행시간을 측정해 보았다. 코드는 다음과 같다.
module.exports = (sequelize, DataTypes) => {
const Store = sequelize.define(
"Store",
{
attributes
},
{
indexes: [
{
name: 'latitude_index',
fields: ['latitude',]
},
{
name: 'latitude_longitude_index',
fields: ['latitude','longitude']
}
],
}
);
이 코드와 비교하기 위해서 index가 없는 경우 latitude로만 index를 걸어둔 경우를 추가로 test 했다. dummy data는 어떻게 만들었는지 궁금할 것이다.
Mokaroo 웹사이트에서 dummy data를 제공해준다. 무료버전에서는 한번에 1000개 밖에 제공해주지 않지만 row의 attribute를 원하는 값으로 random하게 생성할 수 있다는 점에서 높은 퀄리티의 dummy data를 다운받을 수 있다. sql문으로 다운받아서 mysql cmd창에 복사하면 되는데 window cmd는 사용하지 말도록 하자.
cmd창에 입력할 수 있는 문자열의 길이가 제한되어 있어서 한번에 많은 data를 넣을 수 없다. 나같은 경우 powershell을 사용했다.
test 과정 보기
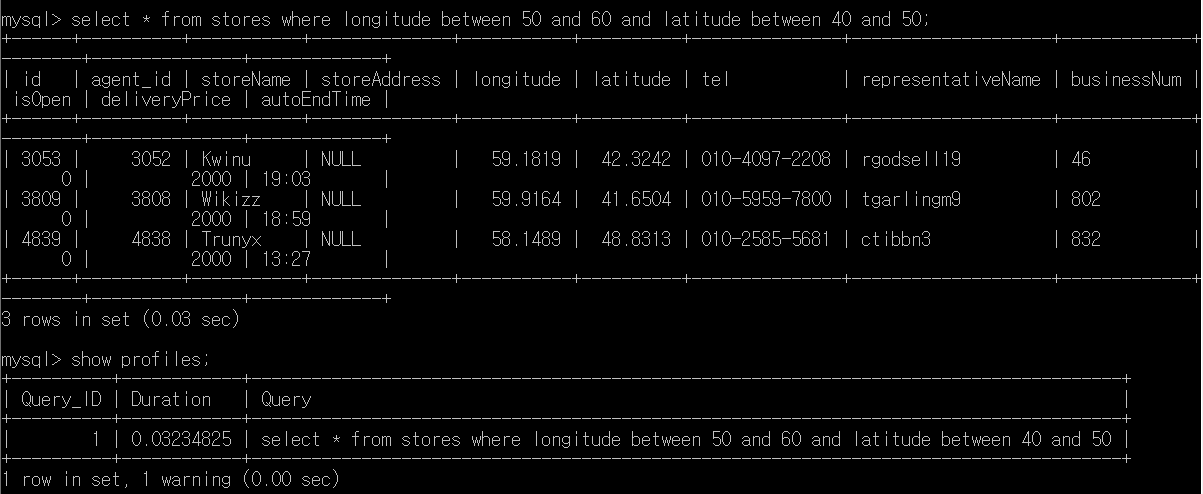
No index

index가 설정되지 않은것을 볼 수 있다. possible_keys는 설정된 index 목록을 보여주고 key는 실제 쿼리에 사용된 index를 보여준다. filtered는 조건에 의해 filtering된 row가 몇 프로인지 보여준다. extra에서는 어떤 방법으로 query를 조회했는지 보여준다. 여기서는 index가 없으므로 where 조건만을 사용하여 full scan이 이루어졌다.

MySQL Query 수행 시간과 해당 Query를 사용하는 API 수행시간이다. API 수행시간은 다음과 같이 test 함수를 만들어서 측정했다. console.time(selector);이 실행되고 console.timeEnd(selector); 이 실행되기 까지 시간을 측정하는 로직인데 callback function에다가 timeEnd를 넣어서 측정했다.
function test(){
$(document).ready(function(){
$.ajax({
url: `/consumer/getAllStore?x=127&y=23`,
type: "get",
datatype: "json",
success: function(result){
console.timeEnd(selector);
if(result.error != 'token expired'){
console.log(result);
}
else{
}
}
})
});
}
var selector = "test";
console.time(selector);
test();이제 index를 달고 쿼리시간을 측정해 보자.
쿼리 측정시간 비교를 똑바로 하기 위해서는 여러 Cache를 제거하는 작업이 필요하다.
show variables like 'have_query_cache';sql query가 저장되고 있는지 확인하는 명령문이다. 다행히 내 device에서는 sql query가 쌓이고 있지 않았다. 하지만 밑에 블로그를 보니까 꽤 많은 처리를 추가로 해줘야 하는데 일단 면접준비가 더 중요한 관계로 이 작업은 방학때 제대로 해보기로 하자 ㅜㅜㅜ
MySQL : 쿼리 성능 측정을 방해하는 요소를 제거하기
One index -> 'latitude'

expalin 명령문을 통해 query가 해당 index를 탔음을 알 수 있다. filtered는 11%인데 별로 좋지 못한 수치인것 같다...


시간을 측정하기는 했지만 환경설정을 제대로 못하고 한 측정이므로 별로 유의미 하지는 않다. 하지만 그것을 제외하고 보더라도 큰 시간 차이가 나지 않는다. 이는 data수가 6000개 밖에 되지않기 때문으로 보인다. index를 탈 경우 O(logN)이고 full scan을 할 경우 O(N)인데 6000개 정도에서는 full scan도 아주 빠른시간에 이루어지기 때문이다.
Two indexes -> 'latitude', 'latitude & longitude'

이번 test에서 가장 큰 개념을 얻어갈 수 있는 결과였다. MySQL이 여러 index가 설정되어 있는 경우에 가장 빠르게 search 할 수 있는 하나의 index를 골라서 query를 수행한다는 사실은 알고 있었다. 하지만 당연히 두 개의 column이 indexing 되어있는 index를 탈 것이라 예상했다. 하지만 결과는 latitude index를 탔다.
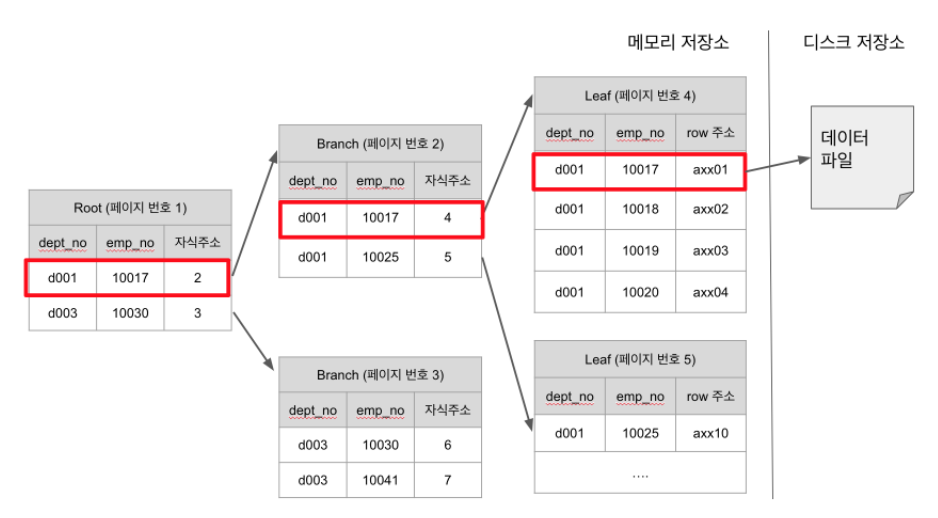
부등호 연산자로 b+tree를 타게 될 경우 다중 column일 때 어떤식으로 작동할지도 의문이었다. 부등호 조건으로 한번 b+tree를 타고 거기서 == 조건을 달아도 꽤 많은 시간이 소요될 텐데 부등호 조건으로 여러번 b+tree를 타는 것이 가능한가 싶었다.
다음 블로그에서 답을 찾을 수 있었다.

where에 부등호 조건이 들어가게 되면 그 뒤에 있는 조건에 대해서는 index를 탈 수 없다는 것이다. 이전에 다중 column indexing에 대해 공부할 때 들던 의문점이 풀리는 순간이었다.
