
8주차 일정
- 금
- 이범재 강사님 - SQL 윈도우 함수
- 월
- 박조은 강사님 - EDA 및 데이터 크기 다루기
- 전국 신규 민간 아파트 분양 가격 분석 - 전혀 다른 형태의 데이터 다루기, seaborn
- 박조은 강사님 - EDA 및 데이터 크기 다루기
- 화
- 박조은 강사님 - EDA 및 데이터 크기 다루기
- 통계청 KOSIS 데이터 분석 - 깔끔한 데이터의 이해와 국가통계포털 이용법
- 박조은 강사님 - EDA 및 데이터 크기 다루기
- 수
- 박조은 강사님 - EDA 및 데이터 크기 다루기
- 버거지수
- 박조은 강사님 - EDA 및 데이터 크기 다루기
- 목
- 복습과 과제, 인사이트 데이
- 메타인지
- 과제
- 복습과 과제, 인사이트 데이
학습 내용
📝20230206 박조은 강사님 수업내용 필기
📝20230207 박조은 강사님 수업내용 필기
📝20230208 박조은 강사님 수업내용 필기
👩💻과제 스토리지 절약(디스크공간) -> parquet
👩💻과제 메모리절약 -> downcast
일주일 내용 키워드 정리
tidy data
- 깔끔한 데이터(tidy data) : 한 열에 하나의 변수만 있는 데이터
pd.melt: 열에 있는 데이터를 행으로 녹인다.id_vars: 기준이 될 열 설정(어떤 행을 기준으로 녹일 것인지)
- 데이터 종류 : long-term과 wide-term
데이터 타입 변경
astype(): 데이터프레임이나 시리즈의 타입을 변경해줄 수 있다.df[col].replace(' ', np.nan).astype(float)- 결측치가 섞여 있을 땐
pd.to_numeric사용- errors 속성을 'coerce' 로 설정해주면 결측치값을 변경해준다.
pd.to_numeric(df[col],errors='coerce')
데이터 프레임
- 컬럼명 다시 설정 하기
rename(columns={'원래 컬럼명:'변경 컬럼명'})
- nlargest(), nsmallest()
DataFrame.nlargest(n, columns, keep='first')- 열 별로 내림차순, 오름차순으로 정렬된 다음 처음 n개의 행을 반환한다.
nlargest()→sort_values(ascending = False).head(n)과 같음nsmallest()→sort_values(ascending = True).head(n)와 같음
깊은복사 vs 얕은 복사
- .copy()로 깊은 복사를 할 수 있음
- 원본에 영항 x
- 얕은 복사는 원본도 함께 변경될 수 있음
메모리 줄이기
1. 컬럼 삭제
- drop을 사용하여 제거
df.drop(labels = ['col1','col2'], axis=1)- 컬럼을 제거해줌으로 용량을 줄일 수 있다.
2. 데이터 타입 변경
- 음수가 없이 양수만 있는 int 값일 경우 uint 값으로 데이터타입을 변경해주면 용량이 줄어들 수 있다.
- 수의 크기가 적을 경우 int에서도 범위가 작은 데이터 타입을 사용해주면 용량이 줄어들 수 있다. (예: 수의 범위가 -100~100이라면
int8사용)
# int의 경우
pd.to_numeric(df[col], downcast='unsigned')
# float의 경우
pd.to_numeric(df[col], downcast='float')- object 타입일 경우 모든 데이터가 유일값이 아니라면
category데이터 타입을 사용해주면 용량이 줄어들 수 있다.
3. 불러올 때부터 줄이기
pd.read_csv할 때의 옵션으로 dtype을 지정해주면 됨.
스토리지 절약
parquet 형식으로 변환
- parquet
- 효율적인 데이터 저장 및 검색을 위해 설계된 오픈소스
- 열 지향 데이터 포맷
- to_parquet
df.to_parquet('파일저장명.parquet.gzip')데이터 그룹화
groupby()pivot_table()crosstab()
시각화
- 시각화 라이브러리
- seaborn -> 연산을 바로 해줌
- plotly -> 수치, 범주형 모두 표현 가능
- seaborn, pandas 에서는 histogram은 수치데이터만 제공
히스토그램
수치 데이터를 분석할 때 가장 먼저 히스토그램으로 데이터 분포 확인
- pd.hist() : 수치데이터
- 범주형 일 때는 기본값이 → count
- 수치형 일 때는 기본값이 → sum
- sns.pairplot() : 여러 개의 수치형 변수로 짝을 지어 표현하기 좋다.
facetGrid와 PairGrid 의 차이점
- facetGrid
- 데이터 세트의 하위 집합내에서 개별적으로 변수의 분포 또는 여러 변수 간의 관계를 시각화하려는 경우에 유용
- 하나의 범주형 변수를 쪼개고 나눠서 시각화
- relplot : scatter, lineplot,
- join : scatter, line, reg, resid, hex
- lmplot : scatter, reg, resid
- displot : his, kde
- catplot : strip, swarm, bar, box, boxen, violin, count
- pairGrid
- 작은 서브 플롯의 그리드를 빠르게 그려 각각의 데이터를 시각화
- 여러 변수의 서브플롯
- pairplot(hist, kde)
- ridgeplot
- 하나의 범주형 변수를 범주값에 따라 여러개로 나눠 그려주는 facet Grid와 달리 pairGrid는 여러 변수를 나눠 그림
catplot(categorical)
- barplot : 대표값만 표시
- boxplot : 사분위수 표시. 강건(robust)하여 내부 값이 바뀌어도 plot의 형태가 변하지 않을 수 있음
- violinplot : 밀도를 표시하는 plot으로 카테고리값에 따른 각 분포의 실제 데이터 또는 전체 형상을 보여준다
- swarmplot : scatter plot의 단점을 해결하기 위해 생김
- stripplot
- pointplot
상관계수
두 변수간에 어떤 선형적 또는 비선형적 관계를 갖고 있는지 분석
상관 계수(Correlation coefficient)는 두 변수간의 연관된 정도를 나타낼 뿐 인과관계를 설명하는 것은 아님!
folium
버거지수를 folium으로
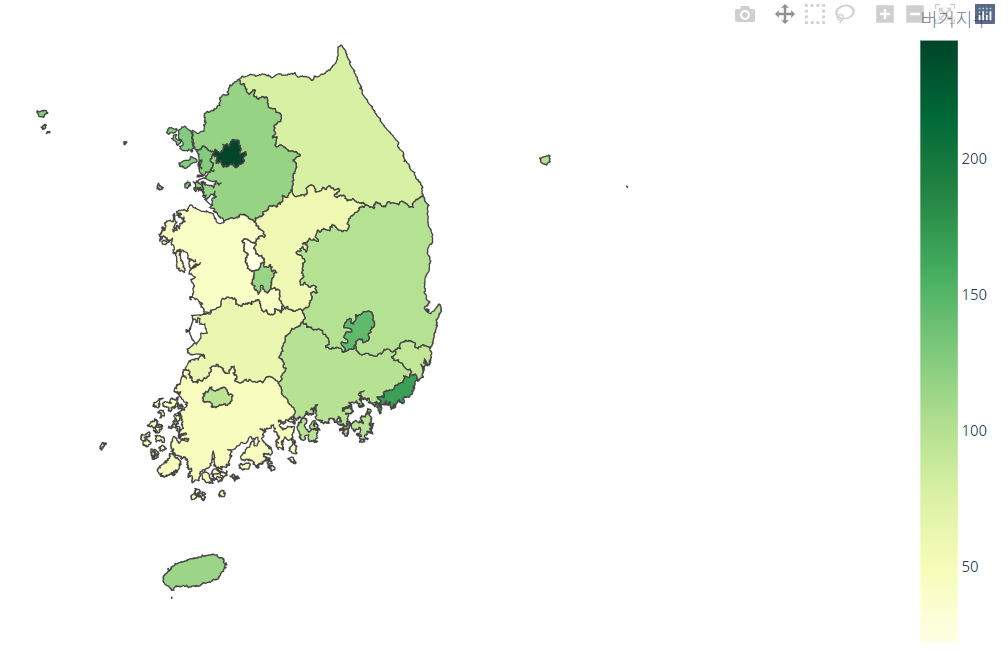
소감
이번 주는 EDA와 다양한 시각화를 해보았고 용량이 큰 데이터에 대한 전처리하는 방법도 배웠다.
머리가 터질 것 같았지만 복습을 해내야지! 라는 생각으로 열심히 배우려고 했다.
그리고 미니 프로젝트가 끝난 시점이라 마음이 붕 떴었는데 내용이 어려워서 다시 자리 잡았다..
미니 프로젝트에서 어려운 부분이 수업으로 나왔는데 folium에 대한 설명이 적어서 아쉬웠다.
개인적으로 부산의 버거지수를 시각화 해보고 싶었는데 부산 경계지도를 그리는 것부터 막혀서 아직도 해내지 못했다.
만약 이걸 풀게 된다면 꼭 게시글을 올려 다른 사람들은 쉽게 할 수 있었으면 좋겠다..
이번 주부터 seaborn 튜토리얼 따라 쓰기를 시작했다.
굉장히 작은 양을 하는 것이라 부담이 없어서 매일매일 커밋하기도 좋고
수업 내용을 복습하는 시간도 뺏기지 않고 습관을 만들 수 있어서 정말 좋은 스터디이다.
꾸준히 해서 마스터까지 꼭 해야지!
이렇게 쓰고보니 스터디를 잘 활용해야겠다는 생각이 들었다.
좀 있으면 sqld 시험 접수기간이던데
sqld 마스터? 이런 식으로 같이 공부하는 사람들이 있으면 같이 스터디 해도 괜찮을 것 같다.
