학교 노트북에서 ai 돌리기

개요
학교 노트북에서 로컬로 sLM을 구동시키는 방법을 소개합니다.
{
CPU: i7 1360p
GPU: Iris Xe Graphics (내장그래픽)
RAM: 16GB
}학교노트북의 사양은 위와 같습니다. GPU가 nvidia 그래픽카드가 아닌 인텔 내장 그래픽이기 때문에, 기본적으로 ai 연산을 지원하지 않습니다. 따라서 CPU를 활용하여 연산해야합니다.
CPU는 GPU에 비해 처리량이 현저히 낮으므로, 양자화를 통해 연산량을 줄여야 합니다.
양자화란
ai 모델의 FP16, FP32(부동소수점) 자료형의 가중치를 int8, int4등의 더 작은 자료형으로 변환하는 과정을 말합니다. 해당 과정을 거친 모델은
양자화 단계(비트 수)에 따라 Q8, Q4, Q3등의 수식어가 붙습니다.
가중치를 부동소수점 자료형에서 정수 자료형으로 변환하였을 때의 이점
1. 모델의 크기 감소
자료형의 크기가 작아져 차지하는 저장공간, 메모리가 줄어듭니다.
2. 연산량의 감소
자료형의 크기가 작아짐에 따라 필요한 연산량이 줄어듭니다.
3. CPU 구동 환경에서의 최적화
기존 모델들은 실수형의 행렬곱으로 연산을 하지만, 최신 CPU들의 경우 정수형의 행렬곱에 한해 이를 정수들의 덧셈으로 치환하여 빠르게 연산하는 명령어 셋을 제공합니다.
사용할 모델
vsc, chrome등을 거의 항상 켜두기 때문에 RAM 또한 부족하여
저용량, 양자화 모델이 필요합니다.
파라미터수가 적은 모델들은 한국어를 못하기 때문에 꺼려졌지만 마침 Kakao에서 Kanana-nano 2.1B라는 모델을 공개하였습니다.
Kanana는 국산 ai 모델답게 동급의 모델들중 압도적인 한국어 능력을 가졌고 2.1B라는 굉장히 작은 파라미터를 가졌기 때문에 조건에 부합하는 모델입니다.
Hugging face에서 Kanana nano의 양자화 모델을 찾아 사용하였습니다.
과정
Ollama 설치
Ollama는 LLM을 컴퓨터에서 쉽게 구동할 수 있도록 도와주는 도구로, 저 같은 비전공자가 ai를 사용하기 위해 필수적인 프로그램입니다.
ollama.com/download에서 ollama를 다운로드하고 실행시킵니다.
모델 설치
위에서 설명했듯이, hugging face에서 kanana-nano의 4비트 양자화 모델을 다운로드 받았습니다.
FROM kanana-nano-2.1b-instruct-Q4_K_M.gguf
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>human:
{{ .Prompt }}</s>
<s>ai:
"""
SYSTEM """
당신은 신뢰할 수 있는 AI 어시스턴트입니다.
사용자의 요청을 분석하고, 명확하고 정중하게 응답하세요.
가능한 경우 근거를 제시하며, 불확실할 경우 "모르겠습니다"라고 답변하세요.
유머, 친절함, 논리적인 설명을 포함하여 대화하세요.
"""
PARAMETER temperature 1
PARAMETER top_p 1
PARAMETER top_k 60
PARAMETER num_predict 3000
PARAMETER num_ctx 4096
PARAMETER stop <s>
PARAMETER stop </s>
PARAMETER stop {s}gguf 파일과 같은 위치에 Modelfile을 만들고, 위와 같이 작성했습니다.
내용은 대부분 GPT가 작성했지만, 단순하게 모델에게 상황을 제시하고, 시스템 프롬프트 입력, 기본적인 값들을 세팅하는 정도입니다.
ollama create kanana-nano -f ./Modelfile위 명령어를 통해 모델을 빌드했습니다.
ollama list를 통해 모델이 잘 설치됐는지 확인할 수 있습니다.
ollama run kanana-nano를 사용하여 모델을 구동시키면 아래와 같이 ai 모델과 대화할 수 있습니다.

그 어렵다던 3행시도 잘하는 모습이다..
Open Web UI 설치
준비물: docker
저렇게 명령줄을 통해서도 대화할 수 있지만, ChatGPT처럼 웹UI를 사용하여 대화할 수도 있습니다.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main해당 명령어를 사용하면 docker에서 Open Web UI를 간단하게 구동시킬 수 있습니다. 실행후 localhost:3000에 들어가면 아래와 같이 chatGPT처럼 ollama에서 구동중인 ai를 사용할 수 있습니다.
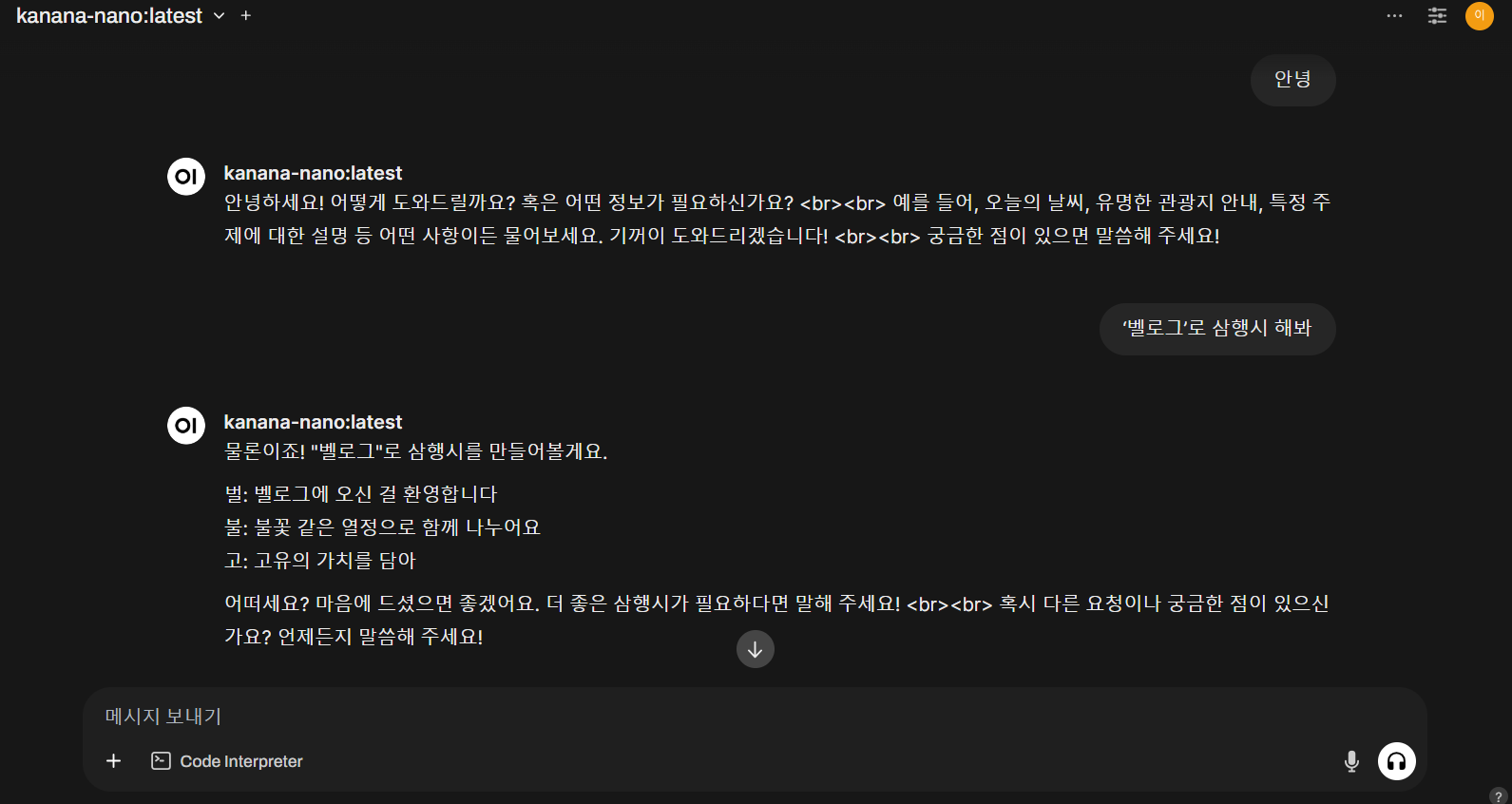
삼행시 잘하는줄 알았는데..
이렇게 학교 노트북으로 sLM을 구동하는 방법에 대해 알아보았습니다.
후기
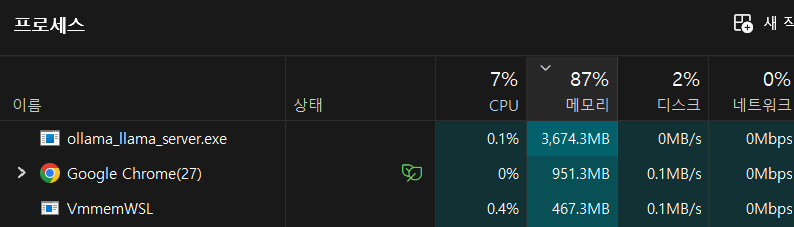
docker + ollama까지 약 4GB정도의 메모리를 사용하는데, 이정도면 16GB 기준으론 다른 작업과 함께 사용할 만한 것 같습니다.
물론 chatGPT, claude, gemini, grok등 좋은 모델들을 무료로 사용할 수 있기 때문에 큰 의미는 없지만, 토이프로젝트에 사용하기에 매우 좋은것 같습니다.
