
01-1. 자료구조(Data structure)에 대한 기본적인 이해
프로그래밍이란 데이터를 표현하고, 그렇게 표현된 데이터를 처리하는 것이다.
데이터의 ‘표현’ = 데이터의 ‘저장’
자료구조 : 데이터를 표현하고 저장하는 방법
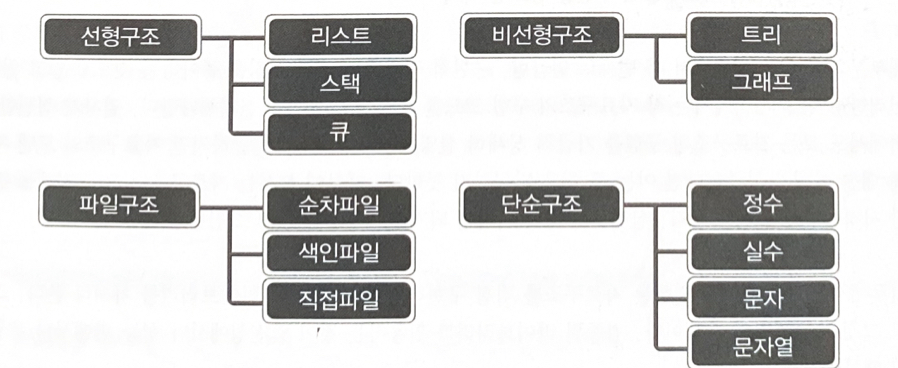
선형 자료구조 : 자료를 표현 및 저장하는 방식이 선형(linear)으로 나란히 혹은 일렬로 저장하는 방식
비선형 자료구조 : 데이터를 나란히 저장하지 않는 구조
알고리즘 : 표현 및 저장된 데이터를 대상으로 하는 ‘문제 해결 방법’
- 자료구조가 결정되어야 그에 따른 효율적인 알고리즘을 결정할 수 있다.
- 알고리즘은 자료구조에 의존적이다.
01-2. 알고리즘의 성능분석 방법
- 시간복잡도(time complexity) : 속도에 해당하는 알고리즘 수행시간 분석결과
- 공간복잡도(space complexity) : 공간에 해당하는 알고리즘 수행시간 분석결과
최적의 알고리즘 : 메모리 ⬇️, 속도 ⬆️
-> 보통 속도에 초점을 둔다.
알고리즘 수행속도 평가 방법
연산의 횟수를 센다.
처리해야 할 데이터 n에 대한 연산횟수의 함수 T(n)을 구성한다.
-> 데이터 수의 증가에 따른 연산횟수의 변화 정도를 판단할 수 있다.

순차 탐색 : 순서대로 탐색을 진행하는 알고리즘
#include <stdio.h>
int Lsearch(int ar[], int len, int target) //순차 탐색 알고리즘 적용된 함수
{
int i;
for(i = 0; i < len; i++)
{
if(ar[i] == target) return i; // 찾은 대상의 인덱스 값 변환
}
return -1; // 찾지 못했음을 의미하는 값 반환
}
int main(void)
{
int arr[] = {3, 5, 2, 4, 9};
int idx;
idx = Lsearch(arr, sizeof(arr)/sizeof(int), 4);
if(idx == -1) printf("탐색 실패 \n");
else printf("타겟 저장 인덱스: %d \n", idx);
idx = Lsearch(arr, sizeof(arr)/sizeof(int), 7);
if(idx == -1) printf("탐색 실패 \n");
else printf("타겟 저장 인덱스 : %d \n", idx);
return 0;
}- 최선의 경우(best case) : 찾고자 하는 값이 배열의 맨 앞에 저장되어 비교연산의 수행 횟수가 1일 경우
T(n) = 1 - 최악의 경우(worst case) : 찾고자 하는 값이 배열의 맨 뒤에 저장되어 비교연산의 수행 횟수가 n일 경우
T(n) = n - 평균적인 경우(average case)
-> 계산하는 것이 쉽지 않다.가정 1. 탐색 대상이 배열에 존재하지 않을 확률을 50%라고 가정한다.
가정 2. 배열의 첫 요소부터 마지막 요소까지, 탐색 대상이 존재할 확률은 동일하다.
- 탐색 대상이 존재하지 않는 경우의 연산 횟수 : n
- 탐색 대상이 존재하는 경우의 연산 횟수 : n/2
탐색 대상이 배열에 존재하지 않는 경우와 존재하는 경우의 확률이 각각 50%이므로 n*1/2 + n/2 * 1/2 = 3/4*n
T(n) = 3/4*n
하지만, 탐색 대상이 배열에 존재할 확률이 50%보다 높을 수도 있고 낮을 수도 있다. 이러한 부분이 전혀 고려되지 않은 방법이다.
이진 탐색
정렬된 데이터가 아니면 적용이 불가능하다.
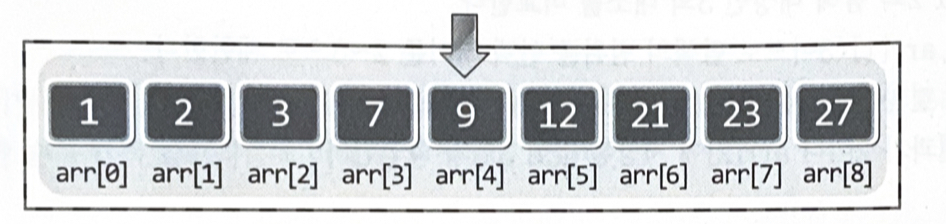
Ex) 다음 배열에서 3을 찾는 알고리즘

1️⃣ 이진 탐색 알고리즘의 첫번째 시도
1. 배열 인덱스의 시작과 끝은 각각 0과 8이다.
2. 0과 8을 합하여 그 결과를 2로 나눈다.
3. 2로 나눠서 얻은 결과 4를 인덱스 값으로 하여 arr[4]에 저장된 값이 3인지 확인한다.
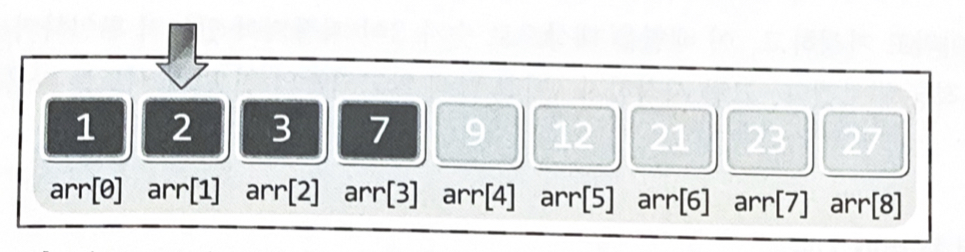
2️⃣ 이진 탐색 알고리즘의 두번째 시도
1. arr[4]에 저장된 값 9와 탐색 대상인 3의 대소를 비교한다.
2. 대소의 비교결과는 arr[4] > 3 이므로 탐색의 범위를 인덱스 기준 0~3으로 제한한다.
3. 0과 3을 더하여 그 결과를 2로 나눈다. 이때 나머지는 버린다.
4. 2로 나눠서 얻은 결과가 1이니 arr[1]에 저장된 값이 3인지 확인한다.
탐색의 대상을 반으로 줄였다.
배열에 데이터가 정렬된 상태로 저장되었기 때문에 가능하다.
3️⃣ 이진 탐색 알고리즘의 세번째 시도
1. arr[1]에 저장된 값 2와 탐색 대상인 3을 비교한다.
2. 대소의 비교결과는 arr[1] < 3이므로 탐색의 범위를 인덱스 기준 2~3으로 제한한다.
3. 2와 3을 더하여 그 결과를 2로 나눈다. 이때 나머지는 버린다.
4. 2로 나눠서 얻은 결과가 2이니 arr[2]에 저장된 값이 3인지 확인한다.

이진탐색 알고리즘의 구현
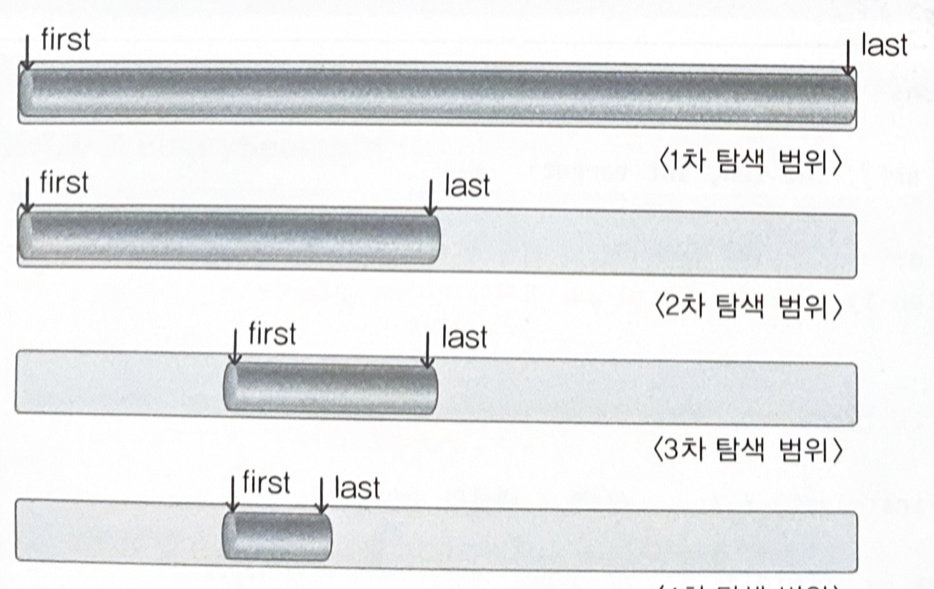
조건 : first > last인 상황은 배열에 찾는 대상이 존재하지 않는다는 의미이다.
while(first <= last)
#include <stdio.h>
int Bsearch(int ar[], int len, int target)
{
int first = 0; //탐색 대상의 시작 인덱스 값
int last = len - 1; // 탐색 대상의 마지막 인덱스 값
int mid;
while(first <= last)
{
mid = (first + last) / 2; //탐색 대상의 중앙을 찾는다.
if(target == ar[mid]) // 중앙에 저장된 값이 타겟이면
{
return mid; //탐색 완료!
}
else // 타겟이 아니라면 탐색 대상을 반으로 줄인다.
{
if(target < ar[mid]) last = mid-1;
else first = mid+1;
}
}
return -1; // 찾지 못했을 때 반환되는 값 - 1
}
int main(void)
{
int arr[] = {1, 3, 5, 7, 9};
int idx;
idx = Bsearch(arr, sizeof(arr)/sizeof(int), 7);
if(idx == -1) printf("탐색 실패 \n");
else printf("타겟 저장 인덱스 : %d \n", idx);
idx = Bserach(arr, sizeof(arr)/sizeof(int), 4);
if(idx == -1) printf("탐색 실패 \n");
else printf("타겟 저장 인덱스 : %d \n", idx);
return 0;
}
-> 위의 코드는 탐색 대상에서 mid를 제외하지만 다음 코드는 탐색의 대상에서 mid를 제외하지 않는다.
if(target < ar[mid]) last = mid;
else first = mid;
탐색의 대상이 배열에 존재하지 않는 경우 무한루프를 형성하며 프로그램이 종료되지 않는다
이진탐색 알고리즘의 시간복잡도 : 최악의 경우
- 처음에 데이터 수가 n개일 때의 탐색과정에서 1회의 비교연산 진행
- 데이터의 수를 반으로 줄여서 n/2개일 때의 탐색과정에서 1회 비교연산 진행
- 데이터의 수를 반으로 줄여서 그 수가 n/4개일 때의 탐색과정에서 1회 비교연산 진행
일반화
- n이 1이 되기까지 2로 나눈 횟수 k회, 따라서 비교연산 k회 진행
- 데이터가 1개 남았을 때, 이때 마지막으로 비교연산 1회 진행
즉, T(n) = k+1
이때, k는 n이 1이 되기까지 2로 나눈 횟수이므로 n*(1/2)^k = 1 이므로 n = 2^K이고 log2(n) = k이다.
즉, T(n) = log2(n)
log2(n) + 1이 아닌 이유는 +1은 중요하지 않기 때문이다.
데이터의 수 n이 증가함에 따라서 비교연산의 횟수가 로그적으로 증가한다는 사실이 중요하다.
빅-오 표기법(Big-Oh Notation)
함수 T(n)에서 가장 영향력이 큰 부분이 어딘가를 따지는 것
근사치 식을 구성해도 문제가 되지 않는다.
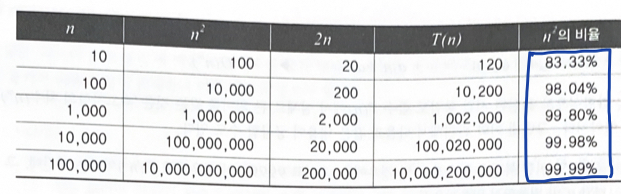
n^2의 영향이 크기 때문에 +1과 같은 상수는 생략해도 된다.
즉, T(n) = n^2 + 2n + 1 은 O(n^2)이라고 할 수 있다.
단순하게 빅-오 구하기
T(n)이 다항식으로 표현이 된 경우, 최고차항의 차수가 빅-오가 된다.

일반화

대표적인 빅-오
- O(1)
- 상수형 빅-오
- 연산횟수가 고정인 유형의 알고리즘
- O(log n)
- 로그형 빅-오
- ‘데이터 수의 증가율’에 비해서 ‘연산횟수의 증가율’이 훨씬 낮은 알고리즘
- O(n)
- 선형 빅-오
- 데이터의 수와 연산횟수가 비례하는 알고리즘
- O(nlog n)
- 선형 로그형 빅-오
- O(n^2)
- 데이터 수의 두 배에 해당하는 연산 횟수를 요구하는 알고리즘
- 데이터의 양이 많은 경우 적용하기 부적절
- 보통 중첩된 반복문 내에서 발생
- O(n^3)
- 데이터 수의 세 배에 해당하는 연산 횟수를 요구하는 알고리즘
- 삼중 중첩 반복문 내에서 발생
- O(n^2)
- 지수형 빅-오
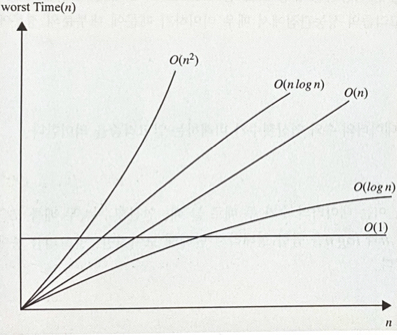
O(1) < O(log n) < O(n) < O(nlog n) < O(n^2) < O(n^3) < O(2^n)
순차 탐색 알고리즘과 이진 탐색 알고리즘의 비교
| n | 순차 탐색 연산횟수 | 이진 탐색 연산횟수 |
|---|---|---|
| 500 | 500 | 9 |
| 5,000 | 5,000 | 13 |
| 50,000 | 50,000 | 16 |
- 순차탐색 빅-오 = O(n)
- 이진탐색 빅-오 = O(log n)
빅-오에 대한 수학적 접근
두 개의 함수 f(n)과 g(n)이 주어졌을 때, 모든 n>=K에 대하여 f(n) <= Cg(n)을 만족하는 두 개의 상수 C와 K가 존재하면, f(n)의 빅-오는 O(g(n))이다.
Ex)
- f(n) = 5n^2 + 100
- g(n) = n^2
- C를 3500이라 가정한다.
: 5n^2 + 100 <= 3500n^2 - K가 12라고 가정한다.
: f(n) = 820이고, g(n) = 14*3500이므로 1.의 식이 성립한다.
즉, f(n) = 5n^2 + 100의 빅-오는 O(n^2)이다.
어느 순간 이후부터 f(n) <= Cg(n)을 항상 만족하기만 하면 된다.
빅- 오는 증가율의 상한선을 표현함으로써 증가형태을 나타내는 표기법이다.
-> 증가율의 상한선이 n^2일 경우, 연산횟수의 증가 형태는 n^2의 형태를 못 벗어나기 때문이다.
