동기
테킷 수업을 하던 중 강의 내용에서 실시간 검색 순위를 가져오는 것을 배웠는데 실검이 없어지고 다른 예제를 찾아보다가 발견한 네이버 웹툰 순위
하지만 우리가 공부한 코드와 내용이 달라서 3주 전엔 해결하지 못한 과제였음
이번 ai school 박조은 강사님의 강의를 듣고 문제를 해결해서 이렇게 적어봄
Q.❓
네이버 웹툰 실시간 순위 데이터 파일을 만들어보자
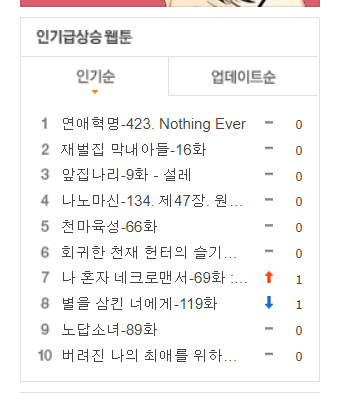
A. ❗
박조은 강사님 수업에서는 table형식으로 된 html을 받아 데이터 프레임을 만들었지만 나는 리스트 형태의 html을 데이터 프레임으로 넣는 것이라 내용은 조금 다릅니다.
아래에는 강의내용과 함께 정리할 것으로 코드만 있지는 않아요.
(내용이 아주 많을 것이라는 이야기)
환경
주피터 노트북을 사용할까 했지만, 현재 코랩으로 공부 중이기 때문에 코랩으로 하겠음
웹 크롤링
웹사이트(website), 하이퍼링크(hyperlink), 데이터(data), 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것.
🔗출처 링크
웹 스크래핑
웹 사이트(website)에 존재하는 데이터 중에서 필요한 데이터만을 추출하도록 만들어진 프로그램.
🔗출처 링크
웹 크롤링 vs 웹 스크래핑
- 공통점
- 데이터를 모을 수 있다.
- 차이점
| 웹 크롤링 | 웹 스크래핑 |
|---|---|
| 웹 페이지의 링크를 타고 계속해서 탐색 | 데이터 추출을 원하는 대상이 명확해서 특정 웹사이트만을 추적 |
| 중복제거 필수 | 특정 데이터만을 추출하기 때문에 중복제거 필수는 아님 |
데이터 수집 시 주의할 점
- 법률적으로 문제가 없는지 확인
- 저작권 위반
- 무리한 요청을 하게 되면 사이트에 부담이 될 수 있음 → 영업침해 행위가 될 수도
- 출처 및 사용가능 여부를 확인해보기
웹 스크래핑 알아둘 점
- 서버에 부담이 생길 수 있다
- 데이터 베이스권에 대한 침해행위
robots.txt 확인
무분별한 크롤링을 막기 위해 robots.txt로 권고안을 만들어 둠
웹서버에 요청을 보내도 로봇으로 판단되어 요청이 거부당하는 일이 생길수도 있음
따라서 요청하기 전 headers를 생성하여 같이 보내주면 됨.
웹 스크래핑을 하기 전 robots.txt를 확인해야 함
방법
- 최상위 주소 https://comic.naver.com 를 불러옴
- 주소에
/robots.txt를 추가

해석
Disallow : /- 모든 로봇에게 문서 접근을 차단한다
- 크롤러가 모든 경로의 데이터를 가져가지 말라라는 의미
Allow : /navercontest/2022- navercontest/2022 은 크롤링을 허용한다
- 크롤링을 허용할 웹 페이지를 의미
코드 작성
알고리즘
- 수집 하고자 하는 페이지의 URL을 알아본다.
-> table을 찾을 수 없어read_html()로 받을 수 없다. - 파이썬의 작은 브라우저 requests 를 통해 URL에 접근한다.
- response.status_code 가 200 OK 라면 정상 응답입니다.
- request의 response 값에서 response.text 만 받아옵니다.
- html 텍스트를 받아왔다면 BeautifulSoup 로 html 을 해석합니다.
- soup.select 를 통해 원하는 태그에 접근합니다.
- 리스트를 받아 데이터프레임으로 만듭니다.
- csv 파일을 만들어 저장한다.
0) 라이브러리 불러오기
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from datetime import datetime - 이 라이브러리들이 깔려있지 않다면
cmd를 연다pip install beautifulsoup4 pandas requests를 입력한다- 패키지를 다운 받는다.
requests: http 통신을 하기 위한 라이브러리BeautifulSoup- html 파서역할
- html 문서를 필요한 내용을 가져오기도 함
- html 문서를 예쁘게 만들기도 함
datetime: 시간을 가져와주는 라이브러리
1) URL 알아보기
- url을 불러오자!
url = 'https://comic.naver.com/webtoon/weekday'read_html로 불러와지는지 확인
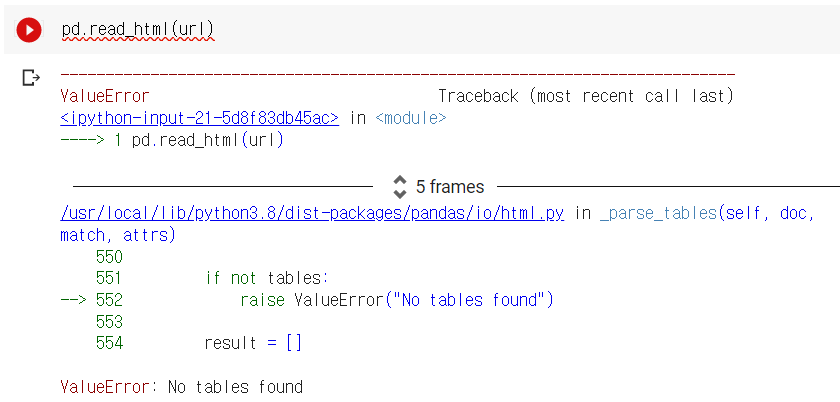
🤔오류 발생
2,3) requests로 URL에 접근하고 확인하기
- 웹서버에 요청하기
rsp = requests.get(url)- 요청 받아졌는지 확인하기
rsp.status_code- 결과 : 200 👈잘 받아졌다는 뜻
4,5) response.text 만 받고 BeautifulSoup 로 html 을 해석
- 2,3)에서 requests로 요청은 받았지만 html을 받은 것은 아닙니다.
- beautifulSoup로 변환해서 html로 받음
html = bs(rsp.text)6) soup.select 를 통해 원하는 태그에 접근
- 태그를 찾자
- 크롬으로 들어간 사이트에서 오른쪽 클릭 후
검사클릭 - Elements 왼쪽으로 두번째에 마우스 모양을 클릭하고 원하는 순위에 클릭하면 아래와 같이 태그가 보임
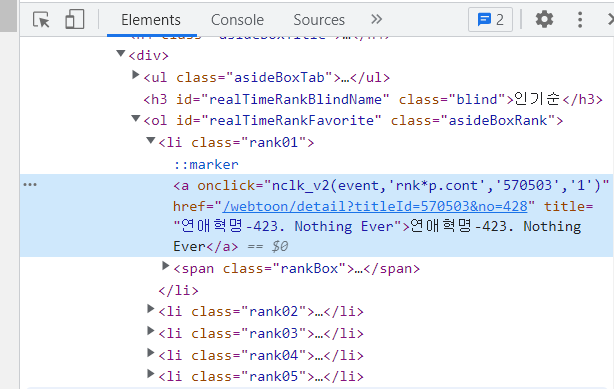
- soup으로 태그 찾기
- 찾은 태그를 이용하여 html에서 태그값만 찾아 저장할 거임
find: 클래스명으로 찾음select: html 코드에서 copy selector를 찾아서 적으면 빠름
- 찾은 태그를 이용하여 html에서 태그값만 찾아 저장할 거임
- 셀렉터
- Id는 하나의 요소에만 적용할 수 있다.
- Id 값은 앞에 #이 붙고, 클래스 값은 앞에 .이 붙는다
- 찾은 셀렉터로 코드 작성
rank=html.select('#realTimeRankFavorite > li > a')7) 리스트를 받아 데이터프레임으로
이 과정은 사실 하고 싶은대로 하면 되는데
나는 수업에서 table을 가지고 데이터 프레임으로 만들었기 때문에
리스트로도 데이터 프레임을 만들어보도록 하겠음
- 빈 데이터 프레임 생성
- title과 순위도 빈 리스트를 생성해줌
- 6)에서 찾은 rank 디렉토리를 제목과 순위를 찾아서 title과 순위에 저장
- 데이터 프레임에 리스트를 추가해줌
rank_df = pd.DataFrame()
title_list, rank_num = [], []
for cartoon in rank:
rank_num.append(cartoon['onclick'].split("'")[-2])
title_list.append(cartoon['title'])
rank_df['순위'] = rank_num
rank_df['제목'] = title_list
rank_df8) csv 파일로 저장
- file_name을 날짜+시간_cartoon.csv 파일로 생성
now = datetime.now()
file_name = f'{now.year}{now.month}{now.day}_{now.hour}h{now.minute}m_cartoon.csv'- csv 파일로 저장하고 열어보기
rank_df.to_csv(file_name, index = 0)
pd.read_csv(file_name)결과

