
주말은 왤케
시간이 빨리가는겨
그래도 T1 롤드컵 3-peat 했다.
우승 기운 받기 위해서
나도 T1 유니폼 바람막이 입고 공부한다.
1. 오늘 학습 키워드
오늘은
데이터 전처리 ch4-1~3듣기
백준, 프로그래머스 3문제씩 풀기
코드카타 10번까지 풀기
이렇게 해보았다.
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
🏃먼저. SQL을 보자.
코드 카타 했던 문제들을 가지고 왔다.
문제가 많으니 스크롤 압박 주의.
(전에 TIL에 적어두었던 문제도 있을 예정)
1. 이름이 있는 동물의 아이디
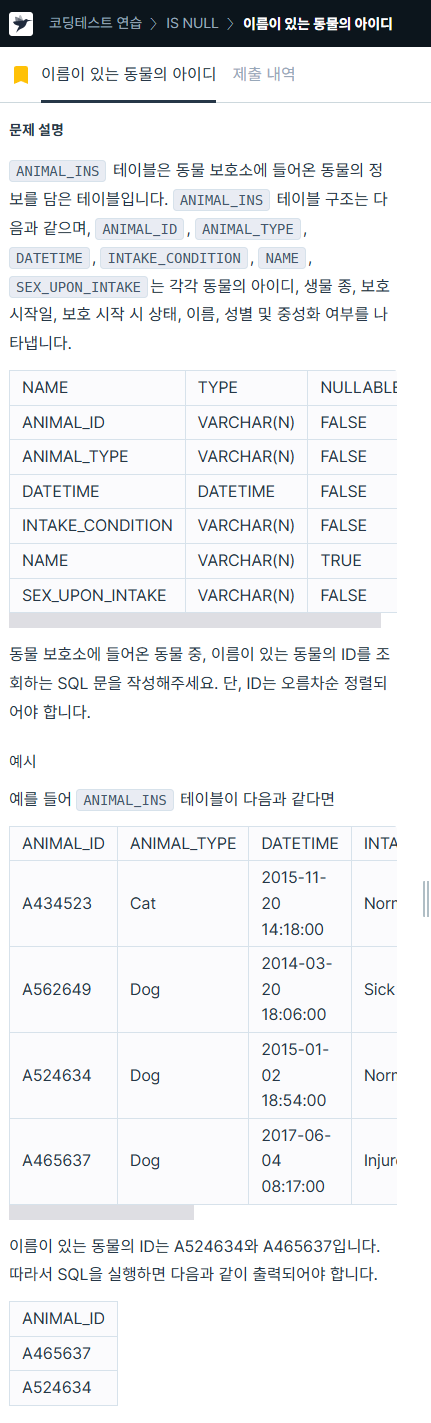
https://school.programmers.co.kr/learn/courses/30/lessons/59407
SELECT animal_id
FROM animal_ins
WHERE name IS NOT NULL
ORDER BY animal_id ASC;2. 역순 정렬하기
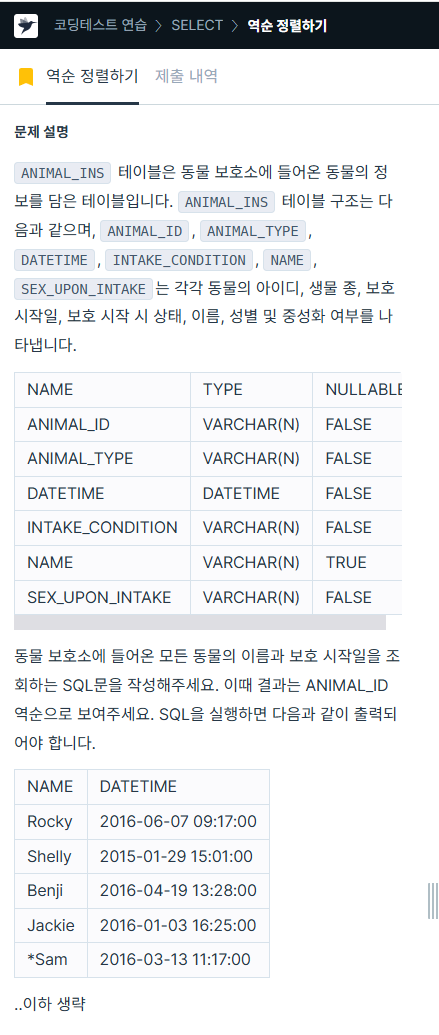
https://school.programmers.co.kr/learn/courses/30/lessons/59035
SELECT name,
datetime
FROM animal_ins
ORDER BY animal_id DESC;3. 중복 제거하기
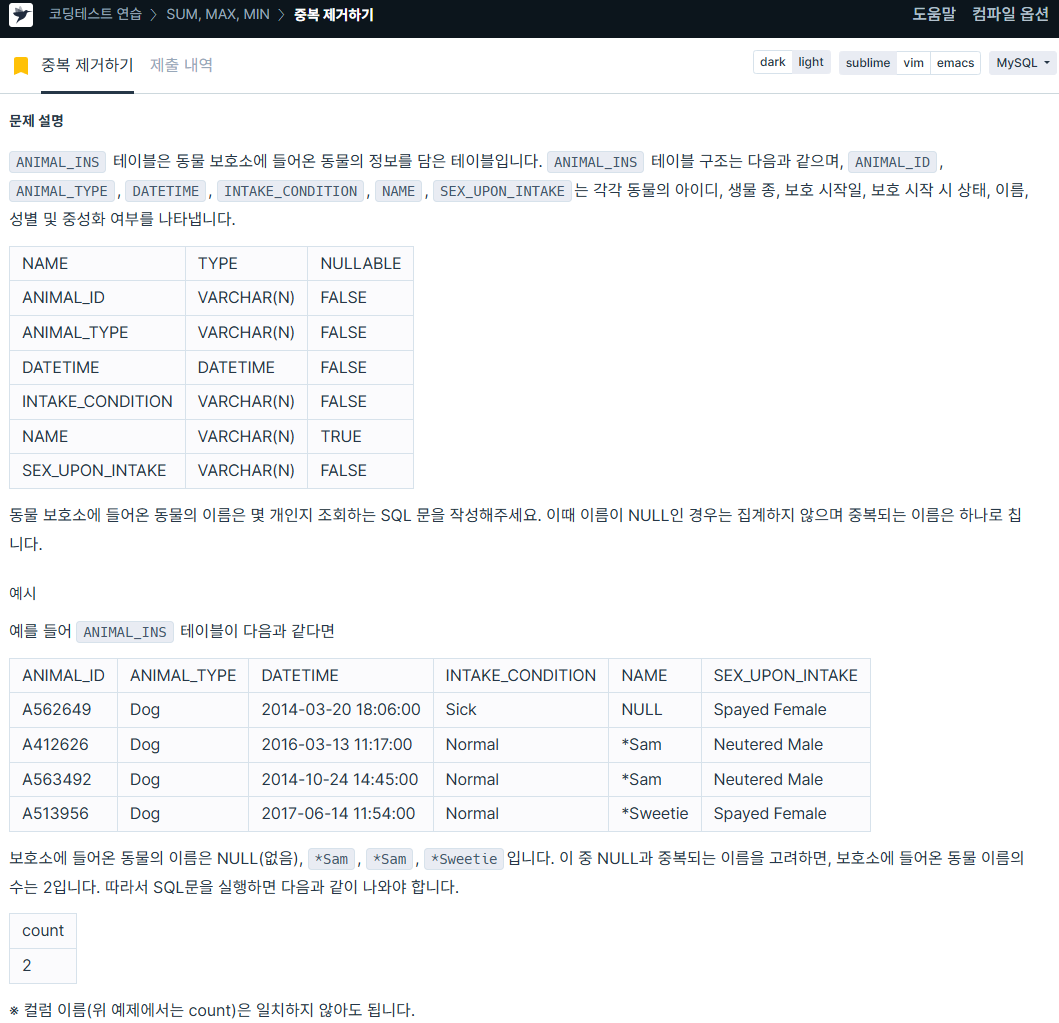
https://school.programmers.co.kr/learn/courses/30/lessons/59408
SELECT COUNT(DISTINCT name) AS count
FROM animal_ins4. 동물의 아이디와 이름
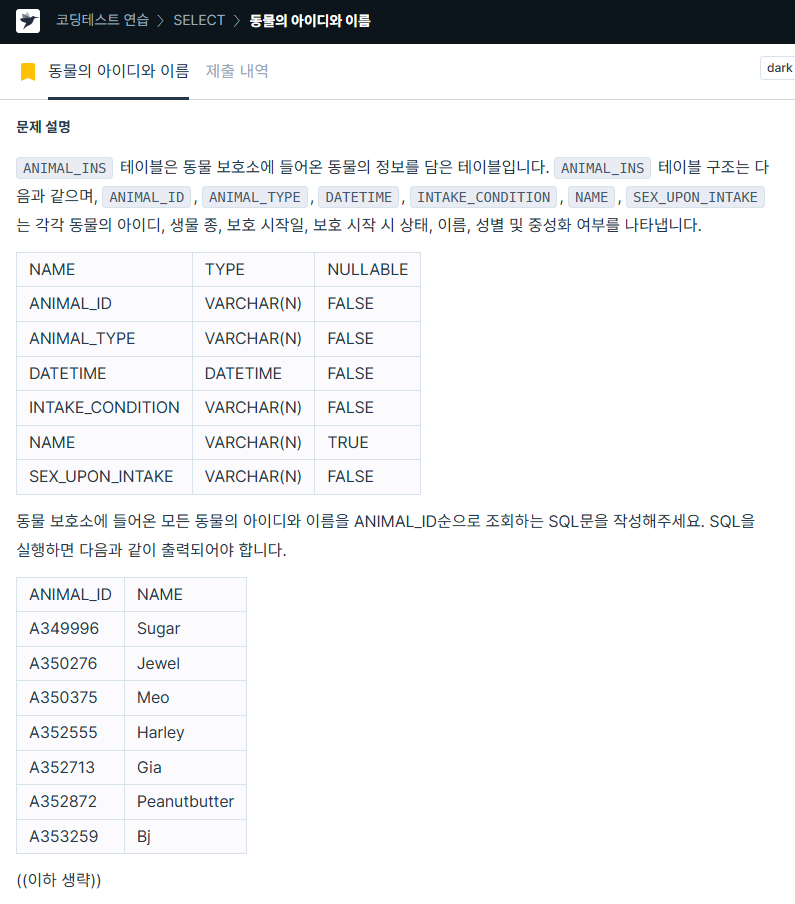
https://school.programmers.co.kr/learn/courses/30/lessons/59403
SELECT animal_id, name
FROM animal_ins
ORDER BY animal_id ASC;5. 동물 수 구하기
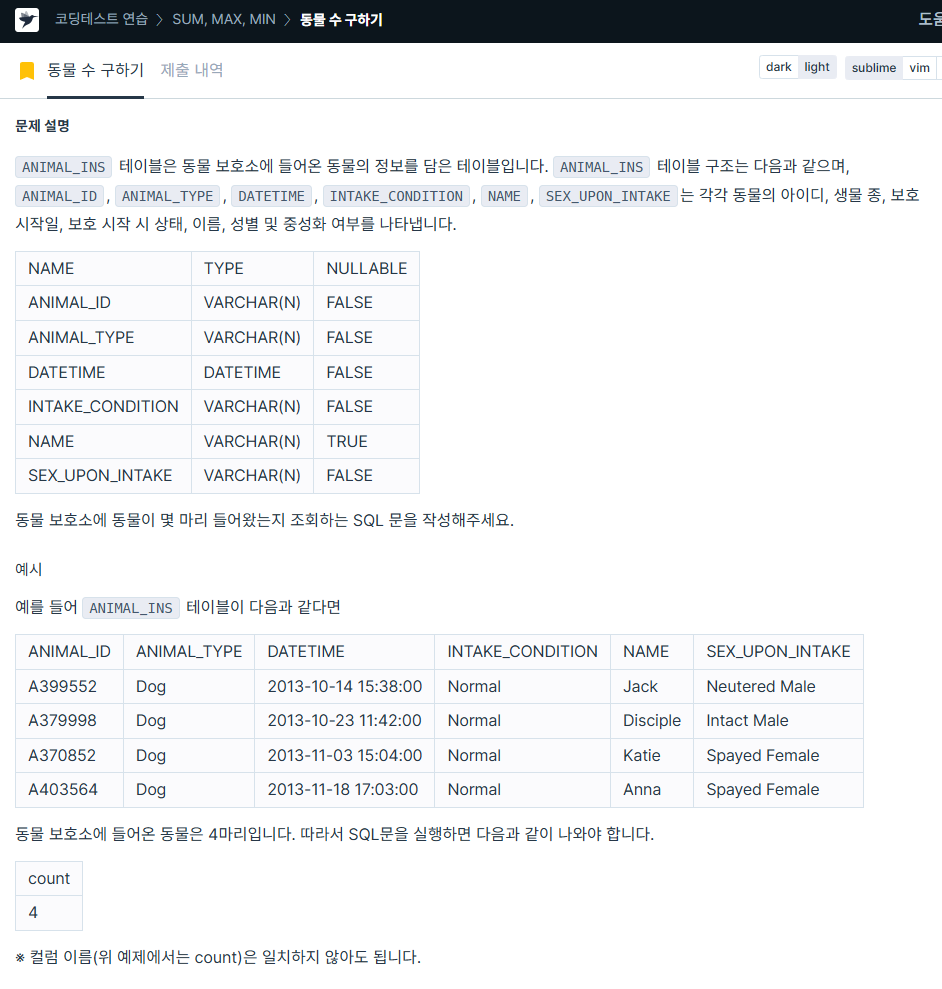
https://school.programmers.co.kr/learn/courses/30/lessons/59406
SELECT COUNT(animal_id) AS count
FROM animal_ins6. 동명 동물 수 찾기
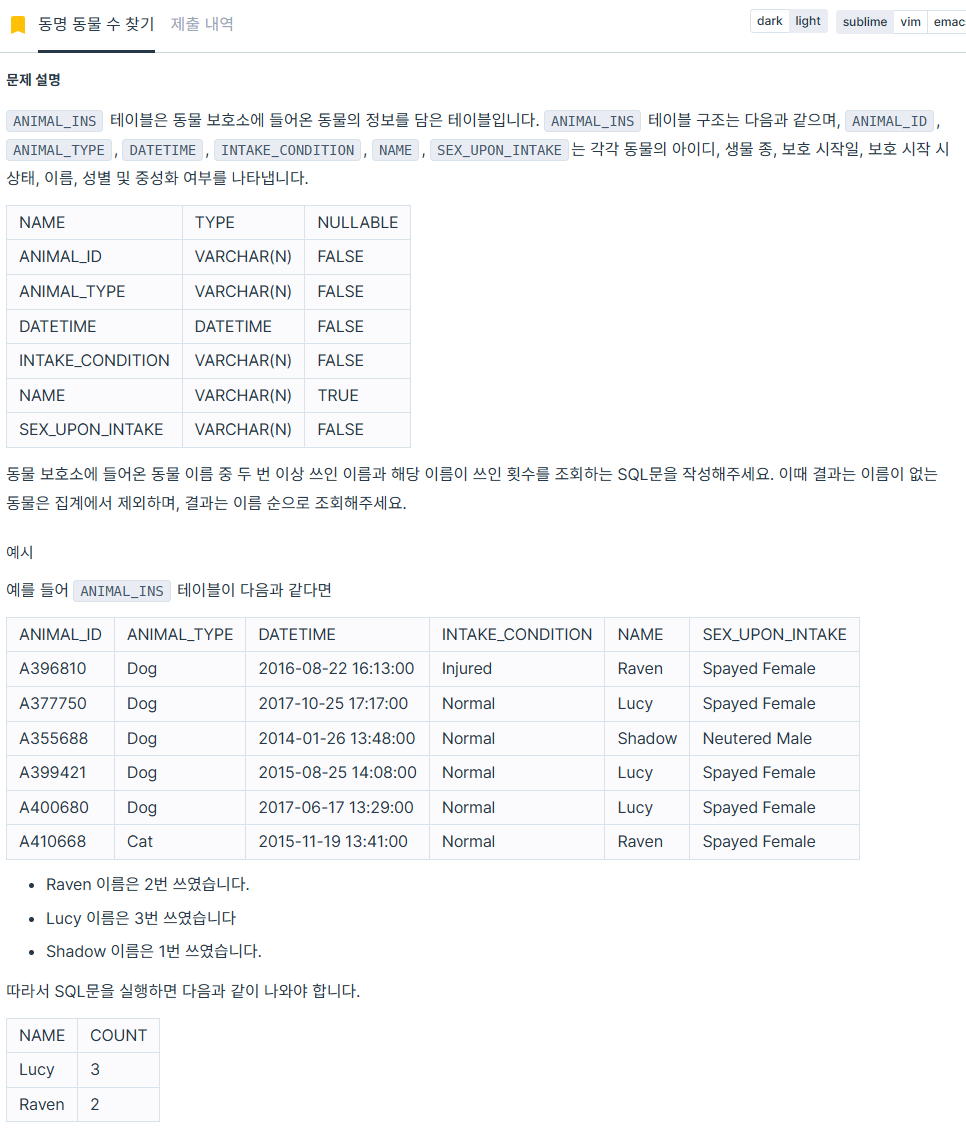
https://school.programmers.co.kr/learn/courses/30/lessons/59041
SELECT name as NAME, COUNT(name) AS COUNT
FROM animal_ins
GROUP BY name
HAVING COUNT(name) > 1
ORDER BY name;잊지 마시길, 중복된 이름이 있는지 확인할거면,
having절을 사용해서 count(name)이 1을 초과하는지 확인하기
7. 아픈 동물 찾기
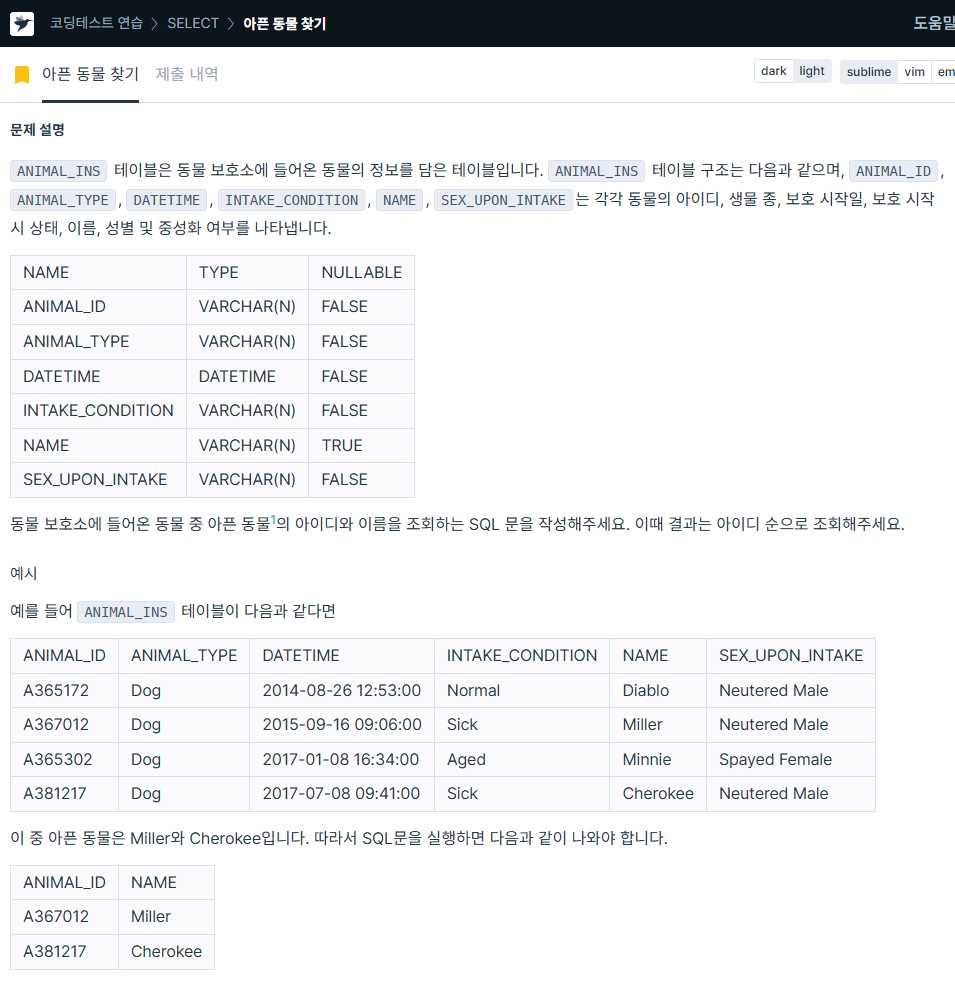
https://school.programmers.co.kr/learn/courses/30/lessons/59041
SELECT animal_id,
name
FROM animal_ins
WHERE intake_condition = 'Sick'
ORDER BY animal_id8. 상위 n개 레코드
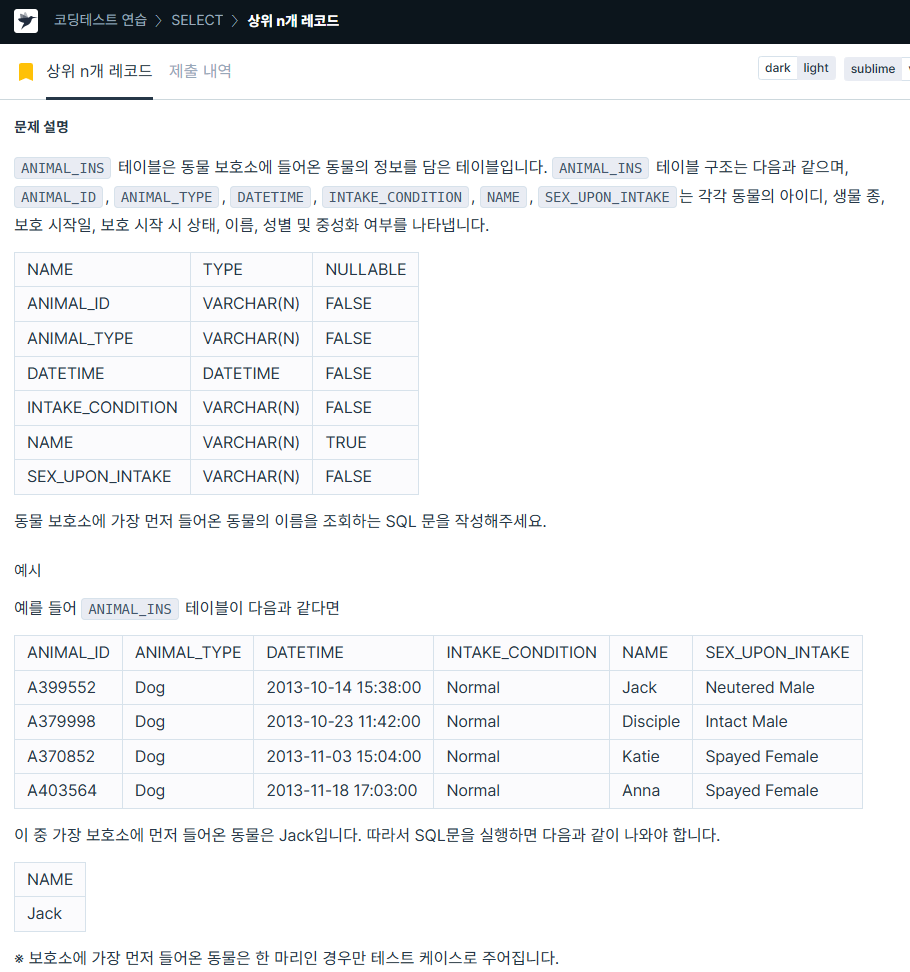
https://school.programmers.co.kr/learn/courses/30/lessons/59405
SELECT name
FROM animal_ins
ORDER BY datetime ASC LIMIT 1;9. 최솟값 구하기
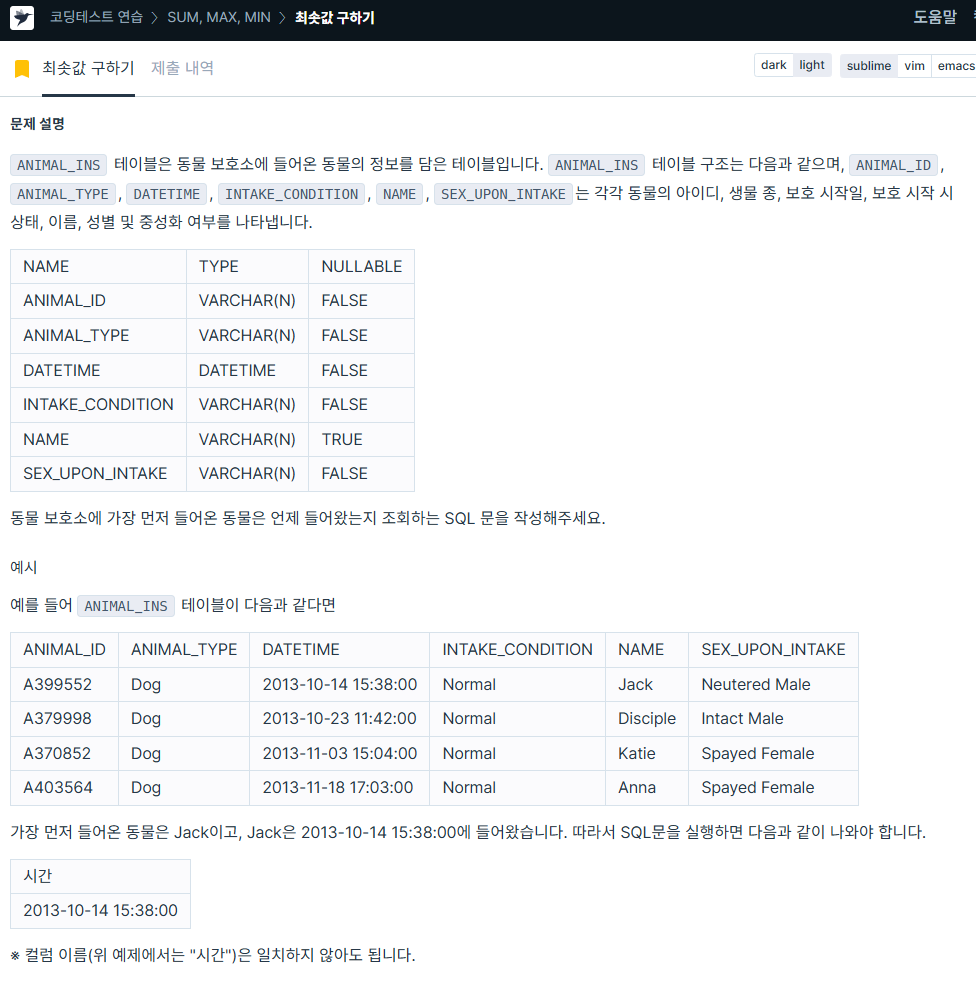
https://school.programmers.co.kr/learn/courses/30/lessons/59038
SELECT datetime AS "시간"
FROM animal_ins
ORDER BY datetime ASC LIMIT 1;10. 어린 동물 찾기
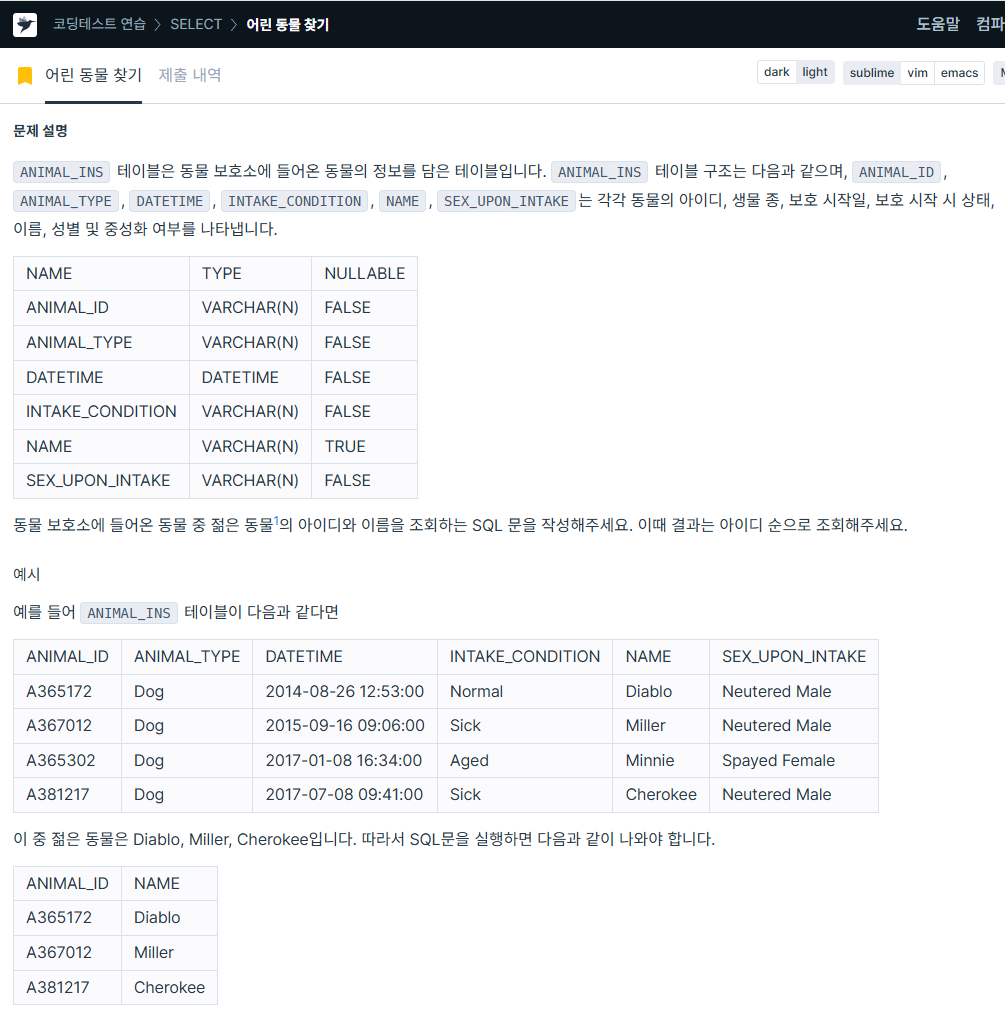
https://school.programmers.co.kr/learn/courses/30/lessons/59037
SELECT animal_id,
name
FROM animal_ins
WHERE intake_condition != "Aged"
ORDER BY animal_id;🏃자자. 이제 파이썬을 보자.
먼저 시각화 ch4-1~3 를 보자.
핵심은 “보여주기”가 아니라 의사결정을 도와 설득하는 그래프를 그리는 것.
그래프는 예쁘게가 목적이 아니라, 어디에 집중해야 돈/리소스를 쓰는지 보이게 하는 도구다.
1) 시각화의 목적: 왜 그리는가?
-
같은 데이터라도 핵심 대비를 만들면 메시지가 선명해진다. (예: 전체 대비 주요 비중, Before/After, Top-N/Long tail)
-
패턴 찾기 → 추이/비교/분포/상관으로 문제 정의에 도움.
-
최종 목표는 한 장으로 결론을 말하게 하는 것. (타이틀/주석으로 결론을 문장으로 써두자)
간단하게 그래프를 시각화 하는 과정부터 코드를 작성해보았다.
import pandas as pd
import matplotlib.pyplot as plt
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [5, 4, 3, 2, 1]
}
df = pd.DataFrame(data)
# 선 그래프 그리기
df.plot(x='A', y='B')
plt.show()
그래프를 보게 되면 x, y축에는 아직 축 제목을 넣지 않은 것을 볼 수 있다.
그래서 스타일을 설정하게 되는데,
plot() method를 호출 할 때 다양한 스타일 옵션을 사용하여 그래프의 스타일을 설정할 수 있다.
color, linestyle, marker 등의 parameter를 사용하여 선의 색상, 스타일, 마커를 변경 할 수 있다.
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o')
plt.show()
보게 되면, 이전 이미지와 다르게 대시선으로 되어있고, 초록색으로 선 색상을 바꾸었으며,
marker를 이용해 원 형태의 마커를 그래프에 남겨보았다.
- Color(색상):
- 색상은 문자열로 지정할 수 있으며, 'blue', 'green', 'red', 'cyan', 'magenta', 'yellow', 'black', 'white'와 같은 기본 색상 이름 또는 RGB 값을 직접 지정할 수 있다.
- Linestyle(선 스타일):
- 선의 스타일은 '-'(실선), '--'(대시선), ':'(점선), '-.'(점-대시선) 등으로 지정할 수 있다.
- Marker(마커):
- 마커는 데이터 포인트를 나타내는 기호로, 'o'(원), '^'(삼각형), 's'(사각형), '+'(플러스), 'x'(엑스) 등 다양한 기호로 지정할 수 있다.
# 범례 추가하기
#1 label
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series')
#2 legend
ax.legend(['Data Series'])
plt.show()
이 코드를 보게 되면 그래프에는 범례를 추가할 수 있는데,
이 때 legned() method를 사용하여 그래프의 범례를 추가할 수 있다.
# 축, 제목 입력하기
# 1 label
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series')
# 2 legend
ax.legend(['Data Series'])
# 3 축, 제목
ax.set_xlabel('X-axis Label')
ax.set_ylabel('Y-axis Label')
ax.set_title('Title of the Plot')
plt.show()
그리고 set_xlabel, set_ylabel, set_title을 이용하여
x, y축의 레이블 및 그래프 제목을 추가할 수 있다.
# 축, 제목 입력하기
# 1 label
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series')
# 2 legend
ax.legend(['Data Series'])
# 3 축, 제목
ax.set_xlabel('X-axis Label')
ax.set_ylabel('Y-axis Label')
ax.set_title('Title of the Plot')
# 4 텍스트 추가하기
ax.text(3, 3, 'Some Text', fontsize=12)
plt.show()
그리고 text()를 이용하여 특정 위치에 텍스트를 추가할 수 있다.
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 그래프 그리기
plt.plot(x, y, color='green', linestyle='--', marker='o', label='Data Series')
# 추가 설정
plt.xlabel('X-axis Label')
plt.ylabel('Y-axis Label')
plt.title('Title of the Plot')
plt.legend()
plt.text(3, 8, 'Some Text', fontsize=12) # 특정 좌표에 텍스트 추가
# 그래프 출력
plt.show()
마지막으로 이를 한번에 넣어 코드를 작성면 위와같이 그래프가 생성이 된다.
# 한번에 설정하기
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 그래프 그리기
plt.plot(x, y, color='green', linestyle='--', marker='o', label='Data Series')
# 추가 설정
plt.xlabel('X-axis Label')
plt.ylabel('Y-axis Label')
plt.title('Title of the Plot')
plt.legend()
plt.text(3, 8, 'Some Text', fontsize=12) # 특정 좌표에 텍스트 추가
plt.figure(figsize=(8, 6)) # 가로 8인치, 세로 6인치
# 그래프 출력
plt.show()여담이지만, plt.figure()를 이용하여 figure 객체를 생성하고,
이후에 figsize 매개변수를 이용하여 원하는 크기로 설정할 수 있다.
라이브 세션에서는 지난주 복습한 내용들을 vs code에서 살짝이나마 끄적여보았다.
# 2025.11.10 python 끄적이기 (이론 수업)
# 환경설정
# python 파일 하나 (.py)
# 가상환경
## python venv(가상환경 이름)
## 활성화: venv\Scripts\activate
## 비활성화: deactivate
# 자료형
# 숫자형: 정수(int), 실수(float)
# 문자형: 문자열(string)
# 논리형: 불리언(boolean)
# None
# 변수
# 값을 저장하는(가리키는) 상자 -> 값을 재사용, 어떤 곳에서 가져다 쓰기 위해서
a = 10
# 출력하는 방법
print()
# 입력하는 방법
input() # input으로 받은 값은 문자열, 숫자로 쓰고 싶으면 형 변환(int(), float())
# 자료 구조
# 리스트
# [a, b, c]
# 성격이 비슷한 여러 값들을 한 번에 저장하기 위해
# 순서가 있고 수정이 가능
# 튜플
# (123.65, 1231.53)
# 변하면 안 되는 값을 보호하기 위해
# 순서가 있고 수정이 불가능
# 딕셔너리
# { Key: Value }
# 각 값에 대한 정체성 부여(설명)하기 위해
# 순서 없고 수정 가능
# 셋
# set()
# 중복을 허용하지 않는다
# 기본 연산자
# +, -, *, /
# //, %, **
# ==, !=
# 연산자 연결
## 조건 연결 -> n % 2 == 0
## 논리 연산자 and, or, not
# and
# 첫 번째 조건(n % 2 == 0) and 두 번째 조건(n % 4 == 0)
# 참 and 참 -> True
# 참 and 거짓 -> False
# 거짓 and 거짓 -> False
# or
# 첫 번째 조건(n % 2 == 0) or 두 번째 조건(n % 4 == 0)
# 참 or 참 -> True
# 참 or 거짓 -> True
# 거짓 or 거짓 -> False
# not
# not 조건(n % 2 == 0)
# 조건문, 반복분
# if
# if 조건문1:
# 실행문1(print)
# elif 조건문2:
# 실행문2(print)
# elif 조건문3:
# 실행문3(print)
# else:
# 실행문4
# "조건문 어떻게 만들 것인가"
# "조건마다 어떻게 분기할 것인가"
# 반복분
# for, while
# for
# for 변수 in 순회할 곳:
# 순회할 곳이 정해져있다. 범위, 횟수 정해져 있음
# for 변수 in range:
# 범위, 횟수를 직접 지정, 위치
# while
# while 조건문:
# 조건이 참일 동안 반복 -> 조건이 거짓이 되는 순간 멈춤
# 횟수 < "조건"
# break
# break를 만난 순간 반복문이 끝난다.
# continue
# 위 조건이 True일 시 값을 반환하지 않고 다시 반보긍로 넘어간다.
# while True:
# if 조건:
# break
# 함수
# def 함수이름(매개변수):
# 자주 쓰는 코드들을 한번만 정의해서 자주 꺼내 쓰기
# 선언부, 호출부 -> 함수이름(인자)
# 함수 실행 결과를 사용하고 싶을 때: return
# 변수 = 함수이름(인자)
# 매개변수
# 가변 매개변수: 갯수를 정해놓지 않고 선언하고 싶을 때
# def 함수이름(*args):
# print(args) -> () 하나의 튜플 형태로 받는다
# 함수이름(1, 2, 3, ....)
# 키워드 가변 매개변수: 유연하게 입력 처리
# def 함수이름(**kwargs):
# print(kwargs) -> {} 키-값 형태로 받는다
# 함수이름(name="", age="")# 2025.11.10 python 끄적이기 (실습시간)
# 실습 1 학점 계산 프로그램
# 입력 : 학생의 점수
# 출력 : A ~ F
# 규칙 : 입력된 학점을 점수에 따라 분류
# def 함수 이름():
# 실행문 -> 반복할 코드 내용
def grade(score):
if score >= 90:
return "A"
elif score >= 80:
return "B"
elif score >= 70:
return "C"
elif score >= 60:
return "D"
else:
return "F"
score = int(input("점수를 입력하세요: "))
print(f"당신의 학점은 {grade(score)}입니다.")
# 실습 2 구구단 출력기
# 입력 : 숫자 (2 ~ 9단)
# 출력 : 구구단표
# 실행 : 구구단 법칙을 반복적으로 출력 -> for 변수 in range 대상
# for: 범위를 직접 만들어주기
# 범위 : 고정 x 증가하면서 변하는 값 = 곱해서 나온 값
def gugudan(n): # 2 ~ 9 까지의 값이 아니면 함수 동작 x -> 예외 처리
for i in range(1, 10):
print(f"{n} x {i} = {n * i}")
num = int(input("단을 입력하세요: "))
gugudan(num)
# 실습 3 리스트 평균 & 최고점 구하기
# 입력 : 여러 학생들의 점수 -> 리스트 입력 받기, *args
# 출력 : 평균, 최고점
# 실행 : 입력받은 점수의 평균, 최고점 -> sum()/len(), max()
def analyze_scores(scores):
avg = sum(scores) / len(scores)
high = max(scores)
return avg, high
data = [80, 95, 100, 70, 85]
avg, high = analyze_scores(data)
print(f"평균: {avg:.1f}, 최고점: {high}")
# 실습 4 숫자 맞히기 게임
# 프로그램 시작 (랜덤한 숫자를 가지고 있음)
# 입력창 생성 -> 5 입력
# 랜덤한 숫자 == 5 ?
# 맞습니다 / 틀렸습니다
# 입력창 생성 -> 7 입력
# 랜덤한 숫자 == 7 ?
# 맞습니다 -> 종료
# 틀렸으면 다시 반복
import random
def guess_game():
answer = random.randint(1, 10) # 1이상 ~ 10이하
while True:
guess_game = int(input("1~10 사이 숫자 입력: "))
if guess_game == answer:
print("정답입니다!")
break
elif guess_game > answer:
print("너무 커요.")
else:
print("너무 작아요.")
guess_game()
# 숙제, guess_game 함수를 continue 쓴 버전으로 제출하기
import random
def guess_game():
answer = random.randint(1, 10) # 1이상 ~ 10이하
while True:
guess_game = int(input("1~10 사이 숫자 입력: "))
if guess_game == answer:
print("정답입니다!")
break
else:
print("다시 하세요.")
continue
guess_game()3. 학습하며 겪었던 문제점 & 에러
🖥️프로그래머스 문제를 풀어보자.
1. 연도별 대장균 크기의 편차 구하기
또또또 대장균친구다.
아주 이친구도 애를 먹었지 푸는데...

https://velog.io/write?id=48c2a366-20f9-425b-a3bd-36396f171d34
# 처음 제출했던 답 (테스트 실행 실패)
SELECT a.year AS YEAR,
(b.max - a.size_of_colony) AS YEAR_DEV,
a.id AS ID
FROM (
SELECT DATE_FORMAT(differentiation_date, "%Y") AS YEAR,
size_of_colony,
id
FROM ecoli_data) as a
JOIN (
SELECT DATE_FORMAT(differentiation_date, "%Y") AS YEAR,
MAX(size_of_colony) AS MAX
FROM ecoli_data
GROUP BY DATE_FORMAT(differentiation_date, "%Y")) AS b
ON a.year = b.year
ORDER BY YEAR ASC, YEAR_DEV;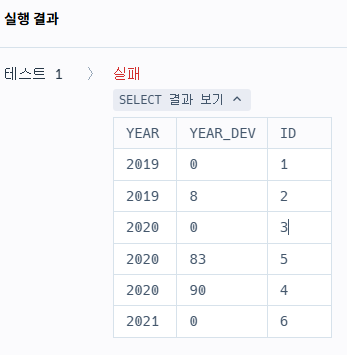
일단 결과는 보았는데, 똑같이 나오긴 했다.
테스트 결과에서 뭐가 틀렸기에 실패라고 한거지...?
다시 로그 정의서를 보았다.
diffrentiation_date의 type은 DATE니까,
문자열로 추출하지 말고, 정수로 추출하라는건가..?
그러면 YEAR 함수를 써서 해볼까? 라는 생각이 들었다.
# year 함수로 다시 풀기
SELECT a.year AS YEAR,
(b.max - a.size_of_colony) AS YEAR_DEV,
a.id AS ID
FROM (
SELECT YEAR(differentiation_date) AS YEAR,
size_of_colony,
id
FROM ecoli_data) as a # 필요한 컬럼들 추출
JOIN (
SELECT YEAR(differentiation_date) AS YEAR,
MAX(size_of_colony) AS MAX
FROM ecoli_data
GROUP BY YEAR(differentiation_date)) AS b # 연도별 가장 큰 대장균 크기 구하기
ON a.year = b.year
ORDER BY YEAR ASC, YEAR_DEV;역시는 역시다.
문제에서 따로 포맷 맞춰달라고 안해도,
기존 형식을 깨트리지 않게 추출해야 한다....
DATE_FORMAT을 쓰게 되면 DATE에서 문자열을 반환하기에,
맞지 않다고 생각이 든다...
그래서 YEAR를 사용해서 정수로 추출하였는데,
맞았네...? 너무 DATE_FORMAT만 하지 말고,
다른 함수도 이용해서 추출해봅시다....

2. 분기별 분화된 대장균의 개체 수 구하기

https://school.programmers.co.kr/learn/courses/30/lessons/299308
# 초기 작성 쿼리 (정답)
SELECT a.QUARTER, COUNT(a.QUARTER) AS ECOLI_COUNT
FROM (
SELECT CASE WHEN SUBSTRING(differentiation_date, 6, 2) BETWEEN '01' and '03' THEN "1Q"
WHEN SUBSTRING(differentiation_date, 6, 2) BETWEEN '04' and '06' THEN "2Q"
WHEN SUBSTRING(differentiation_date, 6, 2) BETWEEN '07' and '09' THEN "3Q"
ELSE "4Q" END AS QUARTER
FROM ecoli_data) AS a
GROUP BY a.QUARTER
ORDER BY a.QUARTER;# 변형 후 쿼리(정답)
SELECT a.QUARTER, COUNT(a.QUARTER) AS ECOLI_COUNT
FROM (
SELECT CASE WHEN MONTH(differentiation_date) BETWEEN '01' and '03' THEN "1Q"
WHEN MONTH(differentiation_date) BETWEEN '04' and '06' THEN "2Q"
WHEN MONTH(differentiation_date) BETWEEN '07' and '09' THEN "3Q"
ELSE "4Q" END AS QUARTER
FROM ecoli_data) AS a
GROUP BY a.QUARTER
ORDER BY a.QUARTER;
이것도 재밌는 문제였다.
처음에 풀었을 때는 substring 이용해서 differentiation_date를
문자열로 취급하여 6~7번째 문자('01')를 잘라온다.
그런 다음 case when, between을 이용해서 문자비교로 어느 구간에 속하는지 구한다.
변형한 쿼리는 substring 대신 month를 이용하여 월을 정수로 추출한다.
그런 다음 정수 범위 비교로 분기를 판정하고,
분기별로 그룹화/count를 한다.
굳이 subquery로 안풀어도 될 것 같은 문제인데,
정리하다 보니 subquery로 풀었다.
나중에는 없이 풀어보자.
🖥️백준 문제도 보자.
1. 별 찍기 - 2
https://www.acmicpc.net/problem/2439
n = int(input())
for i in range(n):
print(" " * (n - (i+1)), end="")
print('*' * (i+1))
이전에 별 찍기 문제와는 다르게,
좌우 반전이 된 상태로 출력해야 한다.
그렇기에,
맨 윗줄을 보게 되면, 5개 중 공백이 4개 별이 1개로 시작하여,
공백 0개 별 5개로 끝나게 된다.
그걸 이용하여 공백이 출력되고, 줄바꿈이 되지 않게 print()에 end를 설정해서
줄바꿈이 되지 않게 한다.
2. A+B -5
https://www.acmicpc.net/problem/10952
while True:
a, b = map(int, input().split())
if a == 0 and b == 0:
break
print(a+b)이건 옜날에 A+B 방식 이용해서 푸는줄 알았는데,
바로 런타임 에러 나가지고...
다른 방식을 생각해 보았다.
일단 while문으로 작성해서 루프를 만들었고,
input().split()으로 한줄에서 두 정수 a, b를 읽는다.
그리고 (a, b)가 (0, 0)이면 break로 종료를 하고,
아니면 a+b를 출력한다.
그렇게 하여 다시 다음 줄을 읽어서 반복한다.
4. 내일 학습 할 것은 무엇인지
내일도 틈틈히 시간날 때 마다 SQLD 공부를 하고,
라이브 세션 놓치지 않게 잘 듣고,
데이터 전처리도 잘 들어놔야겠다.


