지역성이 뭐지
지역성(Locality)은 컴퓨터 시스템에서 데이터에 접근하는 패턴이 물리적 위치와 시간적 근접성을 가진다는 특성이다.
ex) 1. for문에서 사용된 반복자 i는 루프마다 반복적으로 사용되어 시간적 지역성이 높다.
2. Array의 각 원소를 순차적으로 접근하는 경우 메모리에서 또한 순차적으로 이를 접근하기 때문에 공간적 지역성이 높다.
Cache Line이 뭐지
CPU와 메모리에서도 이러한 지역성을 활용해 최적화한 방식을 사용하는데, 그중 하나가 Cache Line이다.
RAM에서 메모리를 읽어서 CPU로 가져올때, 요청한 주소에서 Cache Line 만큼의 길이를 읽어서 가져온다.
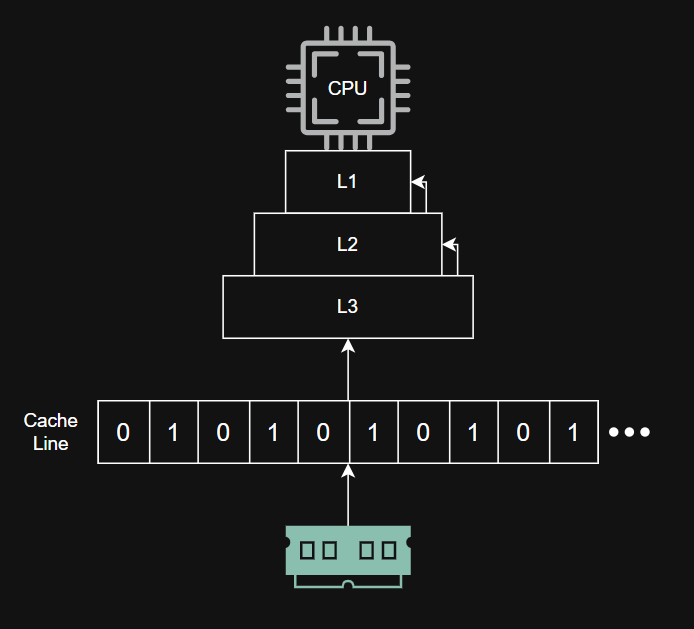
( L1,L2,L3는 CPU안에 있는 캐시 메모리로 다이어그램상 외부에 있다고해서 오해하지 마시길 바랍니다. )
위 그림처럼 CPU는 필요한 메모리 주소가 있으면 먼저, L1, L2, L3순으로 자신의 캐시를 살펴본다. 만약 캐시 메모리에 없다면, RAM에 이를 요청하는데, RAM에서는 그 주소로부터 Cache Line 크기 만큼의 정보를 읽어 CPU에 전달한다. CPU에서는 이를 사용함과 동시에 캐시에 보관하여 다음 실행 때 지역성을 사용할 수 있도록 한다.
GC가 이걸 어떻게 이용해
String[] arr = new String[size];
for (int c = 0; c < size; c++) {
arr[c] = "Value" + c;
}
Collections.shuffle(Arrays.asList(arr), new Random());이렇게 String의 배열을 만들어 섞으면? 메모리에 차곡차곡 쌓여있던 String들이 뒤섞여 Cache Line을 통한 최적화가 어렵다.
하지만 GC가 이를 해결해준다!
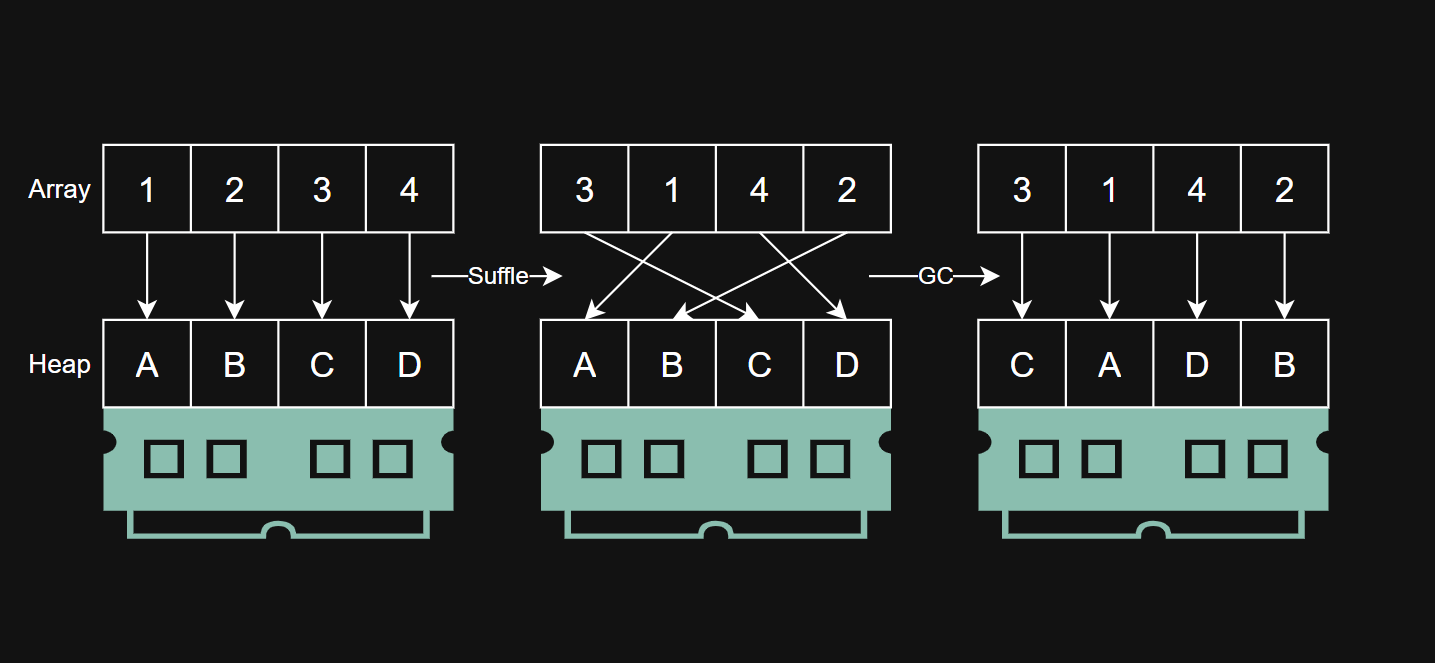
GC가 Compaction을 진행하면서 객체들을 배열이 참조하는 순서에 맞게 정렬한다.
그러면 다시 지역성이 생겨 최적화가 된다.
효과가 있긴한가
JMH로 벤치마크 돌려서 확인해보자
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.io.IOException;
import java.util.Arrays;
import java.util.Collections;
import java.util.Random;
import java.util.concurrent.TimeUnit;
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(value = 1, jvmArgsAppend = {"-Xms8g", "-Xmx8g", "-Xmn7g"})
public class ArrayWalkBench {
@Param({"16", "256", "4096", "65536", "1048576", "16777216"})
int size;
@Param({"false", "true"})
boolean shuffle;
@Param({"false", "true"})
boolean gc;
String[] arr;
@Setup
public void setup() throws IOException, InterruptedException {
arr = new String[size];
for (int c = 0; c < size; c++) {
arr[c] = "Value" + c;
}
if (shuffle) {
Collections.shuffle(Arrays.asList(arr), new Random());
}
if (gc) {
for (int c = 0; c < 5; c++) {
System.gc();
TimeUnit.SECONDS.sleep(1);
}
}
}
@Benchmark
public void walk(Blackhole bh) {
for (String val : arr) {
bh.consume(val.hashCode());
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(ArrayWalkBench.class.getSimpleName())
.build();
new Runner(opt).run();
}
}코드출처
위 코드를 처음 실행해보았을땐 GC를 사용했을때가 더 느리다는 결과가 나왔었다. 처음엔 오차 때문이라고 생각해서 여러번 반복해서 돌려보았지만 결과는 그대로였다. 이유는 GC 종류의 차이 때문이었다. Java의 기본 GC인 G1 GC는 region을 사용하여 객체를 관리하기 때문에, 각각의 객체가 메모리상 멀리 떨어져 있게 되고 compaction 또한 region에 독립적으로 실행되어 지역성을 활용하기 어렵다. 따라서 ParallelGC를 사용해 실행하면 아래와 같은 결과를 얻을 수 있다.
(gc) (shuffle) (size) Mode Cnt Score Error Units
false true 16 avgt 5 0.005 ± 0.001 us/op
false true 256 avgt 5 0.063 ± 0.005 us/op
false true 4096 avgt 5 1.809 ± 0.069 us/op
false true 65536 avgt 5 45.365 ± 0.315 us/op
false true 1048576 avgt 5 3861.053 ± 87.345 us/op
false true 16777216 avgt 5 88865.747 ± 914.698 us/op
true true 16 avgt 5 0.005 ± 0.001 us/op
true true 256 avgt 5 0.061 ± 0.002 us/op
true true 4096 avgt 5 1.691 ± 0.033 us/op
true true 65536 avgt 5 38.394 ± 0.432 us/op
true true 1048576 avgt 5 2119.701 ± 77.154 us/op
true true 16777216 avgt 5 42002.314 ± 313.970 us/op 결과를 보면 GC를 사용했을때 실행 속도가 두배 이상 빨라지는 것을 알 수 있다.
G1 GC를 사용하면 이보다 더 느리게 나오는데, GC에도 은총알은 없다는걸 알 수 있는 부분이다.
이렇게 GC가 지역성을 활용해 최적화 하는 방법을 알아보았다.
