kafka 란?
Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼이다. 여러 소스에서 데이터 스트림을 처리하고 여러 사용자에게 전달하도록 설계됨, 간단히 말해 A지점에서 B지점까지 이동하는 것뿐만 아니라 A지점에서 Z지점을 비롯해 필요한 모든 곳에서 대규모 데이터를 동시에 이동할 수 있다.
kafka 구조
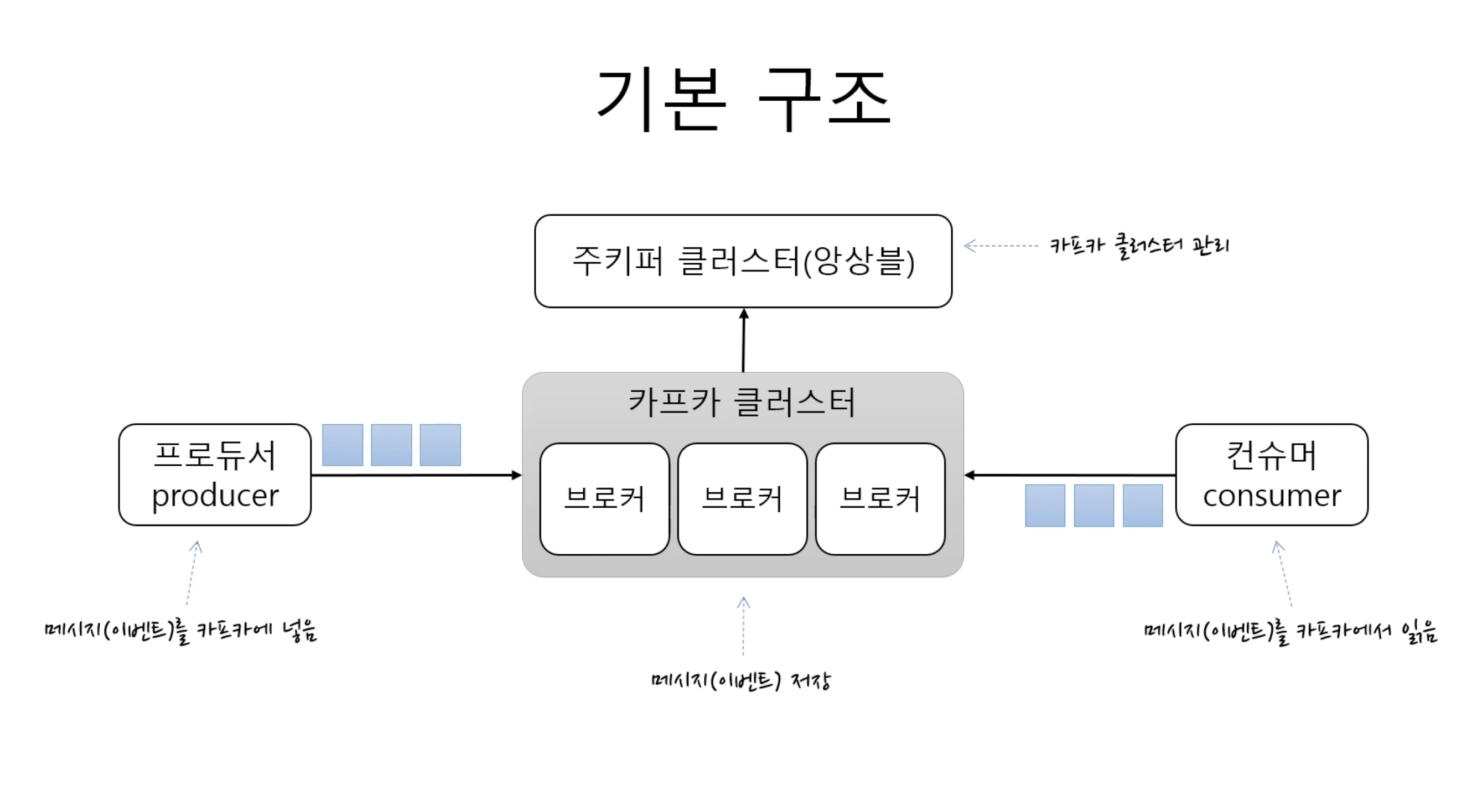
-
카프카 클러스터 : 메시지를 저장하는 저장소(여러개의 브로커로 구성되어있음)
- 브로커: 각각의 서버
-
주키퍼 클러스터: 카프카 클러스터를 관리
-
프로듀서: 클러스터에 메시지를 넣음
-
컨슈머: 클러스터에있는 메시지를 읽음
-
kafka는 토픽이라는 단위로 메시지를 구분합니다. 파일시스템의 폴더와 유사
-
한개의 토픽은 한개이상의 파티션으로 구성됨
- 파티션은 메시지를 저장하는 물리적인 파일
정리를 하자면 프로듀서와 컨슈머는 토픽을 기준으로 메시지를 주고 받는다.
여러 파티션과 컨슈머
컨슈머는 컨슈머 그룹에 속할 수 있다. 아래사진 참고
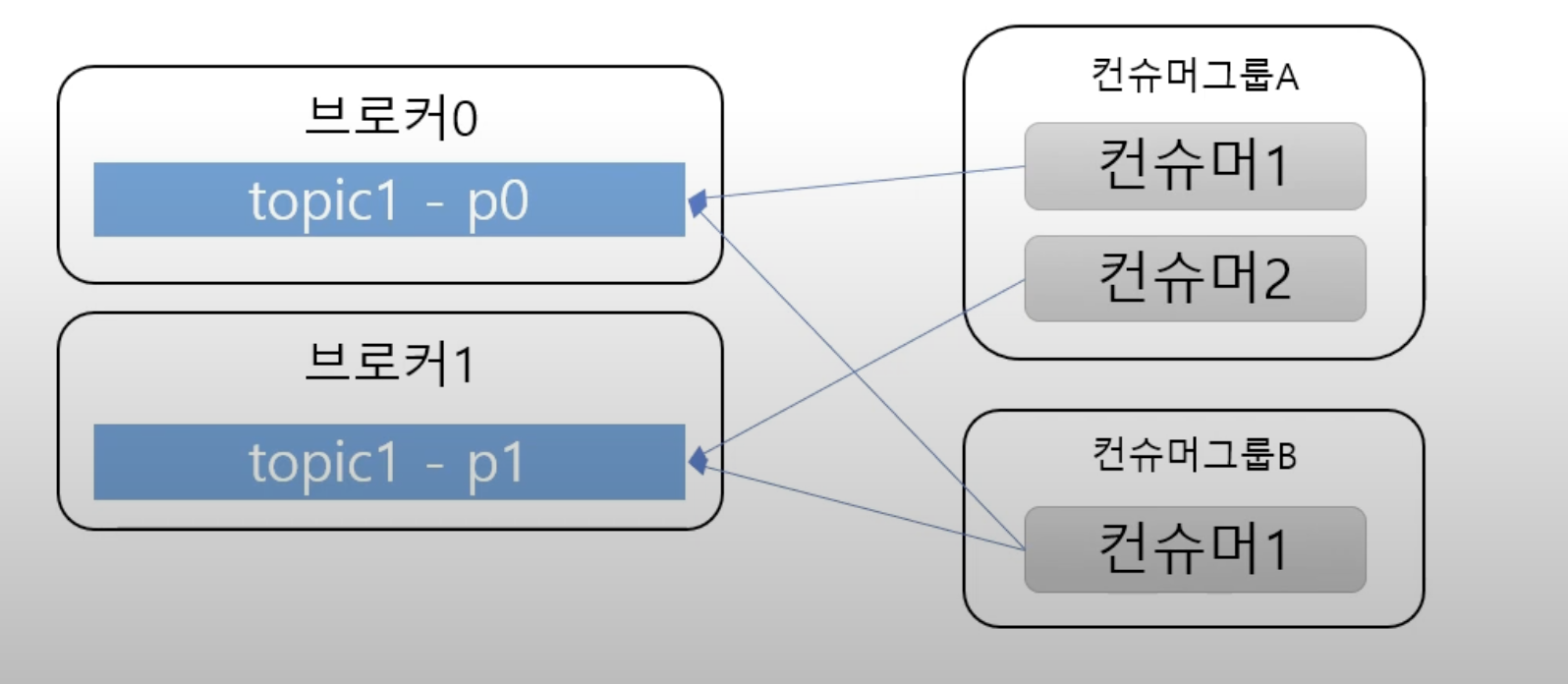
한개 파티션은 컨슈머 그룹의 한 개 컨슈머랑만 연결이 가능하다
- 즉 컨슈머 그룹끼리 있는사람은 한 파티션을 공유할 수 없다는것
- 한 컨슈머 그룹 기준으로 파티션의 메시지는 순서대로 처리
kafka 기능
묶어서 보내기, 묶어서 받기(batch)
- 프로듀서: 일정 크기만큼 모아서 전송 가능
- 컨슈머: 최소 크기만큼 메시지를 모아서 조회 가능
batch로 일괄 처리를 할 수 있기때문에 낱개로 처리할때보다 처리량 을 향상 시킬 수 있다는것.
처리량 확장이 쉽다.
- 용량 한계 -> 브로커, 파티션 추가
- 컨슈머 속도가 느림 -> 컨슈머 (+파티션) 추가
리플리카 - 복제
리플리카란 파티션의 복제를 뜻한다.
- 복제 수 만큼 파티션의 복제본이 각 브로커에 생김
리더와 팔로워로 구성되어있다
- 프로듀서, 컨슈머는 리더로만 메시지를 처리한다.
- 팔로워는 리더로부터 복제
장애대응(고가용성)
서버를 이중화 하는것과 마찬가지라고 생각하면 될거같다. 리더가 장애시 팔로워가 리더가된다. 리더가 있을때는 팔로워는 복제만 하고있는것과같다.
메시징 흐름
프로듀서
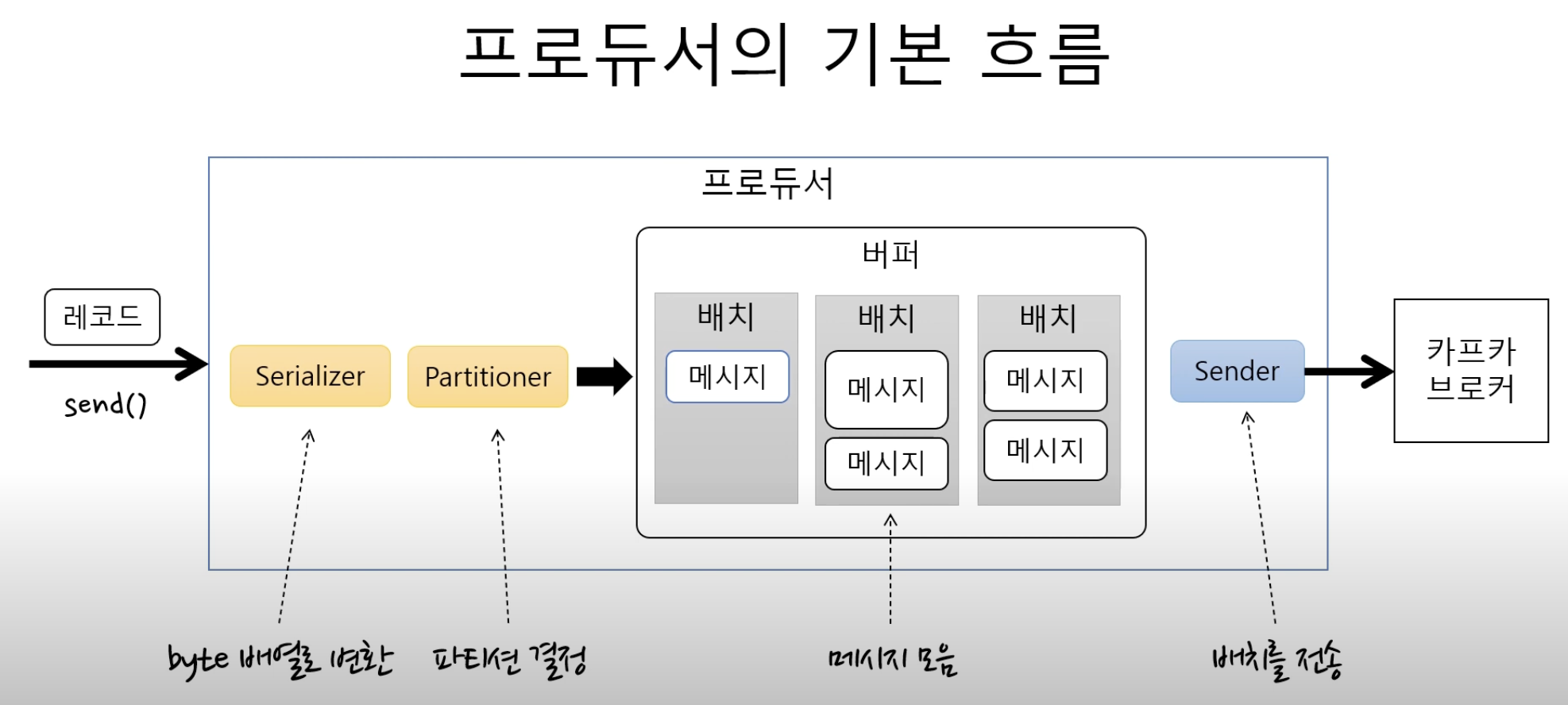
send() 메서드로 메시지를 전송하면
partitioner 을통해서 어느토픽의 파티션으로 보낼지 결정
sender
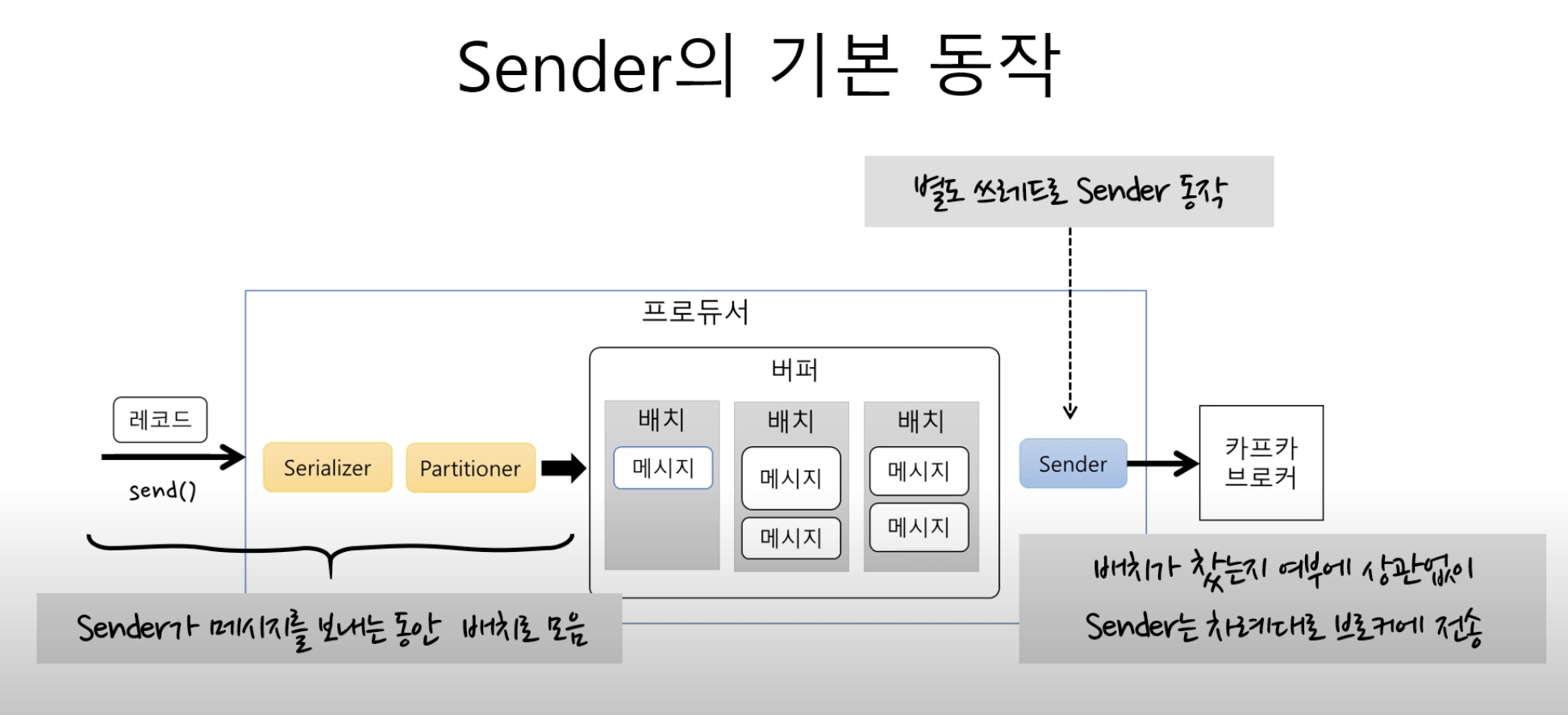
주요 속성
- batch.size: 배치 크기, 배치가 다 차면 전송하는 메서드
- 사이즈가 너무 작으면 배치에 저장될 수 있는 메시지가 줄고 전송 수가 많아지기때문에 처리량 이 떨어짐
- linger.ms: 전송 대기 시간 지정
- 대기시간이없으면 바로 전송 있다면 그 시간뒤에 전송
- 대기시간이 있다면 배치에 쌓임 -> 처리량 증가
Kafka 사용해보기
설치/설정
docker hub를 이용해서 kafka 를 설치
docker pull bitnami/kafka:3.3.2-debian-11-r38
zookeeper/kafak 설치
docker-compose.yml
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:2.12-2.5.0
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock수정
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: bitnami/kafka:3.3.2-debian-11-r38
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
ALLOW_PLAINTEXT_LISTENER: "yes"
volumes:
- /var/run/docker.sock:/var/run/docker.sockdocker ps -a

실행이 되지않아 log를 확인해보니
afka 02:11:11.67 WARN ==> You set the environment variable ALLOW_PLAINTEXT_LISTENER=yes. For safety reasons, do not use this flag in a production environment.
kafka 02:11:11.70 INFO ==> Initializing Kafka...
kafka 02:11:11.72 INFO ==> No injected configuration files found, creating default config files
kafka 02:11:11.95 INFO ==> Initializing KRaft...
kafka 02:11:11.95 WARN ==> KAFKA_KRAFT_CLUSTER_ID not set - If using multiple nodes then you must use the same Cluster ID for each one
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Not enough space' (errno=12)도커 컨테이너 내부의 메모리 할당량보다 여기에 사용되는 메모리가 더 많아서 생기는 문제
docker stats [컨테이너이름]으로 확인 여러가지도 확인가능하다.

자세한 내용은 너무 길어질거같아 아래링크에서 다뤘습니다.
이슈 해결
설정
설치 후 추가설정 bitnami 기준 경로
bitnami 는 기본적으로 root가 아니기때문에 exec 명령어를 실행할때 root를 명시해줘야 합니다.
docker exec -u root -it kafka
apt-get update
apt-get install vim
$ docker exec -it kafka /bin/bash
$ bash# cd /opt/bitnami/kafka/config
$ bash# vim server.properties이러면 다음과 같이 접속이되는데 Socket Server Settings 에서 listeners와 advertised.listeners의 주석 처리를 해제하고 후자에는 공인 ip를 작성한다.
listeners
카프카 브로커가 내부적으로 바인딩하는 주소advertised.listeners
카프카 프로듀서, 컨슈머에게 노출할 주소. 설정하지 않을 경우 디폴트로 listeners 설정을 따른다.before
delete.topic.enable=true
auto.create.topics.enable=true추가
after
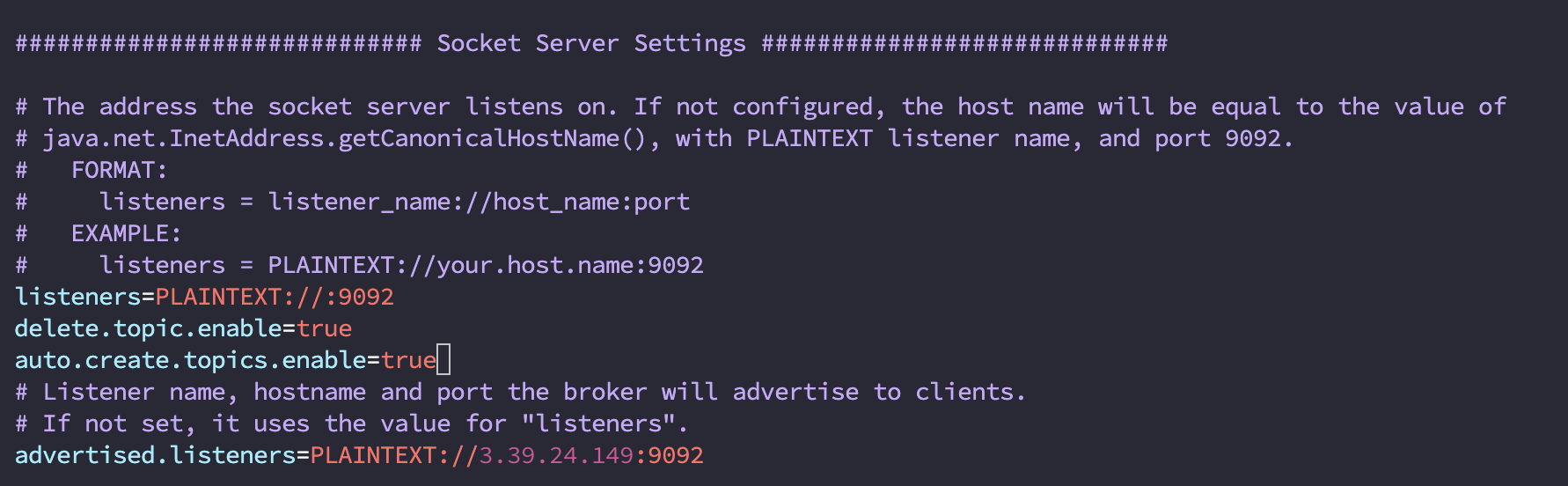
설정을 마쳤으면 도커 재시작
docker stop kafka
docker start kafkaKafka 테스트
터미널을 2개 켜서 1개는 프로시저 1개는 컨슈머 역할을 맡게 하여 테스트 했습니다. 둘다 kafka 컨테이너 안에서 실행하면 됩니다.
producer
kafka-console-producer.sh --topic exam-topic --broker-list localhost:9092후에 > 가 나오면 hello kafka를 입력해봤다.

consumer
kafka-console-consumer.sh --topic exam-topic --bootstrap-server localhost:9092 --from-beginning출력메시지

Spring Boot 와 연동
버전 확인
Spring boot 와 Kafka 연동되는 버전을 뜻한다.

bitnami 내가 설치한 버전은 3.3.2 이기때문에 내가 사용하는 Spring boot 3.0.x 와 호환이 된다.
Spring Kafka 주요 기능
-
KafkaTemplate:
이는 Kafka에 메시지를 보내는 데 사용되는 높은 수준의 추상화를 제공합니다. KafkaTemplate는 주로 메시지를 생산하는 쪽에서 사용되며, 메시지 전송의 간결성과 편의성을 제공합니다. -
KafkaMessageListenerContainer:
이 컨테이너는 Kafka 메시지를 비동기적으로 소비할 수 있게 해주는 역할을 합니다. 즉, Kafka에서 메시지를 수신하면 해당 메시지를 처리할 수 있는 리스너를 호출합니다. -
@KafkaListener:
이 애노테이션은 메서드를 Kafka 메시지 리스너로 지정합니다. KafkaMessageListenerContainer는 이 애노테이션을 통해 메시지를 처리할 메서드를 찾아 메시지를 전달합니다. -
KafkaTransactionManager:
Kafka 트랜잭션을 관리하는 데 사용되는 Spring의 트랜잭션 관리자입니다. 이를 통해 Kafka 메시지의 전송과 처리를 원자적인 작업으로 관리할 수 있습니다. -
spring-kafka-test jar with embedded kafka server:
이 기능은 통합 테스팅을 위해 사용됩니다. 내장 Kafka 서버를 포함한 spring-kafka-test jar를 제공하여, 실제 Kafka 서버 없이도 Kafka 기능을 테스트할 수 있습니다.
설정
builde.gradle
implementation 'org.springframework.kafka:spring-kafka'application.yml
spring:
kafka:
bootstrap-servers: ENC(V7ZQ6ejRGHvYoSUQbPa4mrc5dxRDh6IKg1Z9tLyOKmY=)
consumer:
group-id: foo
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer-
bootstrap-servers
- kafka 서버와 연결할 호스트와 포트 정보이다.만약 producer와 consumer가 다른 서버에 있다면 spring.kafka.consumer(또는 producer).bootstrap-servers으로 설정하면된다.)
- 이 때, 글로벌 설정 정보가 있어도(spring.kafka.bootstrap-servers) consumer 전용으로 오버라이딩한다.
-
auto-offset-reset
- Kafka 서버에 초기 offset이 없거나, 서버에 현재 offset이 더 이상 없는 경우 수행할 작업을 작성한다.
- earliest : 가장 오래된 메세지로 offset reset
- latest : 가장 최근에 생산된 메세지로 offset reset
- none : offset 정보가 없으면 Exception을 발생
-
key-deserializer/value-desrializer
- Kafka에서 consumer가 데이터를 받아올 때 key/value를 역직렬화한다.
- 우리가 주고 받는 데이터의 형태는 String이므로 StringDeserializer를 사용했다.
작성 코드
KafkaConfiguration
@Configuration
public class KafkaConfiguration {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> producerConfig(){
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<String, String> producerFactory(){
return new DefaultKafkaProducerFactory<>(producerConfig());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate(){
return new KafkaTemplate<String, String>(producerFactory());
}
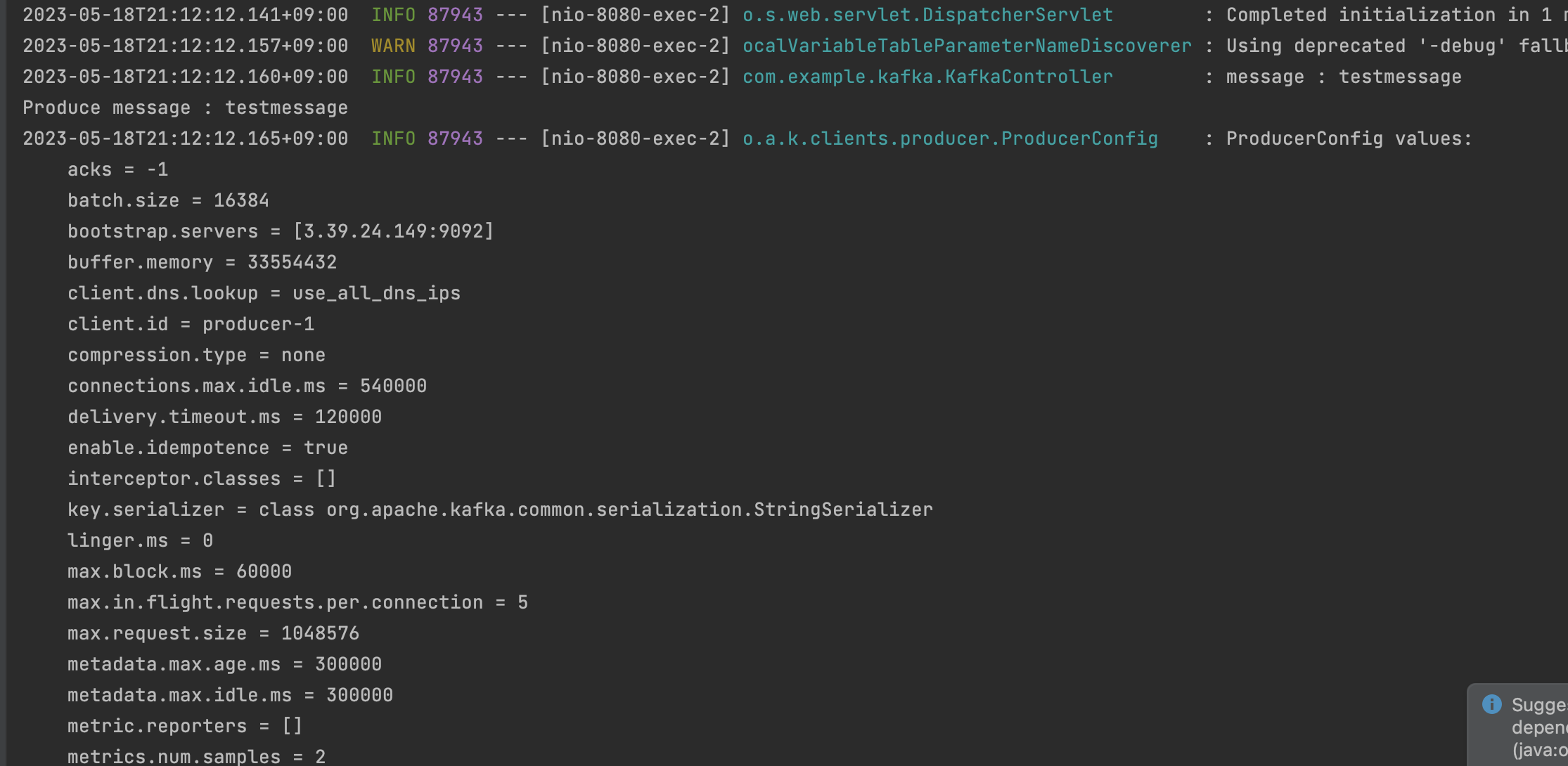
}bootstrapServers 에 yml 에 있는 kafka 브로커의 EC2주소:포트 가 적혀있다.
KafkaConsumer
@Service
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = "exam-topic", groupId = "foo")
public void consume(String message) throws IOException {
log.info("Consumed message : {}", message);
}
}KafkaProducer
@Service
@Transactional
public class KafkaProducer {
@Value(value = "${message.topic.name}")
private String topicName;
private final KafkaTemplate<String, String> kafkaTemplate;
@Autowired
public KafkaProducer(KafkaTemplate kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String message) {
System.out.println(String.format("Produce message : %s", message));
this.kafkaTemplate.send(topicName, message);
}
}KafkaController
@RestController
@RequestMapping(value = "/kafka")
@Slf4j
public class KafkaController {
private final KafkaProducer producer;
@Autowired
KafkaController(KafkaProducer producer){
this.producer = producer;
}
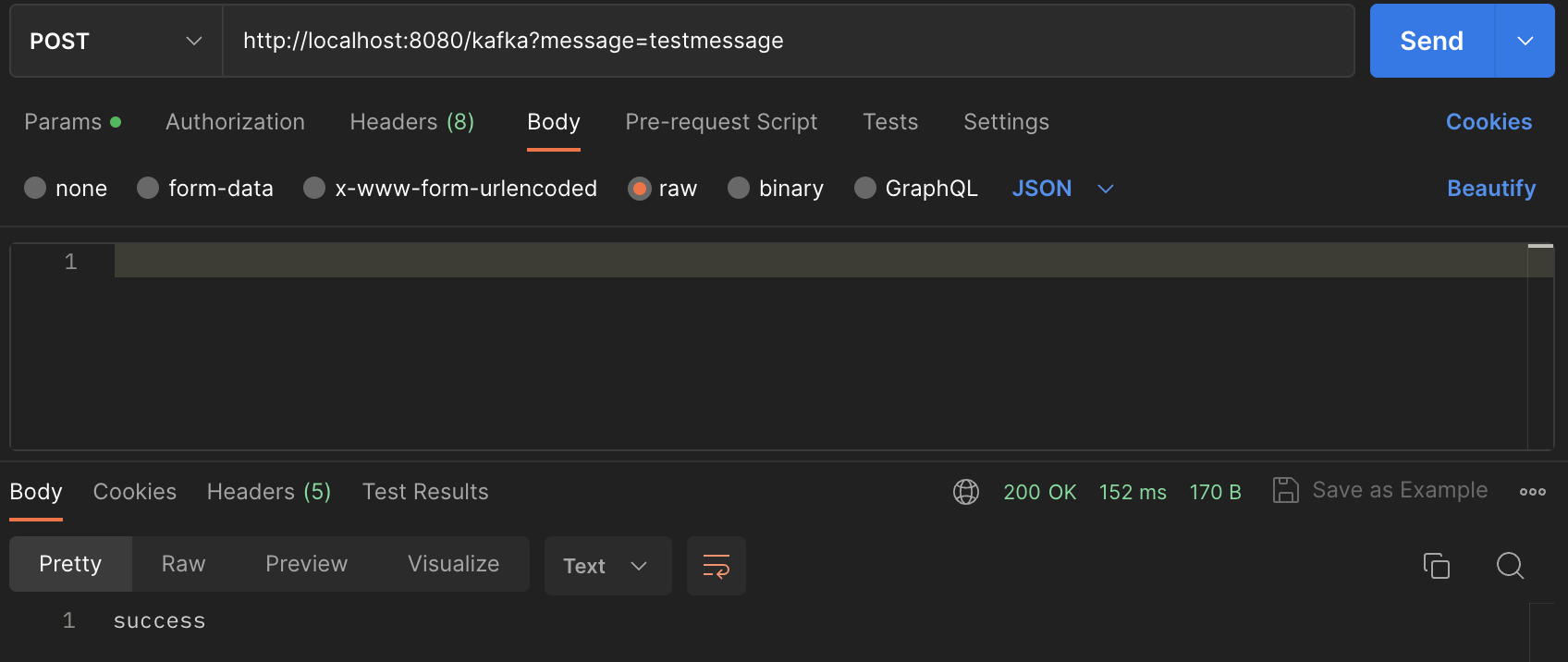
@PostMapping
@ResponseBody
public String sendMessage(@RequestParam String message) {
log.info("message : {}", message);
this.producer.sendMessage(message);
return "success";
}
}
수정
ec2:포트가 아닌 Localhost:9092 로 수정
docker volume create zookeeper_data
docker volume create kafka_datajvm heap 설정을 해두었다.
docker-compose.yml
version: '2'
services:
zookeeper:
image: 'bitnami/zookeeper:latest'
container_name: zookeeper
ports:
- '2181:2181'
volumes:
- 'zookeeper_data:/bitnami'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
- JVMFLAGS=-Xmx512m -Xms512m
kafka:
image: 'bitnami/kafka:latest'
container_name: kafka
ports:
- '9092:9092'
volumes:
- 'kafka_data:/bitnami'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://서버주소:9092
- KAFKA_HEAP_OPTS=-Xmx512m -Xms512m
depends_on:
- zookeeper
volumes:
zookeeper_data:
external: true
kafka_data:
external: true참조
