고려대 sw 인공지능 아카데미 2기 1회차
python
a = 1
(name) = (expression)
expression = 하나의 결과 값으로 축약 할 수 있는 식
expression
1. number(atomic)(더이상 쪼개지지 x)
- 숫자는 쪼개지면, 의미가 달라진다.
int : 정수 ex) literal(특수기호) 없는 그냥 숫자
float : 부동소수점 ex) (1.) or (1e-4)
complex : 복소수 ex) 1+3j
bool : true = 1 , false = 0
int (4가지)
- 0b는 2진수, 0o는 8진수, 0x는 16진수를 의미합니다. > literal
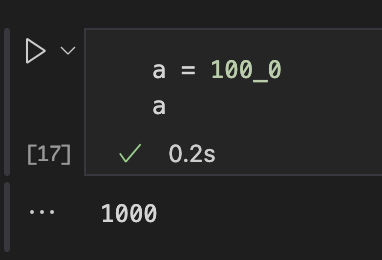
- a = 100_00 (사람이 읽고 싶은 숫자)
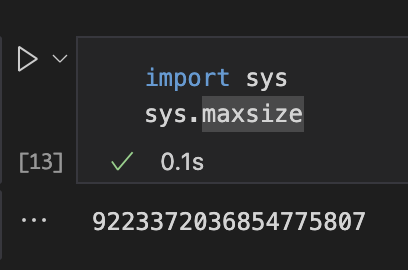
- Int의 크기는 무한대
-
파이썬은 overflow 가 없다. 왜? 숫자가 굉장히 크니까
-
but 단점은 애초에 메모리를 크게 잡는다. > 속도가 느려진다.
-
요기서 numpy가 사용되는 이유가 나온다.
float
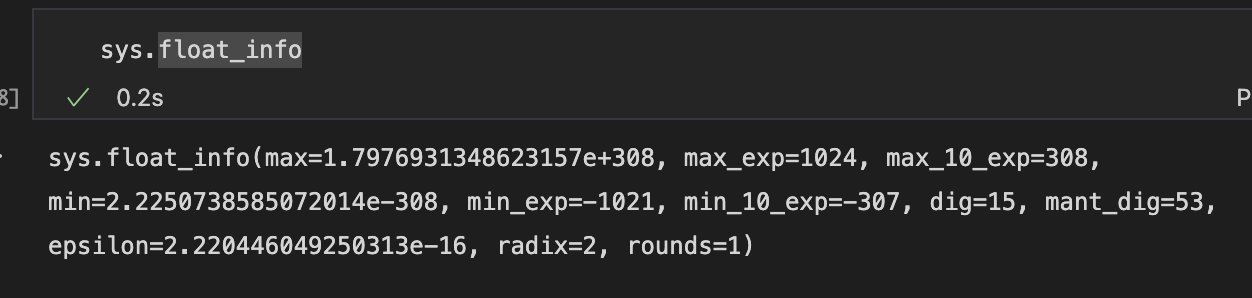
max=1.7976931348623157e+308
a = a+1
가능할때는 무한대 일때만
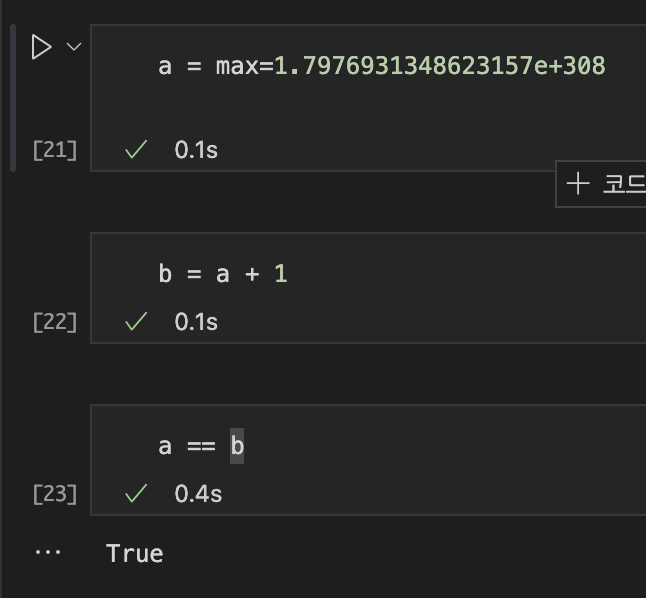
파이썬은 근사적으로, 대충 값을 정한다.
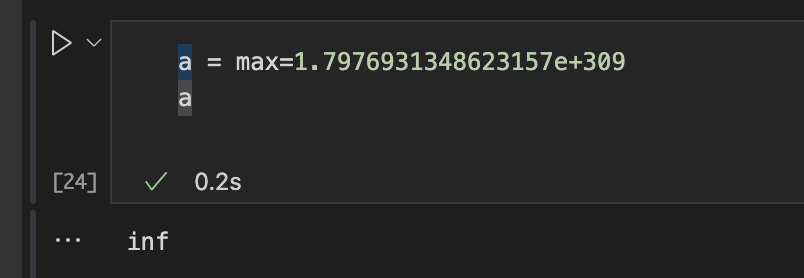
파이썬 inf(무한대) 타입은 float
float('inf') = inf
질문
이렇게 데이터를 만드는 방식을 뭐라고 했지?
답
instance 방식으로 만드는 것
값을 만드는 방식은 2가지
1. literal
2. instance ex) float('inf') = inf
질문
숫자가 아닌것을 숫자에 포함할 수 있을까?
답
숫자가 아닌것도 float으로 만든다.
float('nan') = nan
결론
numpy 로 넘어간다.
2. string문자열(container)(homo, sequence, immutable)
- str 유니코드
- bite 유니코드로 못쓰고
a = b'abc' - bitearray (mutable)
- (memoryview)
len
<function len(obj, /)>
파이썬은 문자열을 다루기 너무 편하다.

container
-
헤테로=헤테로지니어스 (Heterogenous) : 안에 들어갈 데이터 타입이 다른 것
- [1 , '1']- ex) set, list 등
-
호모=호모지니어스 (Homogenous) : 안에 들어갈 데이터 타입이 같은 것
- 속도가 빠르다.
- import array 는 다 호모- 딥러닝은 무조건 호모여야 한다.
- ex) str 삼총사, range 등
-
sequential Or non sequential
sequential 문자
non sequential 집합
set 은 내부적으로는 순서를 만들지만, 우리 눈에은 안보이는 거지
질문
순서가 있다면, indexing 할 수 있다.
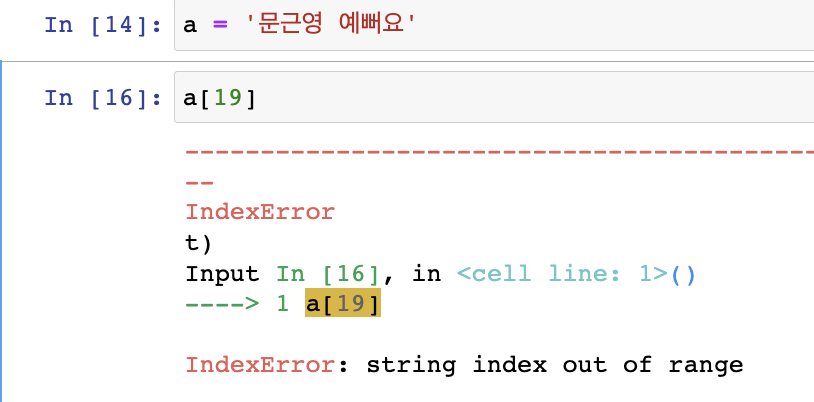
여러개 뽑는건 slice
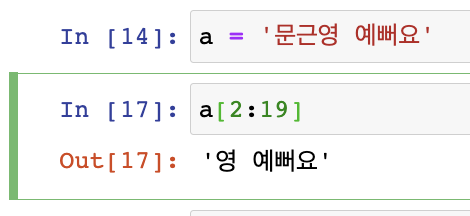
왜? 에러가 안나는거야?
- immutable
list, tuple
list or tuple 차이는 mutable 차이
range(10)[3]
인덱싱
슬라이싱 가능하다.
실무에서 리스트 쓰면 싸대기 맞는다.
문제점이 많다.
what is mutable?
그렇다면 상수의 개념부터 정리하고 가야한다.
what is variable(변수), constant(상수)
a 는 변수가 아니다. name 이다.
파이썬에는 상수가 없다. 그러면 변수는 뭐야?
상수처럼 취급은 가능하지만, 상수는 없다.
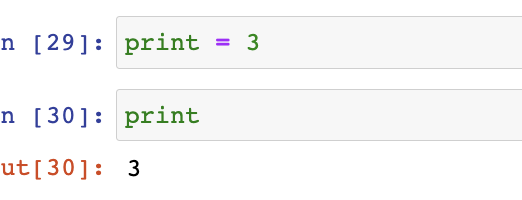
변수는 재할당 가능하다.
a = 1
a = 2
a는 1,2 로 변할 수 있잖아? 그러면 변수

자바에서는 오류 떠유!
변수는 재할당할때 id 이 달라진다.
Mutable(변하기 쉬운) 은 id가 바뀌지 않는다.
딥러닝의 weight는 Mutable 자기 자신 값이 바뀌게 한다.
mutable 내부적으로 메모리를 공유한다.
mutable 의 특징

보면
a = [1,2,3] 일거 같지만, [1,2,3,4 ]

요렇게는, 명백하지 않기때문에 쓰지 않는다.

요렇게 해야한다.
copy 방법
얕은 복사(shallow copy)와 깊은 복사(deep copy)
함수형 패러다임에서는 Mutable이 없는 데이터 타입을 한다.
tensorflow의 기본 타입은 tensor immutable(불변) 이다.
list (hetero, sequence,mutable)
tuple (hetero, sequence,immutable)
(1)set (hetero,mutable)
(1)frozenset (hetero, immutable)
내가 정할 수 없는 순서를 가지고 있따.
안에는 immutable 데이터만 넣을 수 있다. (tuple) but list는 불가능하다.
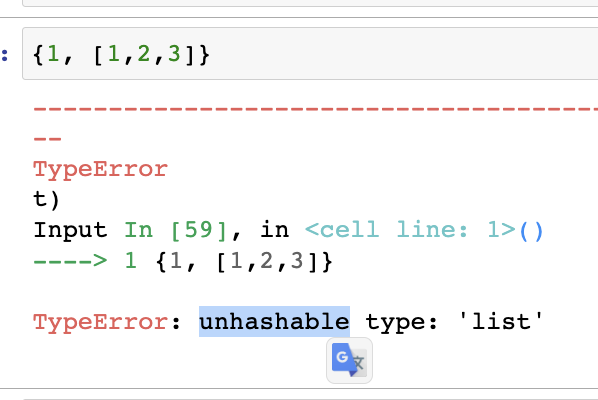
mutable
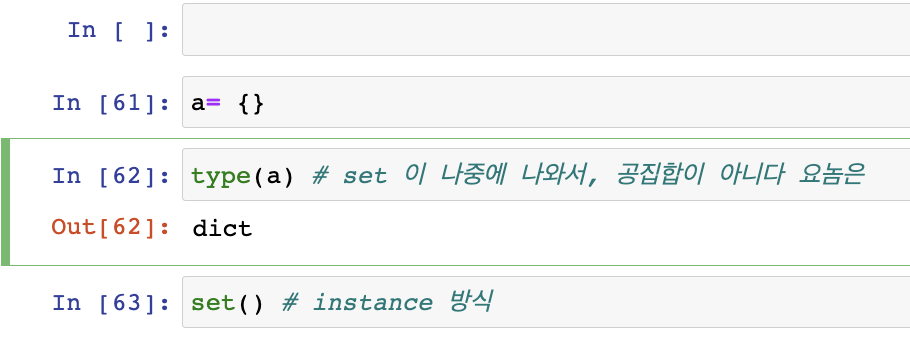
dict (mutable)mapping data
dict = {'a', 1} = {key , value}
key = 해시 데이터 타입
는 immutable data
질문
a = {(1,2,3):1} 될까?
답
가능하다!
연습

dict 기반으로 set 을 만들었다.
질문
data 와 value 의 차이점?
답
data = low 그자체!
value = type으로! > 그래서 이상한 타입을 본거야
그러면 타입에 따라 다양한 기능이 나온다.
식은 하나의 결과 값으로 축약이 가능하다.
그러면
연산을 알아야 한다. 연산자 알아야한다.
연산자를 알아보자
산술 연산자
a = True + True
a =2
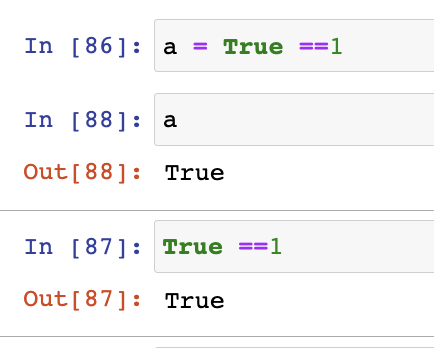


망했다 요 차이가 뭐야?
나머지 정리 알아봐야 한다.
마이너스로 나누어서 나머지가 -
플러스로 나누어서 나머지가 +
3x + a
a = 0,1,2
222
2**3
두개 속도가 다른다.
opencv 를 보면,

data type 마다 연산자 다르다! 성능다르다
질문
문자열 곱하기 가능해?
답변

이 데이터 타입에서는 이 연산자 지원하지 않는다는 의미
seq * 4 는 같다.




(1,2,3) + [2,3,4]
= 오류
집합 mutable, 리스트 immutable
정리
값은 값이여도 데이터 마다 연산자가 다르기 때문에 속도가 달라지는 거다.
3 + 3.1
int + float 인데, 변경해서 하는거
= 6.1
pandas?
coercion (코어션)
같은 형의 두 인자를 수반하는 연산이 일어나는 동안, 한 형의 인스턴스를 다른 형으로 묵시적으로 변환하는 것. 예를 들어, int(3.15)는 실수를 정수 3으로 변환합니다. 하지만, 3+4.5 에서, 각 인자는 다른 형이고 (하나는 int, 다른 하나는 float), 둘을 더하기 전에 같은 형으로 변환해야 합니다. 그렇지 않으면 TypeError를 일으킵니다. 코어션 없이는, 호환되는 형들조차도 프로그래머가 같은 형으로 정규화해주어야 합니다, 예를 들어, 그냥 3+4.5 하는 대신 float(3)+4.5.
더 큰 데이터 타입으로 변경하고 더 해준다.
비교연산자



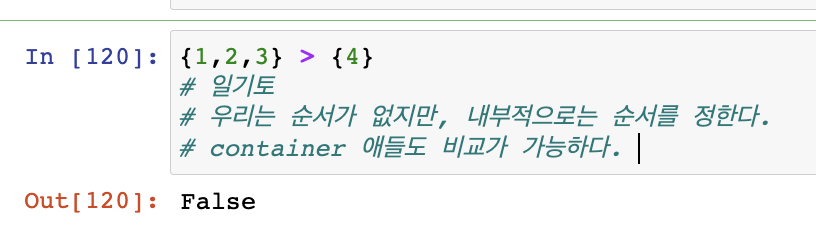
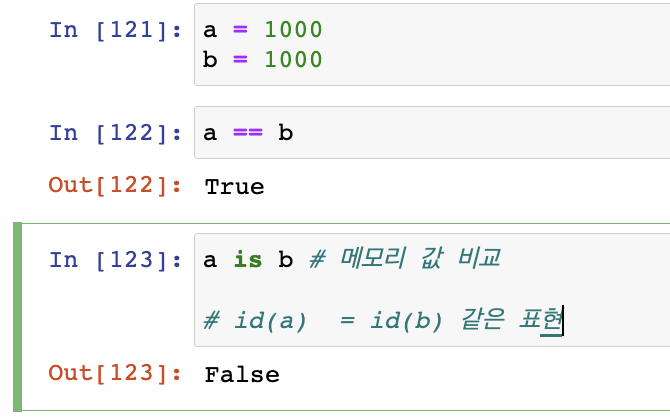
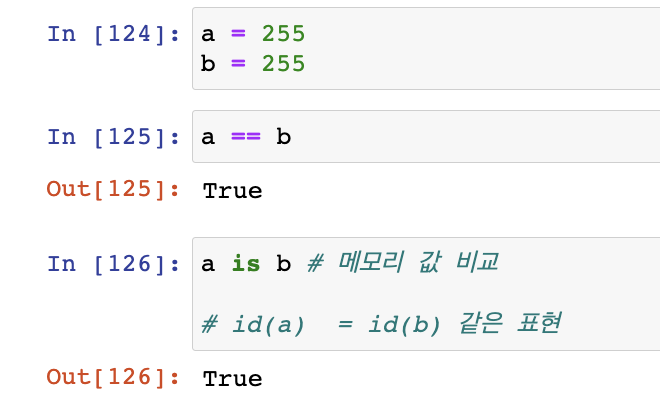
옹 메모리 값이 왜 똑같이?
연산자마다 특징이있다.
파이썬은 너무 느려서 범위를 정해놓았다.
-5 ~ 256 까지는 동일한 메모리 = interning

재밌는 세상이 열린다.
and, or
정수에 없다? = 0
없는 것은 거짓이다. =



옹 신기한다, 앞이 참이니까, 에러가

반대는 틀리겠지?
^^^
|||
short circuit 테크닉
Operator overloadding 을 알게 되어야 한다.

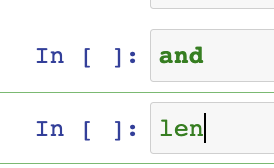
요기보면 차이가 나네? keyword 면 두껍네
걍 help('and') 해봐 그러면 알려줄거야!
