이 글은 이도길 교수님의 텍스트 마이닝 강의를 듣고 정리한 내용입니다.
원시의 Text Data로부터 의미 있는 결론을 도출해내기 위해,
Text mining에서 가장 먼저 수행되는 방법이 바로 Text Preprcessing, 텍스트 전처리이다.
본 글에서는 비정형인 Text Data를 어떻게 전처리 하고 있는지, 어떤 기법들이 있는지 알아보고자 한다.
Text Preprocessing
Text Preprocessing(텍스트 전처리) 과정은 아래와 같이 3단계로 나누어서 진행되는데,
본 글에서는 다른 분야에서도 널리 활용되는 General purpose NLP 위주로 설명하고자 한다.
- ① Preparatory processing
: 원시 형태의 Text Data를 이후 수행할 전처리 작업에 알맞게 변환하는 작업 - ② General purpose NLP tasks
: 자연어 처리에 범용적으로 사용되는 전처리 작업 (Tokenization, POS tagging 등) - ③ Problem-depedent tasks
: 풀고자 하는 목적(정보 검색 / 분류 등)에 적합한 전처리 작업
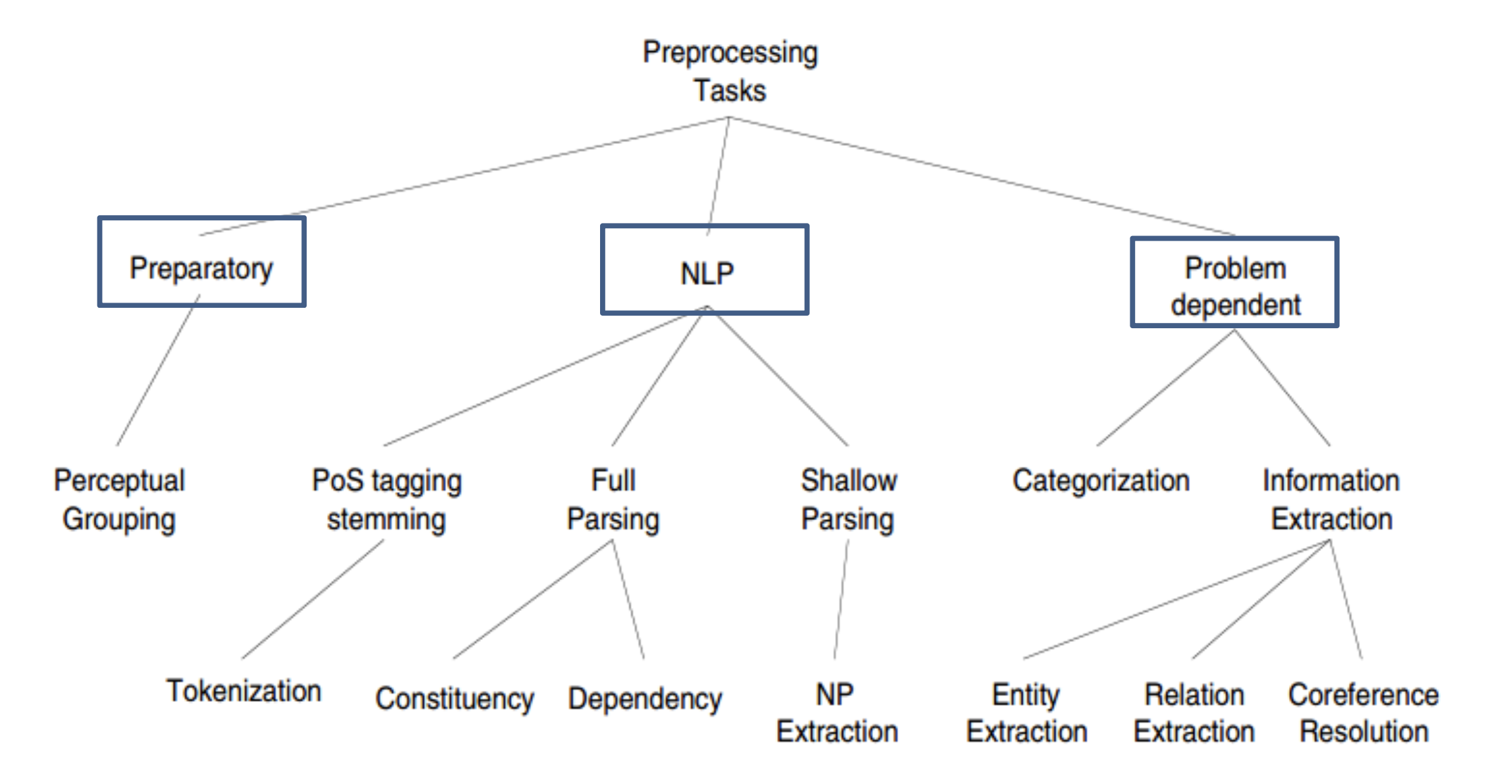
General Purpose NLP tasks 에는,
주어진 텍스트를 단어 단위로 구분하는 ① Tokenization(토큰화), 또는 문장 단위로 구분하는 ② Sentence Segmentation(문장 분할)이 있으며, 이렇게 구분된 여러 형태의 텍스트를 ③ Nomalization(정규화) 하는 작업(ex. U.S.A → USA)도 포함한다. 또한 정규화 된 텍스트를 바탕으로 명사/동사 등 어떠한 품사로 쓰여져 있는지 확인하는 ④ POS-Tagging 작업도 포함되어 있다.
General Purpose NLP tasks(범용 전처리)에는 이 외에도 다양한 종류가 있지만,
본 글에서는 앞서 언급한 작업들에 대해 소개하고자 한다.
Tokenization
먼저 주어진 Text Data, 이를 자연어 처리 분야에서는 말뭉치를 의미하는 corpus라고 하는데,
Tokenization(토큰화)에서는 주어진 corpus를 token 이라는 단위로 분할하는 작업을 의미한다.
token의 기준은 상황에 따라 다를 수 있지만, 보통 의미를 가지는 단위로 설정하며
흔히 단어 단위로 token을 설정하는 Word tokenization을 많이 사용한다.
1️⃣ Word tokenization
Word tokenization은 공백으로 단어를 구분하는 segemented languages에서는 비교적 간단하다.
영어가 여기에 해당되는데, 여기에서는 단순히 공백(white-space)를 기준으로 token을 구해볼 수 있다.
※ Word Type and Token
Word Type은 중복을 제외한 고유 단어 개수, Word Token은 중복을 포함한 개수를 말한다.
2️⃣ Word tokenization 문제점
① Punctuation(문장 부호) Issues
그러나... 그냥 공백만을 가지고 token을 구하면 비교적 부정확한 결과가 나타날 수 있는데,
예를 들어 아래와 같은 문장에서 단순히 공백만을 기준으로 token을 구한다고 가정해보자.
“I said, ‘what’re you? Crazy?’ “ said Sadowsky. “I can’t afford to do that.’’그럼 우리는 cents., said,, positive."와 같이 문장부호까지 포함한 token을 얻게 될 것이다.
그렇다고 이러한 문장 부호를 token을 구분하는 기준에 포함한다면?
아래와 같은 형태의 단어를 token으로 만들 수 없다는 문제가 생길 수 있다.
- 단어 내 문장부호가 있는 경우 (Word-internal punctuation) :
Ph.D.01/02/06 - 접어 축약 (Clitic contractions) :
What'reI'm - 여러 토큰으로 구성되는 단어 (Multi-token words) :
New YorkRock'n roll
※ 복합명사 사전을 통해 위의 단어를 하나의 token으로 간주해야함.
② Language(언어) Issues
또한.. 공백으로 단어를 구분하는 segemented languages가 아닌 공백으로 구분하지 않는 non-segemented languages에서는 단순히 공백을 이용해서 token을 구할 수 없다.
Non-segemented languages 예시
중국어 : 莎拉波娃现在居住在美国东南部的佛罗里达
일본어 : フォーチュン500社は情報不足のため時間あた$500K(約6,000万円)
독어 : Lebensversicherungsgesellschaftsangestellter이런 경우에는 언어의 특성에 따라 다른 방식의 토큰화를 수행한다.
중국어의 경우 1개의 문자(=hanzi)마다 의미를 갖기 때문에 주로 문자 단위의 토큰화를 수행하고,
일본어와 같이 히라가나+가타카나+칸지와 같이 여러 언어가 혼합된 경우 머신러닝을 활용하기도 한다.
3️⃣ Subword tokenization
앞서 공백 또는 1개의 문자를 이용한 토큰화 방식 외에 머신러닝을 활용하는 방식도 있다고 언급하였는데,
머신러닝, 다시 말해 데이터를 기반으로 토큰화를 수행하는 것이 Subword tokenization이다.
이는 단어 뿐만 아니라 단어의 일부분도 하나의 token으로 간주하는 방식이다.
Subword tokenization 알고리즘 종류
여기에 주로 사용되는 알고리즘으로는 아래의 3가지가 있으며, 본 글에서는 BPE에 대해서만 다루고자 한다.
- Byte-Pair Encoding (BPE) : GPT 계열에 주로 활용
- WordPiece : BERT 계열에 주로 활용
- Unigram language modeling tokenization
위의 알고리즘을 포함하여 데이터를 활용한 토큰화 방식은 아래와 같이 2개 기능으로 구성된다.
- Token Learner : 학습을 위한 corpus를 입력 받아 여러 토큰으로 구성된 사전을 생성한다.
- Token Segmenter : 주어진 text 문장을 앞서 만들어진 사전을 기반으로 토큰화를 수행한다.
4️⃣ Byte-Pair Encoding
Byte-Pair Encoding(이하 BPE)가 실제로 어떤식으로 동작하는지 알아보자.
위에서 언급한바와 같이, 2개 기능(Learner / Segementer)으로 나누어 살펴볼 것이다.
① Token Learner
먼저 Learner는 아래 알고리즘에 따라 수행되는데, 하나하나 살펴보자면 다음과 같다.
- 모든 개별 문자를 토큰으로 가지는 사전을 초기화한다.
V = {A, B, C, ... x, y, z} - 아래의 과정을 k번(Hyperparameter) 반복한다.
a. train corpus set에서 가장 자주 인접해있는 2개의 토큰(A, B)을 찾는다.
b. 2개의 토큰을 병합하여 새로운 토큰(AB)을 만들어 사전에 추가한다.
c. train corpus set에서 기존 2개의 토큰(A, B)을 찾아 새로운 토큰(AB)으로 치환한다.

② Token Segmenter
Learner에 비해 Segmenter의 동작은 간단하다.
어떤 문장이 주어지면 앞서 만든 사전에 토큰이 추가됐었던 순서대로, 토큰화를 수행한다.
예를 들어 사전에 토큰이 추가 된 순서가 {a, ap, app, ...} 이라면,
주어진 문장에서도 똑같이 a,p를 병합하고, 그 다음 ap,p를 병합하여 토큰을 만드는 방식이다.
이러한 원리를 통해 토큰을 생성하는 BPE에서는,
기존의 단어 뿐만 아니라 사용 빈도가 높은 Subword 또한 토큰으로 생성된다. (ex. -est, -er)
이전에 언급했었던 Subword tokenization 알고리즘 중 나머지 2개에 대해 설명을 덧붙이자면,
WordPiece는 BPE의 변형 알고리즘으로, 토큰 쌍을 병합할때 빈도가 아니라 corpus의 우도(Likelihood)를 가장 높이는 토큰 쌍을 병합하는 방식이다.
Unigram language modeling tokenization은 각각의 Subword들에 대한 손실(제거 되었을때 corpus의 우도가 감소하는 정도)를 측정하고, 최하위 10~20% 토큰을 제거하는 과정을 특정 토큰 집합의 크기가 될때까지 반복하는 방법이다.
Tokenization 에 대한 설명이 너무 길어져서,
첫 문단에서 언급했었던 다른 전처리 기법들에 대해선 다음 글에 이어서 설명하겠습니다.
(Normalization, Sentence Segmentation, POS-Tagging)
