분산학습 성공 기록 (Corpus Pretrain)
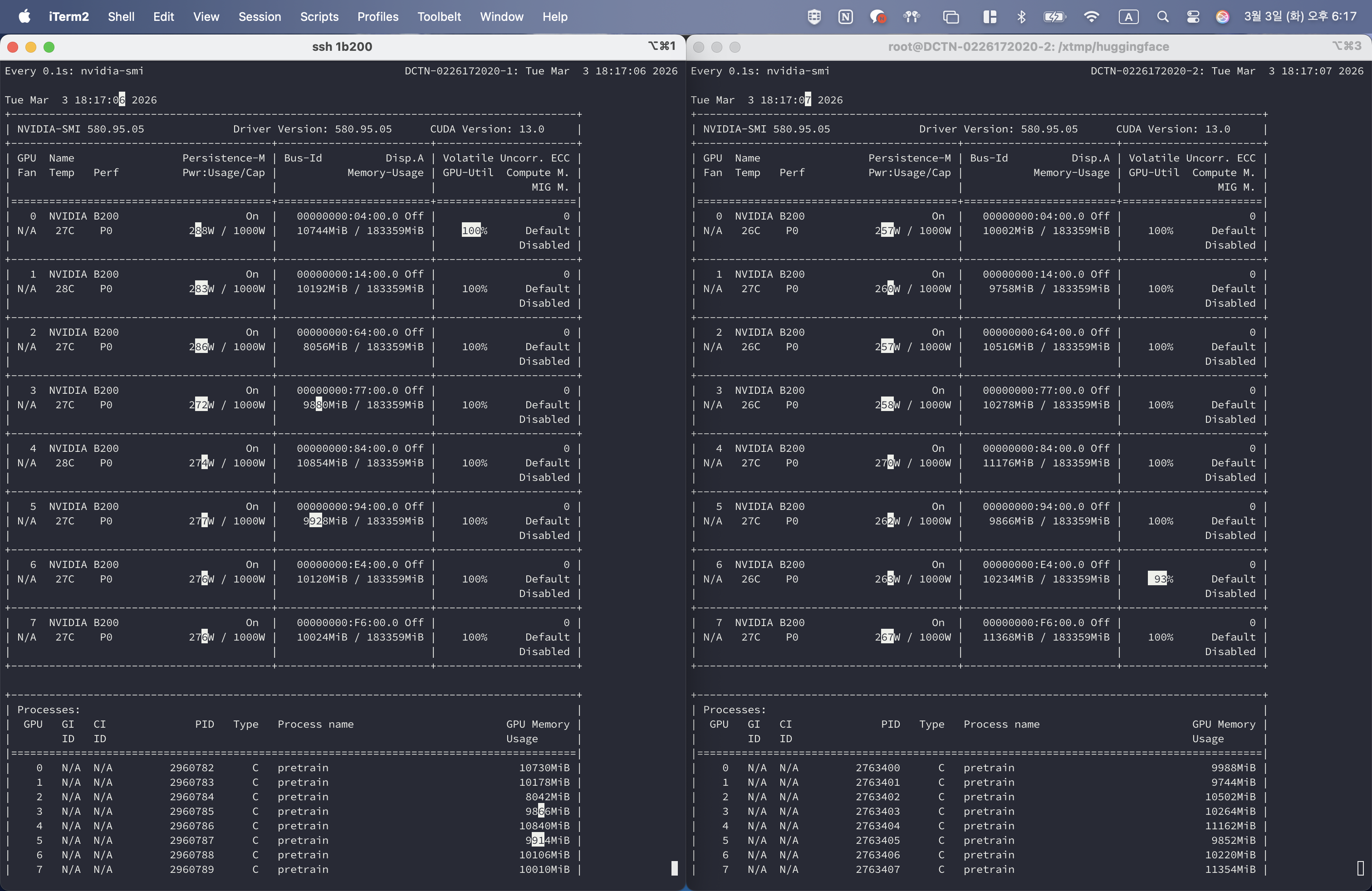
180 GiB GPU × 16개 = 총 2.8 TiB
이번에는 accelerate 기반으로 분산학습을 어떻게 성공시켰는지 정리한다. 코드는 이미 있었고, 실행 환경만 맞추면 됐다.
사전 확인 사항
- 스토리지 공유 여부
- 마스터 노드 공유 여부
1. 스토리지
해당 서버는 NAS로 구성돼 있어 추가 설정은 필요 없었다.
실행 config를 서버별로 다르게 두고, 각 서버에서 실행만 하면 됐다.
2. 마스터 노드
서버 1·2가 같은 마스터 포트(보통 29500)로 서로 연결돼 있어야 한다.
연결 확인 절차
Step 1. 마스터 서버 결정
서버 1, 2 중 마스터를 정한다. 여기서는 서버 1을 마스터로 사용했다.
Step 2. 서버 1의 메인 IP 확인
hostname -I출력에서 가장 앞에 나오는 IP가 메인 내부 IP다.
Step 3. 포트 연결 테스트
서버 1에서 리스닝:
nc -l 29500서버 2에서 연결 테스트:
nc -vz 10.x.x.xx 29500아래처럼 나오면 성공이다.
Connection to 10.x.x.xx 29500 port [tcp/*] succeeded!방화벽 주의
방화벽은 건드리지 말 것.
방화벽 해제로 시도했다가 서버 이상 동작으로 장애가 난 사례가 있었다.
Tmux 사용 이슈
연결 확인 후 accelerate로 학습을 돌리면 된다. 학습이 오래 걸리므로 nohup이나 tmux를 많이 쓸 텐데, 여기서는 tmux 사용 방식 때문에 문제가 있었다.
증상
- 서버 1에서 tmux로 학습 실행 → 멈춤
- 서버 1 tmux 안에서 서버 2로 SSH 접속 후 학습 실행 → 서버 2만 동작
원인 추정
- 서버 1이 GPU·CPU 메모리를 거의 다 쓰면서, 같은 세션 내 SSH 연결까지 유지하기 어려웠을 가능성
해결
- 로컬 PC에서 tmux 실행
- 같은 tmux 세션에서 서버 1, 서버 2에 각각 SSH 접속
- 각 터미널에서 학습 실행
이런 이슈를 피하려면
nohup으로 돌리는 방식이 더 단순하다.
기타 참고
- B200 GPU: Flash Attention 4 미지원이라 사용할 수 없었다.
다음 글 예고
코드 설정(accelerate config 등)을 어떻게 했는지 정리할 예정이다.

누구나 AI를 할 수 있게 쉽게 설명하기!