➢Overview
JDK21 의 등장으로 인해 Java 에서도 경량 thread 인 virtual thread 가 등장하였습니다. 기존의 Kotlin 의 coroutine 과 어떤 차이가 있는지 확인해보며 JVM 기반의 프로젝트의 방향성에 대한 저의 생각을 공유하고자 합니다.
먼저 virtual thread 와 비교하기전 코루틴과 비동기 처리에 대해 알아보고, 사용법보단 어떻게 동작하는지에 중점을 두고 성능을 향상시키는 것도 좋지만 개발자의 실수로 인해 오히려 성능저하가 되는것을 막기 위한 글 입니다.
❓Coroutine 이란?
📖 단순정의
코루틴은 Kotlin에서 도입된 가벼운 병행 처리 메커니즘으로, 비동기 및 비차단 프로그래밍을 단순화합니다. 코루틴은 코드 실행을 중단하고 재개할 수 있는 구조적인 방식을 제공하여 기존 스레드 모델의 복잡성 없이 협력적인 멀티태스킹을 가능하게 합니다.
우리는 협력적 멀티태스킹, 병행 처리 라는 단어에 집중해야합니다.
어떻게 협력적 멀티태스킹, 병행처리(Concurrency) 가 가능할까요?? 그리고 이 단어들에 집중에서 글을 읽어주시면 감사하겠습니다.
🚴♂️ 비선점 스케줄링
JVM 에서 Thread 는 Kernel Thread 와 User Thread 가 1:1 로 매핑됩니다.
따라서 다른 쓰레드를 사용한다면 운영체제 수준에서의 Context Switching 이 발생하고 이 비용은 저렴하지 않습니다.
코루틴은 비선점 스케줄링 이기때문에 사용자가 스케줄링을 정의합니다 따라서 Kernel Thread 에서의 Context Switching 이뤄지지 않고 User Thread 내에서 Context Switching 이 이뤄지며 협력적인 멀티태스킹이 가능합니다.
🏆 CoroutineContext
🛠️ Dispatcher
Coroutine Dispatcher는 코루틴의 실행을 담당하는 스레드나 실행 환경을 지정하는 객체입니다. 코루틴이 어디에서 실행될지, 어떤 방식으로 실행될지를 결정하는 역할을 합니다. Dispatcher는 CoroutineContext의 중요한 구성 요소이며, 코루틴의 성능과 효율성에 큰 영향을 미칩니다.
class Main {
suspend fun main() = coroutineScope {
println("Main Thread ${Thread.currentThread().name}")
repeat(1000) {
launch {
List(1000) { Random.nextLong() }.maxOrNull()
val threadName = Thread.currentThread().name
println("Running on $threadName")
}
}
}
}
Main Thread main
Running on DefaultDispatcher-worker-8
Running on DefaultDispatcher-worker-2
Running on DefaultDispatcher-worker-3
Running on DefaultDispatcher-worker-7
Running on DefaultDispatcher-worker-4
Running on DefaultDispatcher-worker-6
Running on DefaultDispatcher-worker-5
Running on DefaultDispatcher-worker-6
Running on DefaultDispatcher-worker-1
...Dispatcher default 값이 core 의 수(2이상) 의 값으로 되어있기때문에 Mac m1 pro 기준 8개의 Thread 에서 동작하는것을 볼수있습니다.(IO는 64개 입니다)
💤 sleep vs delay
Thread sleep 과 delay 는 동일하게 동작하는것 처럼 느껴집니다.
하지만 Thread sleep 은 지양 해야한다고 하죠 왜 지양해야 하는지 delay 는 왜 괜찮은지 위 설명들을 다시 리마인드 해보며 톺아 보겠습니다.
suspend fun main() = coroutineScope {
println("Main Thread ${Thread.currentThread().name}")
val start = System.currentTimeMillis()
repeat(1000) {
launch {
List(1000) { Random.nextLong() }.maxOrNull()
val threadName = Thread.currentThread().name
// delay(100) or Thread.sleep(100)
println("${System.currentTimeMillis() - start} Running on $threadName")
}
}
}delay 203 sleep 12954 엄청난 성능 차이가 납니다.
위에 Dispatcher 에서 설명했던 것처럼 Coroutine 은 default 값이 8개로 설정되어 있으며 Thread 를 자유롭게 넘나들며 작업을 진행합니다.
여기서 Kernel Thread 가 개입 하지 않고 User Thread 에서 제어 하는 장점
기존에 쓰레드를 이동하기 위해선 Kernel Thread 에서 Context Switching 이 이뤄지는데 코루틴은 User Thread 에서 제어가 됩니다.(비선점 쓰레드)
하지만 Thread.sleep() 을 한다면 Thread Blocking(TIMED_WAITING) 이 이뤄집니다. 따라서 쓰레드 사용, 진입자체가 되지 않습니다.
아래 그림을 참고한다면 어렵지 않게 이해할 수 있습니다.
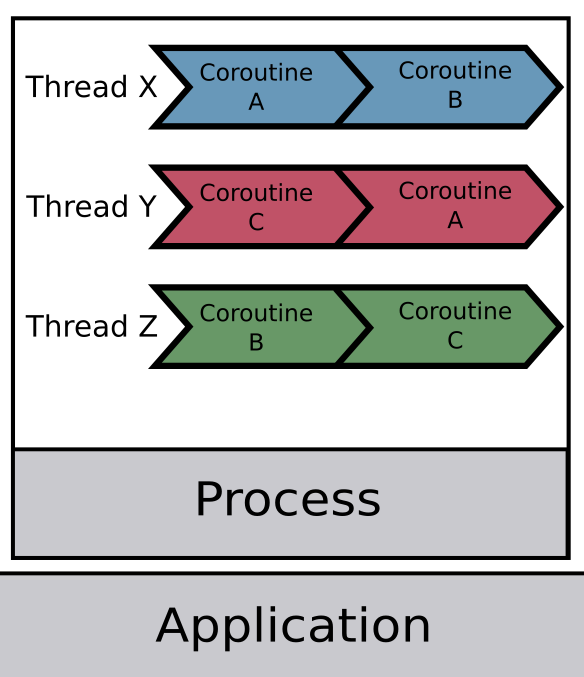
🍃 In Spring
당연하지만 기술스택을 도입할땐 왜 써야하는지 어떤 장단점이 있는지 알아봐야 합니다. Kotlin 을 사용하는 Backend framework 로는 대표적으로 Spring, Ktor 가 있습니다. 그 중 많이 사용하는 Spring 에서 어떻게 활용할 수 있는지 확인해보겠습니다.
🤼♂️ aync/non-blocking
Spring Cloud Gateway 를 구성하면 Webflux 를 사용하였는데 API Gateway 역할을 하는 SCG 에서 synchronous 하게 동작한다면 성능저하 로 인한 병목현상으로 장애가 발생할 수 있습니다.
SCG 성능 개선기 를 참고하면 synchronous 하게 동작하는 log 하나로도 성능에 유의미 한 영향을 끼칩니다.
따라서 Gateway 같은 Application 에선 비동기/논블로킹 하게 동작해야 합니다.
꼭 Gateway 만 해당된 다는 뜻이 아닙니다. 비동기/논블로킹 으로 동작해야 하는 Application 을 뜻합니다.
Java 에서 비동기 코드를 처리할땐 주로 Mono, Completablefuture 을 사용하는데 Coroutine 과 가독성 측면에서 비교하겠습니다.
FlatMap Hell
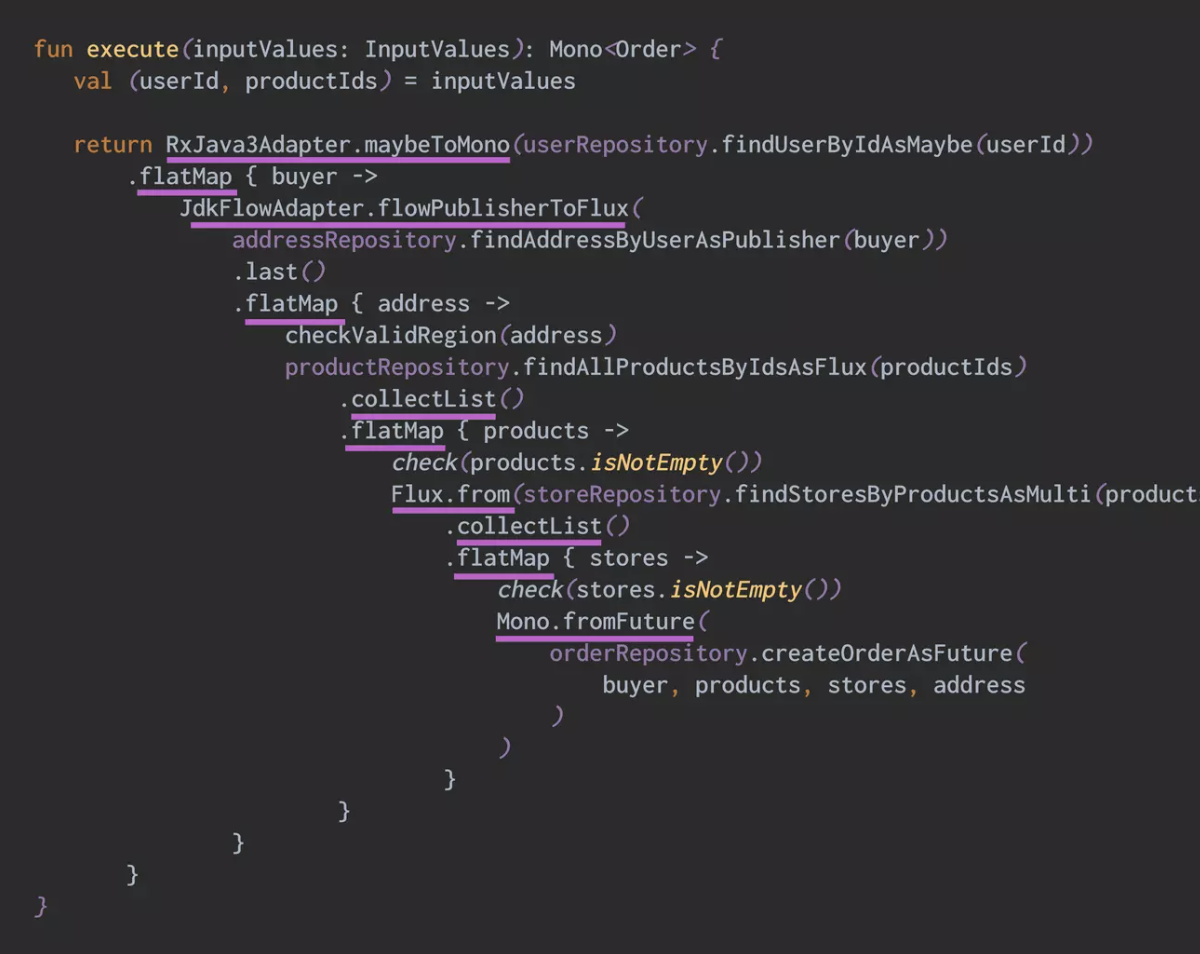
Coroutine
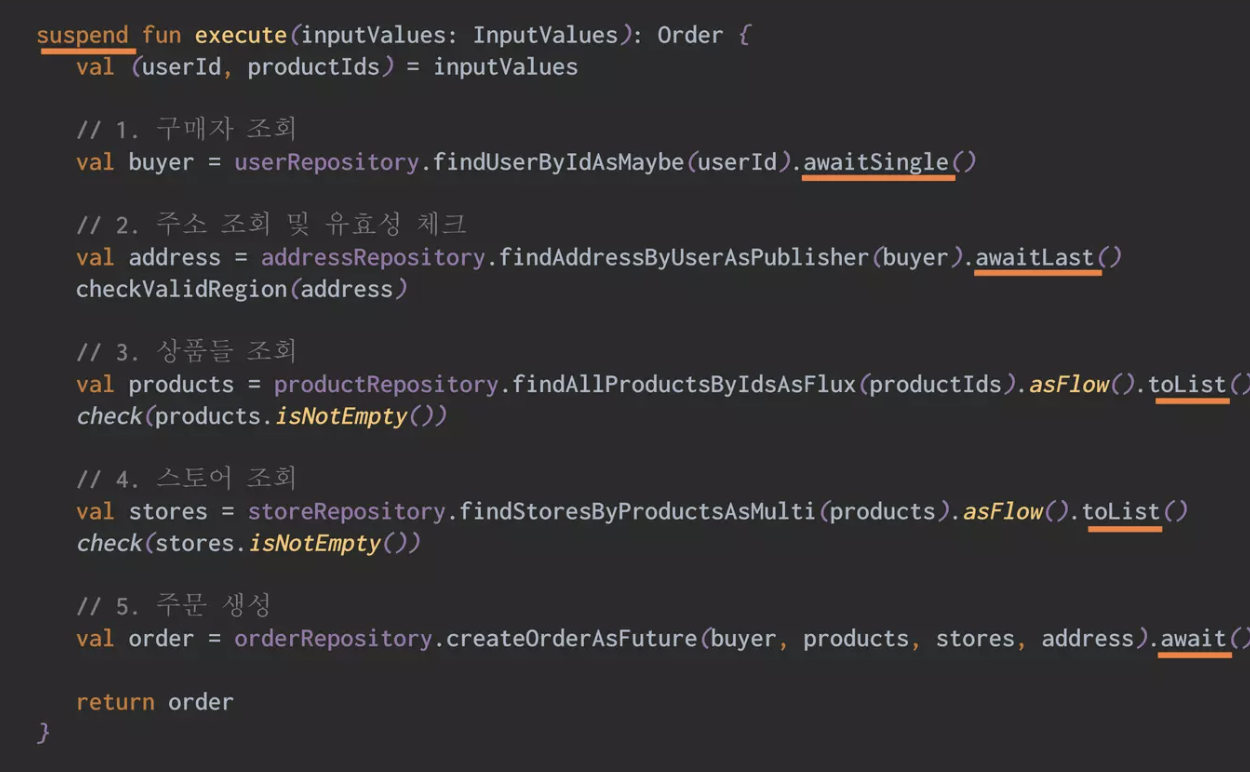
출처 :당근마켓 Server 밋업
좋은 사례가 있어 가져왔습니다. Subscribe hell, flatMap hell 등 callback 지옥 같은 함수 입니다.
가상 쓰레드로 성능이점을 제외하더라도 코드 읽는데 많은 시간을 사용하는 개발자들은 가독성 자체만으로도 많은 이점을 얻을 수 있다는 것을 공감 할 것입니다.
이러한 코루틴의 협력적 멀티태스킹 은 가독성을 뛰어나게 합니다.
💻 I/O
Coroutine 은 CPU 연산을 사용할때 뿐만아니라 I/O 작업에서도 이점을 가질 수 있습니다.
Spring 에선 CoroutineRepository 와 같은 Interface 도 제공 합니다.
자세한건 docs 참고 바랍니다.
⛓️💥 Exception Handling (Transaction)
저는 일반 MVC 에서 Exception 을 throw 하면 Exception Handler 와 RestControllerAdvice 에서 해당 Exception 에 맞게 Client 에게 보여주는 방법을 많이 사용 했었습니다.
하지만 Spring 의 Transactional annotation 은 AOP 로 동작하기에 JPA 를 사용할경우 persistence context 가 공유되지 않을 뿐더러 개발자의 의도에 맞는 Transaction 을 보장하지 않을 것 입니다.
이를 handling 하기 위해선 Coroutine 에서의 전파가 어떻게 이뤄지는지 등을 알아볼 필요가 있습니다. 다음 몇가지 예시를 준비해봤습니다.
테스트 환경
- JDK17
- Spring Boot 3.3.0
@Transactional
override fun runTimeException(): String {
val person = Person(
name = "우영",
20,
)
withContext(Dispatchers.IO) {
personRepository.save(person)
}
throw DoRunTimeException()
}다음 예시를 한번 보겠습니다. 일반적인 동기 처리를 한다면 Transaction 이 시작 되고 RuntimeException 을 throw 하기에 Roll-back 이 되는 것을 기대할 수 있겠지만 withContext 로 새로운 Thread 에서 IO 작업이 이뤄지고 flush 가 발생하여 개발자의 의도에 맞지 않은 결과를 얻을 것 입니다.
@Transactional
suspend fun create(): String {
return coroutineScope {
val personSave = async {
personPort.save()
println("person save ${this.coroutineContext[Job]}")
println("person save ${this.coroutineContext[Job]?.parent}")
}
val cartSave = async {
println("cart save ${this.coroutineContext[Job]?.parent}")
println("cart save ${this.coroutineContext[Job]}")
cartPort.save()
}
joinAll(personSave, cartSave)
"JobEnd"
}
}위와 코드는 Transaction 을 Facade pattern 으로 구현한 코드 입니다.
cart 에서 예외가 발생했을때 어떻게 될까요??
- create() 는 Transactional 하게 동작하지 않는다.
- Client 는 Error 상황을 받지만 실제로 person 은 commit 됨
이유는 Coroutine Job 이 실행되는 Context 가 다릅니다.
child
person save DeferredCoroutine{Active}@77309127
cart save DeferredCoroutine{Active}@7f751a9f
parent
person save ScopeCoroutine{Active}@6be858a1
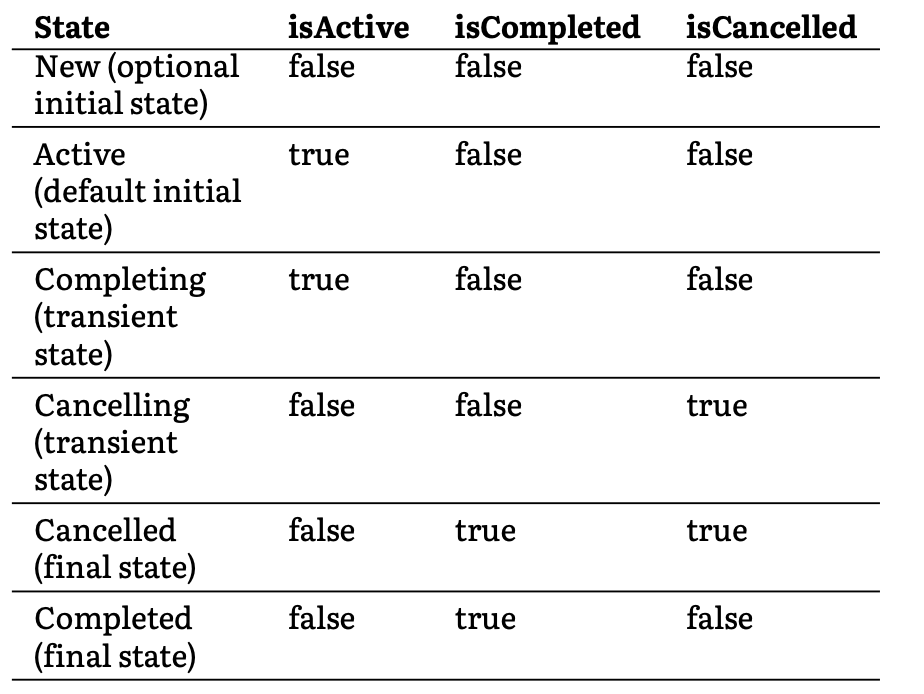
cart save ScopeCoroutine{Active}@6be858a1Coroutine Job Lifecycle 과 State 에 따른 값들을 나타내는 사진으로 설명을 대신 하겠습니다.
- Lifecycle
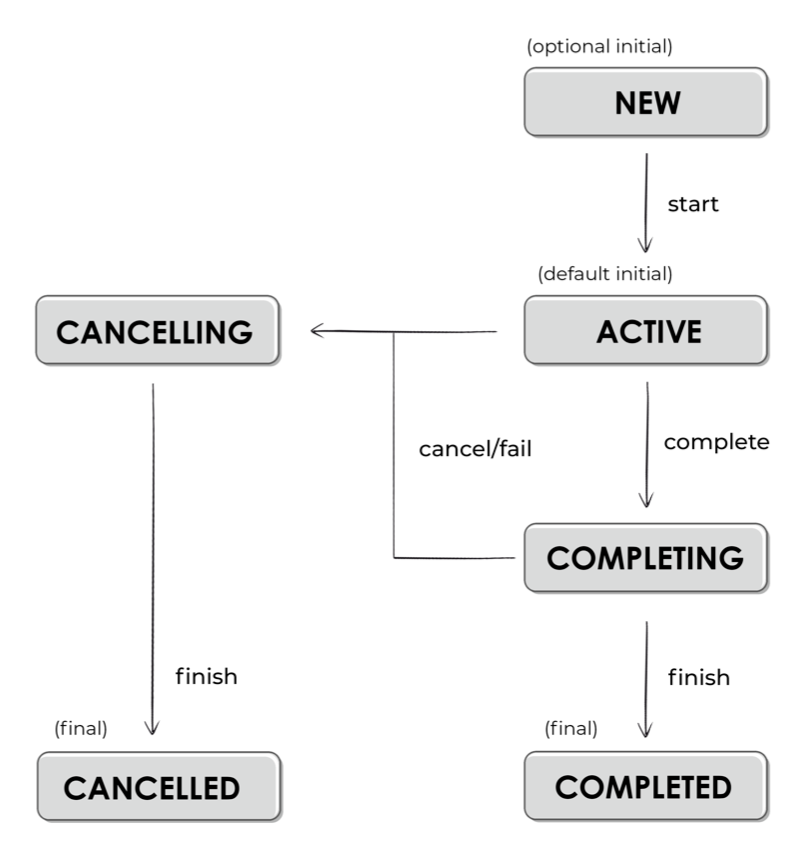
- State
다음과 같은 방법으로 상황에 맞는 해결을 할 수 있을거라 생각합니다.
- supervisorscope 사용
- try-catch
- runCatching
- CoroutineExcpetionHandler
개인적으로 아쉬운점
-
Log
troubleshooting 을 할때 Log 는 필수입니다. 보통 TraceId 로 request 에 따른 logging 을 진행할텐데 Coroutine 을 사용한다면 다른 Thread 로 되어 추적하기 어렵다는 점 입니다.
물론 극복은 할 수 있습니다. Coroutine MDC Context 처럼 Coroutine MDC Context 를 공유하면 되지만 이러한 설정을 모른다면 어려움을 겪을 것 입니다. -
Transaction
보통 Spring 을 사용해서 원자성을 보장하기 위해 @Transactional 을 사용합니다. 하지만 Coroutine 에서는 @Transactional 이 동작하지 않습니다. Facade Pattern 등을 활용하거나 webflux 가 강제 된다는 점 입니다.
❓ 비동기 처리는 항상 옳을까?
설명만 들으면 비동기처리가 무조건 좋다 생각이 듭니다.
그럼 항상 비동기 처리가 옳은지 간단한 예제를 통해 알아보도록 하겠습니다.
환경
- JDK 17
Java 의 경우 Thread 개수는 200개로 하였습니다.
Java ExecutorService
long startTime = System.currentTimeMillis();
ExecutorService execute = Executors.newFixedThreadPool(200);
int cnt = Integer.MAX_VALUE / 100;
AtomicLong sum = new AtomicLong();
CountDownLatch latch = new CountDownLatch(cnt);
for (int i = 0; i < cnt; i++) {
execute.submit(() -> {
sum.getAndIncrement();
latch.countDown();
});
}
latch.await();
long endTime = System.currentTimeMillis();
execute.shutdown();
System.out.println(endTime - startTime);출력: 7273
val startTime = System.currentTimeMillis()
val cnt = Integer.MAX_VALUE / 100
val sum = AtomicLong()
coroutineScope {
for (i in 0..cnt) {
launch {
sum.getAndIncrement()
}
}
}
val endTime = System.currentTimeMillis()
println(endTime - startTime)출력: 7153
현재 Coroutine 과 Java 의 ExecutorService 를 활용한 cpu, memory 성능 분석은 큰 의미를 가지진 못합니다. Coroutine 은 Integer.MAX_VALUE / 100 만큼 for 문이 실행될때마다 코루틴 스코프가 생성이 되고, Java 의 경우 200 개의 Static 한 Thread 를 생성하기 때문입니다.
유의미한 지표는 메소드 완료시점인데 차이가 유의미 하지 않습니다.
하지만 동기로 처리한다면 어떻게 될까요?? 과연 비동기보다 낮은 성능을 보여줄지 테스트 해보겠습니다.
동기
long startTime = System.currentTimeMillis();
int cnt = Integer.MAX_VALUE / 100;
AtomicLong sum = new AtomicLong();
for (int i = 0; i < cnt; i++) {
sum.getAndIncrement();
}
long endTime = System.currentTimeMillis();
System.out.println(endTime - startTime);출력: 154
오히려 동기처리 성능이 뛰어난걸 확인할수 있습니다.
그 이유로는 다음과 같다고 생각합니다.
- Kotlin 의 경우 코루틴 스코프가 생성의 오버헤드 발생
- Java 의 Executor Service 의 Context Switching 비용 발생
- getAndIncrement 의 동기화 작업처리
적절한 예시인지는 모르겠으나, 모든것을 만족시키는 솔루션은 없다는것을 증명하고싶었습니다. 위 결과를 통해 비동기 처리가 항상 옳은 선택지가 아니라는 것을 인지 한다면 좋을것같습니다.
마치며
개인적으로 Kotlin 의 이점은 null safety 와 coroutine 이 가장 크다고 생각 하는데 매우 만족하고 있습니다. Coroutine 과 비동기 처리에 대해 간략히 소개했는데 다음에 기회가 된다면 JDK21(Project Loom) 과 비교해보겠습니다.
Reference
