
SQLD 시험이 얼마 안남았다.
그래도 할 건 해야한다.
1. 오늘 학습 키워드
오늘은
1. 라이브세션 복습
2. 프로그래머스 문제 풀기
3. 코드카타 30번까지 풀기
4. SQLD 공부
를 해보았다.
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
🏃먼저. SQL을 보자.
코드카타 문제들을 봅시다.
1. 이름이 없는 동물의 아이디
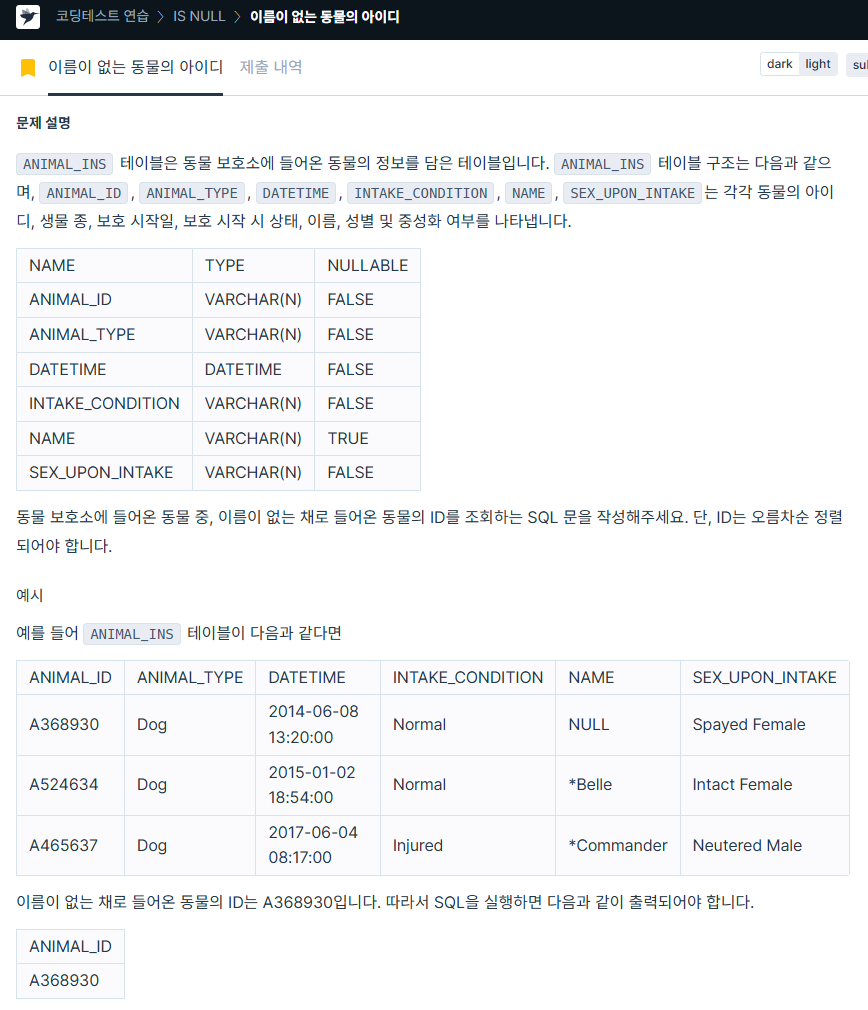
https://school.programmers.co.kr/learn/courses/30/lessons/59039
SELECT animal_id
FROM animal_ins
WHERE name IS NULL
ORDER BY animal_id ASC;2. 조건에 맞는 회원수 구하기
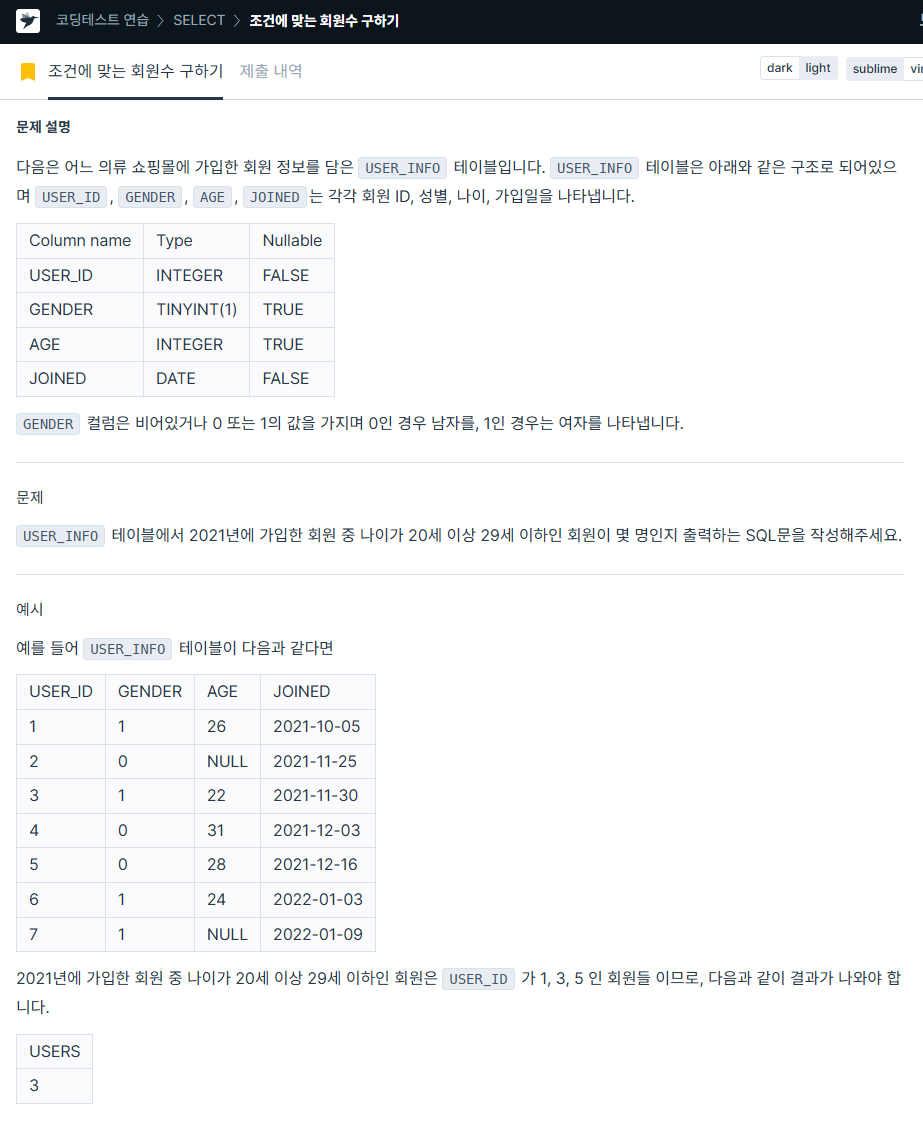
https://school.programmers.co.kr/learn/courses/30/lessons/131535
SELECT COUNT(user_id) AS USERS
FROM user_info
WHERE age BETWEEN 20 and 29
AND DATE_FORMAT(joined, '%Y') like '%2021%';3. 중성화 여부 파악하기
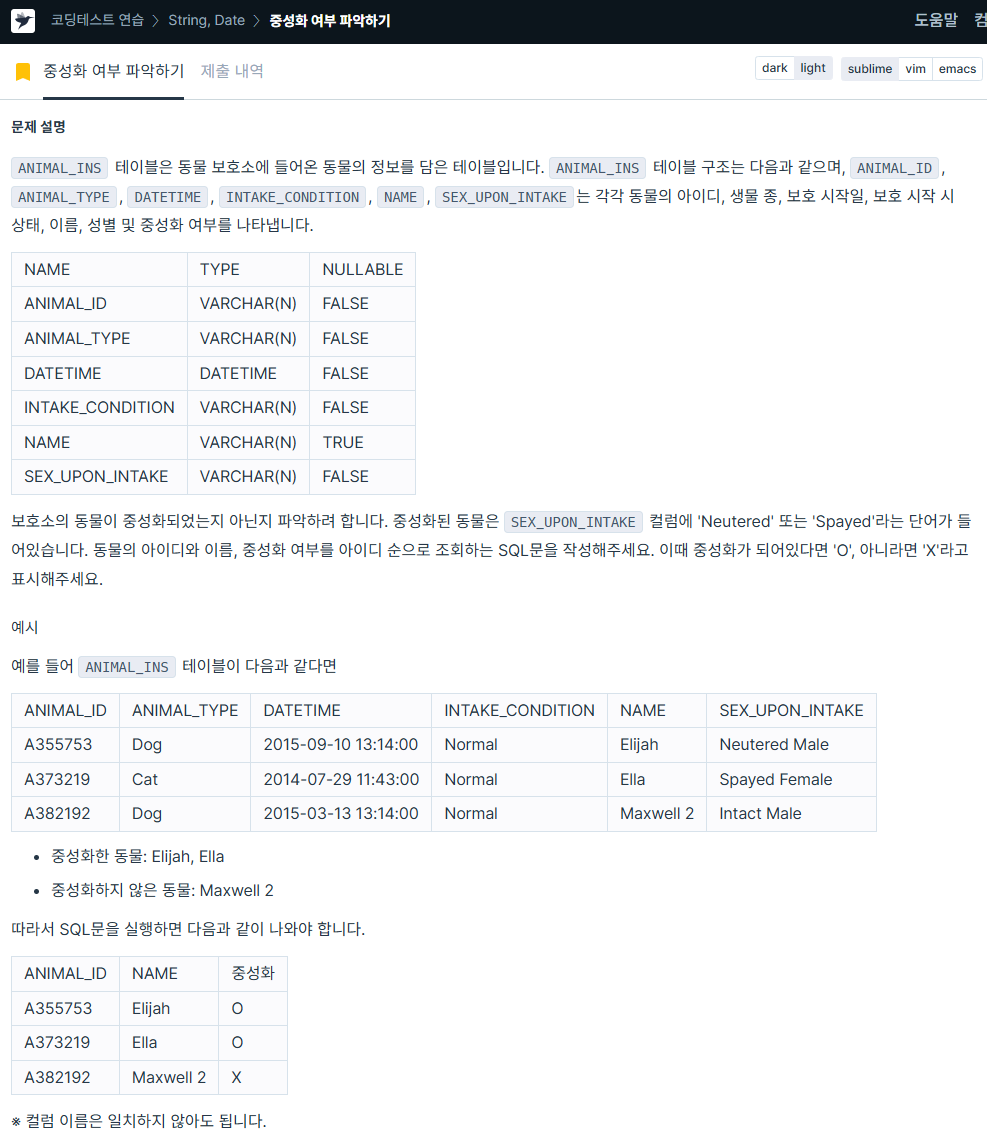
https://school.programmers.co.kr/learn/courses/30/lessons/59409
SELECT animal_id AS ANIMAL_ID,
name AS NAME,
CASE WHEN sex_upon_intake LIKE '%Neutered%' OR sex_upon_intake LIKE '%Spayed%' THEN 'O'
ELSE 'X' END AS '중성화'
FROM animal_ins
ORDER BY animal_id;4. 카테고리 별 상품 개수 구하기

https://school.programmers.co.kr/learn/courses/30/lessons/131529
SELECT SUBSTRING(product_code, 1, 2) AS CATEGORY, # data 살펴보니 제시된 3개말고 더 있었음
COUNT(product_code) AS PRODUCTS
FROM product
GROUP BY CATEGORY
ORDER BY CATEGORY;이 문제, 사람 골아프게 만들어 놨다.
주어진 데이터를 확인 안하면 무조건 틀릴 문제라서...
확인 안하고 case when으로만 하다가 바로 틀려버렸다.
데이터 확인 잘 합시다.
5. 고양이와 개는 몇 마리 있을까
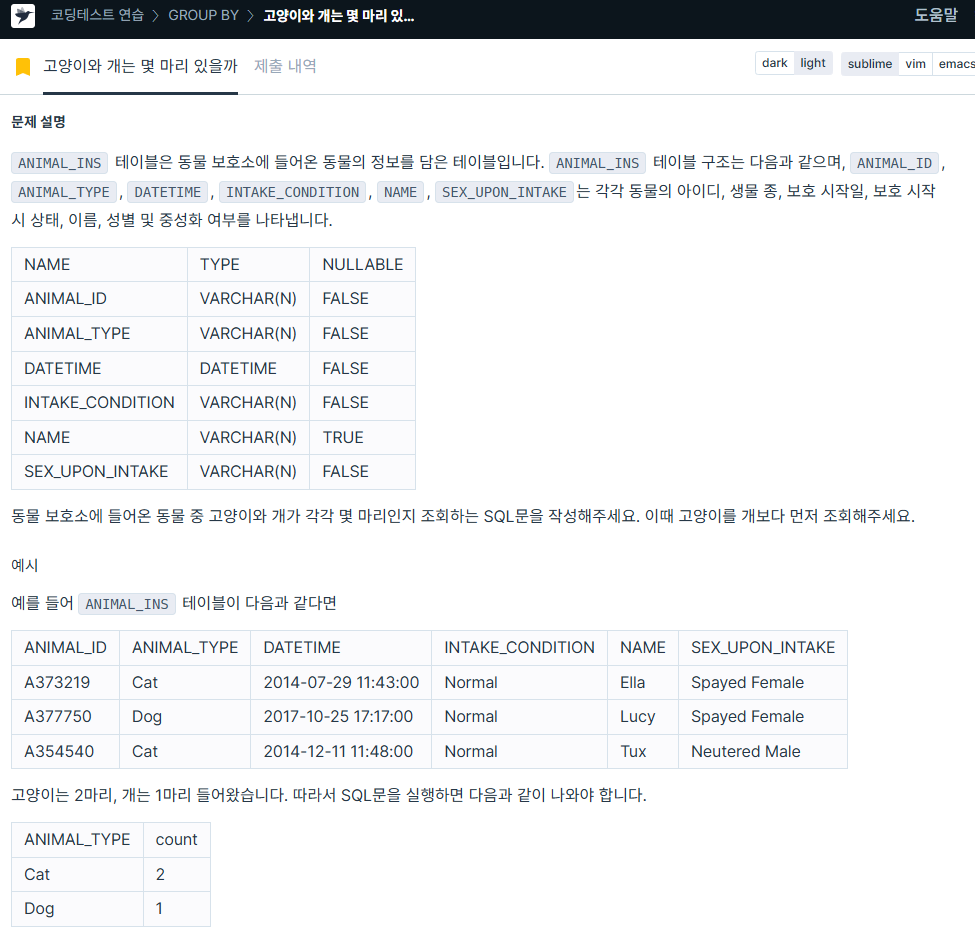
https://school.programmers.co.kr/learn/courses/30/lessons/59040
SELECT animal_type AS ANIMAL_TYPE,
COUNT(*) AS count
FROM animal_ins
GROUP BY ANIMAL_TYPE
ORDER BY ANIMAL_TYPE ASC;6. 입양 시각 구하기(1)
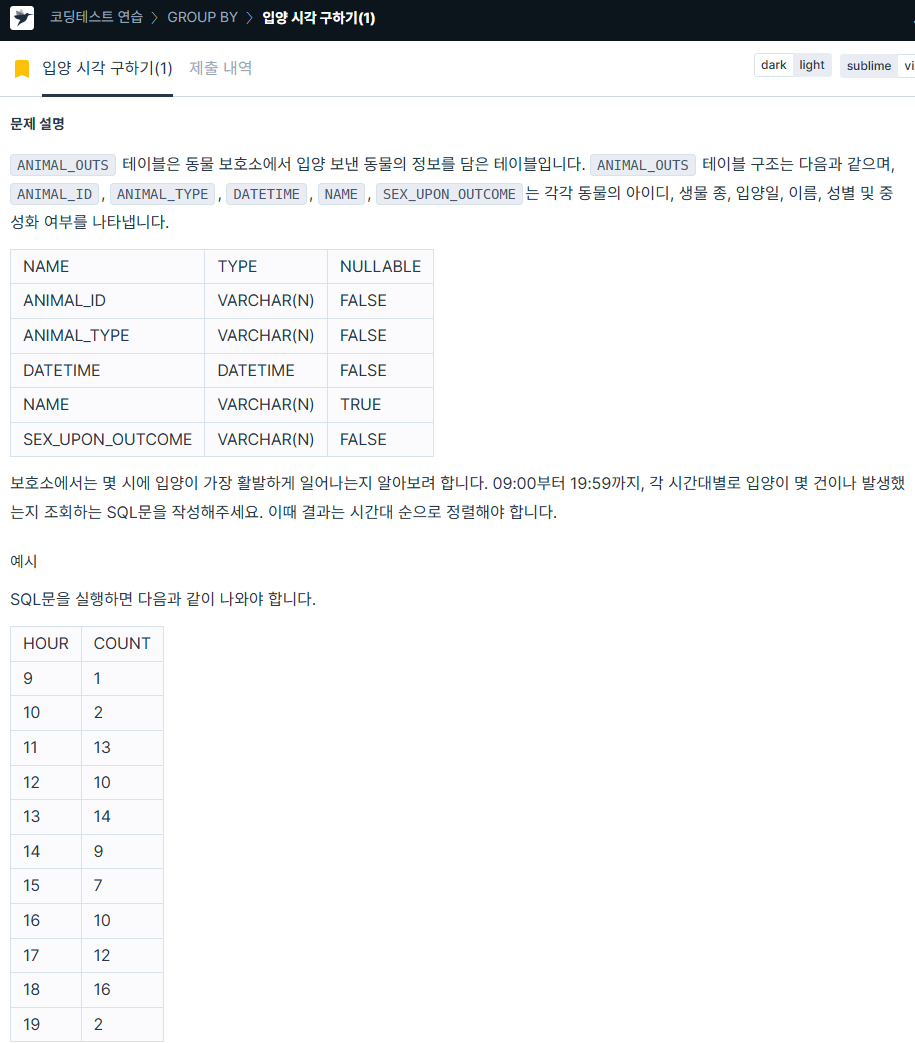
SELECT DATE_FORMAT(datetime, '%H') AS HOUR,
COUNT(*) AS 'COUNT'
FROM animal_outs
WHERE DATE_FORMAT(datetime, '%H') BETWEEN 9 AND 19
GROUP BY HOUR
ORDER BY HOUR ASC;7. 진료과별 총 예약 횟수 출력하기
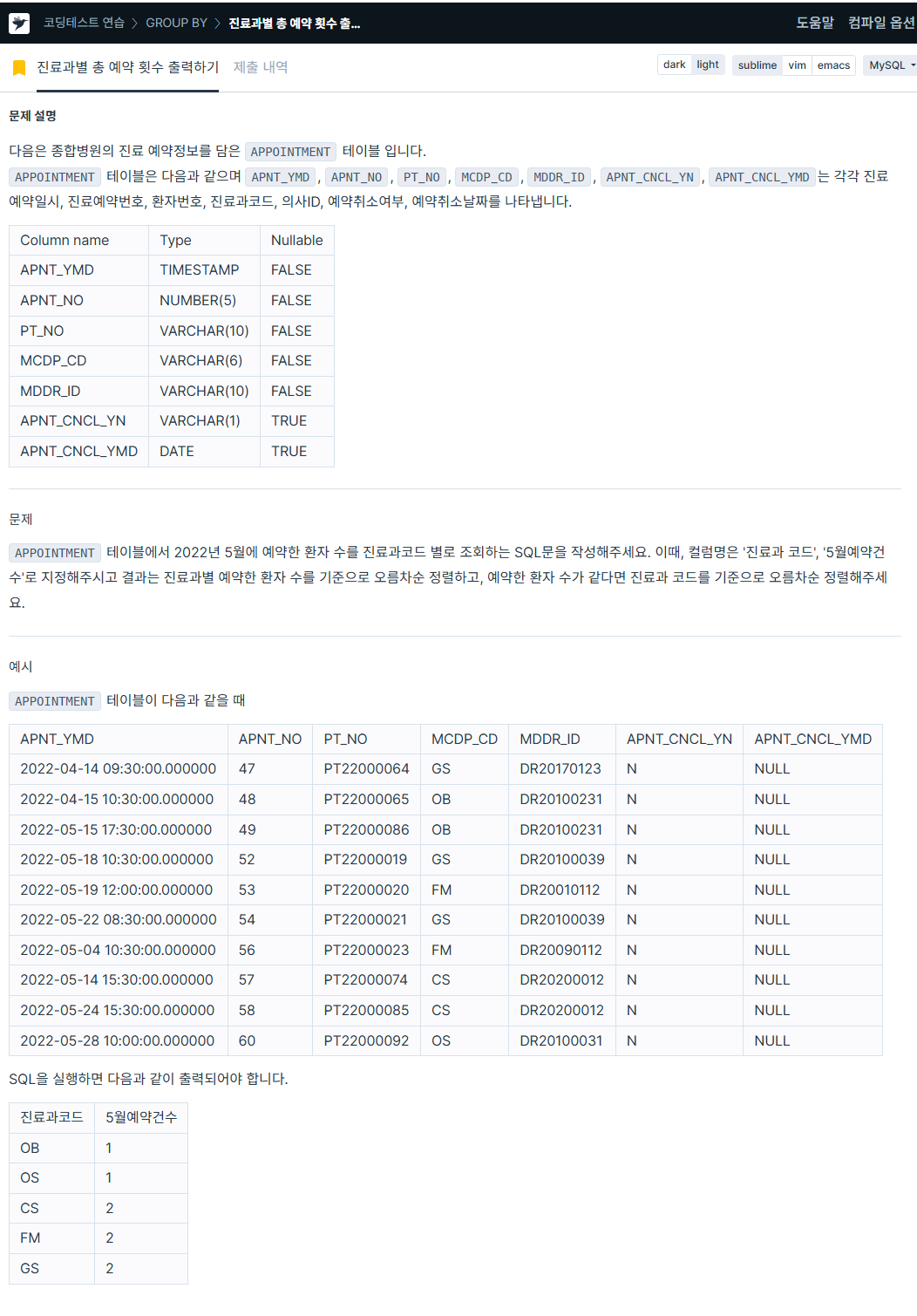
https://school.programmers.co.kr/learn/courses/30/lessons/132202
SELECT mcdp_cd AS '진료과코드',
COUNT(apnt_ymd) AS '5월예약건수'
FROM appointment
WHERE DATE_FORMAT(apnt_ymd, '%Y-%m') = '2022-05'
GROUP BY mcdp_cd
ORDER BY 2 ASC, mcdp_cd ASC;8. 12세 이하인 여자 환자 목록 출력하기
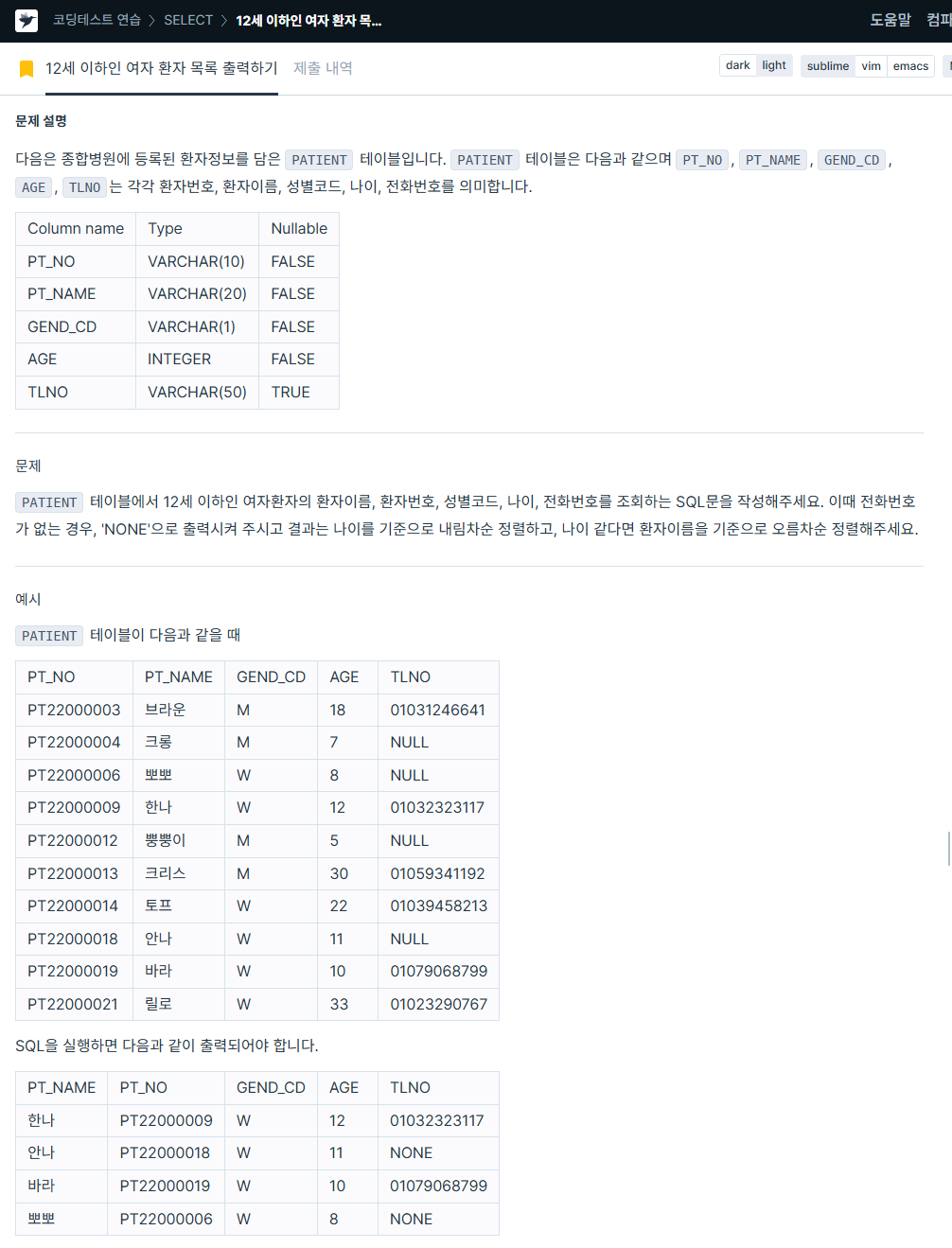
https://school.programmers.co.kr/learn/courses/30/lessons/132201
SELECT pt_name,
pt_no,
gend_cd,
age,
COALESCE(tlno, 'NONE') AS tlno
FROM patient
WHERE age <=12 and gend_cd LIKE '%W%'
ORDER BY age DESC, pt_name;9. 인기있는 아이스크림
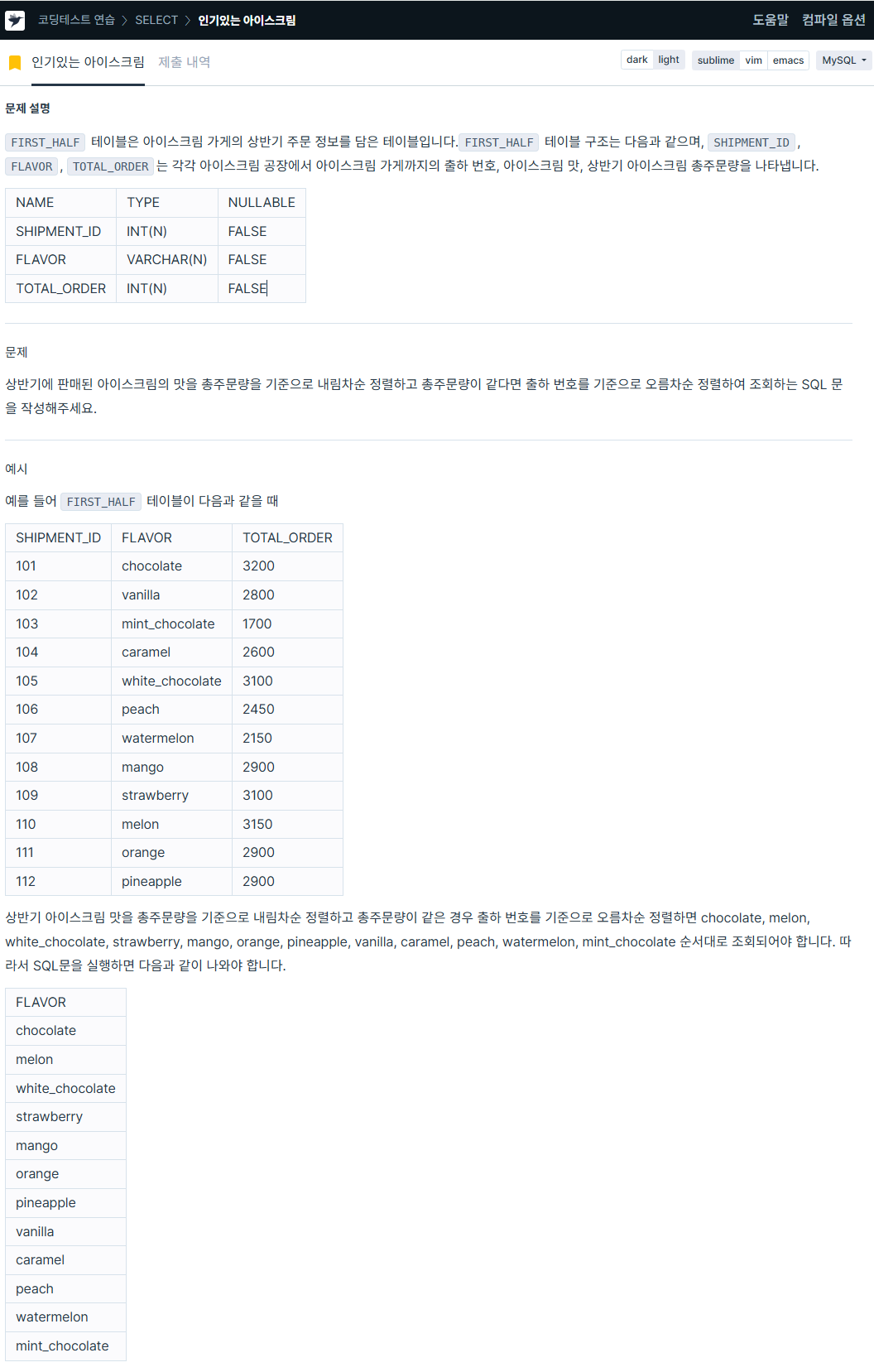
https://school.programmers.co.kr/learn/courses/30/lessons/133024
SELECT flavor
FROM first_half
ORDER BY total_order DESC, shipment_id ASC;10. 자동차 종류 별 특정 옵션이 포함된 자동차 수 구하기

SELECT car_type AS CAR_TYPE,
COUNT(*) AS CARS
FROM car_rental_company_car
WHERE options LIKE '%가죽시트%' OR options LIKE '%통풍시트%' OR options LIKE '%열선시트%'
GROUP BY car_type
ORDER BY car_type;🏃자자. 이제 파이썬을 보자.
오늘도 라이브 세션에서 배웠던 것, 실습 했던 것들을 끄적여 보였다.
# 2025.11.12 python 끄적이기
# 표준 라이브러리 <-> 외장, 외부 라이브러리 (pip install pandas)
# 파이썬을 설치 할때, 자동으로 설치되는 라이브러리(관련된 코드들의 묶음)들
# import 가져올 라이브러리 이름 -> 라이브러리 전체를 가지고 온다
# import random
# from 어디서 import 어떤 것을 -> 어디서(라이브러리에서) 어떤 것을(어떤 함수) 가져온다.
# import datetime
# from datetime import *
# `datetime.date` : 날짜(연-월-일)
# `datetime.time` : 시간(시-분-초-마이크로초, 타임존 정보 가능)
# `datetime.timedelta` : 시간 간격(연산용)
# 날짜/ 시간 다룬다.
# "2025-11-12" ~ "202-11-22" + 일주일 (7 days)
# 2025-11-30 + 7 days -> 12-07 ->> 2025-11-37
# 날짜 단위로 계산을 하려면 데이터 타입이 "날짜"
# 엑셀 파일 -> 불러온다.
from datetime import date, time, timedelta, datetime
d = date.today() # 2025-11.12
t = time(14, 30, 0) # 14:30:00
dt = datetime.now() # 현재 datetime 2025-11-12 11:38:50.880386
gap = timedelta(days=7, hours=3) # 2025-11-19 14:38:50.880386
print(d, t, dt, dt + gap, dt - timedelta(days=7)) # 2025-11-05 11:38:50.880386
# strftime 날짜 -> 문자
s = dt.strftime("%d/%m/%Y %H:%M:%S") # 12/11/2025 11:38:50
print(s)
# strptime 문자 -> 날짜
dt2 = datetime.strptime("2025-11-12 09:00:00", "%Y-%m-%d %H:%M:%S")
print(dt2) # 2025-11-12 09:00:00
# math
# 수학 계산 라이브러리
import math
print(math.pi, math.e) # 3.141592653589793 2.718281828459045
print(math.sqrt(16)) # 4.0 정수형을 넣어도 결과는 실수형으로 나온다.
print(math.pow(2, 3)) # 2^3 8.0
print(2**3) # 8
print(math.factorial(5)) # 120
print(math.ceil(4.1)) # 5 (올림)
print(math.floor(4.9)) # 4 (내림)
print(math.trunc(-4.9)) # -4 (소수점 버림; 0쪽으로 절사)
deg = 180
rad = math.radians(deg) # 각도 → 라디안
print(math.cos(rad)) # -1.0
print(math.degrees(math.pi/2)) # 90.0
a = 0.1 + 0.2 # 0.30000000000000004
print(math.isclose(a, 0.3, rel_tol=1e-9)) # True
print(math.hypot(3, 4)) # 5.0 (거리)
print(math.copysign(3, -1.0)) # -3.0 (부호 복사)
# random
import random
print(random.random()) # [0.0, 1.0) 0.0 1.0 (포함x)
print(random.randint(1, 10)) # [1, 10] 정수
print(random.randrange(0, 10, 2)) # 0,2,4,6,8
random.seed(42)
print([random.randint(1, 10) for _ in range(5)]) # 매번 같은 결과
# 표본 추출과 섞기
items = ["A", "B", "C", "D"]
print(random.choice(items)) # 임의 1개
print(random.sample(items, 2)) # 중복 없이 2개
random.shuffle(items) # 제자리 섞기 (반환값 None)
print(items)
# B를 더 자주 뽑히게
print(random.choices(["A","B","C"], weights=[1,5,1], k=5))
# os
# 내가 파일을 불러오거나 저장할 때
# 경로: 상대경로(현재 위치 기준), 절대경로 "Destop/workspace/dddd"
# 파일, 폴더 조작
# 파일 입출력
# 구구단 -> 파일 실행 -> 결과 -> 종료
# gugudan(3) 변수, 결과값 -> 휘발성 메모리
# 결과값을 파일 형태로 저장
# 값을 영구적으로 저장하기 위해 -> 파일 (하드디스크)
# 데이터 불러옴 -> 분석 -> 결과 -> 결과를 파일로 저장
# 파일 만들고 파일 불러오고
# 입력/출력 -> 작업하는 곳
# 입력 : 파일에서 값을 불러오기(가져오기)
# 출력: 작업된 값을 파일에 저장하기(쓰기)
# 파일 다루기
# 파일 만들기
f = open("data.txt", 'w', encoding="utf-8")
f.write("Hello Python!\n")
f.close()
f = open("data.txt", "r", encoding="utf-8")
print(f.read())
f.close()
# 파일의 입출력 -> 컴퓨터가 힘들어하는 작업
# 오류가 최대한 나지 않게
# with
with open("data.txt", "r", encoding="utf-8") as f:
print(f.read())
# csv json
# csv : Comma-Seperated Values
import csv
with open("scores.csv", "r", encoding="utf-8") as f:
reader = csv.reader(f)
for row in reader:
print(row)
# 딕셔너리로 불러오기
import csv
with open("scores.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
print(row)
# 원하는 데이터만 뽑아오기
import csv
with open("scores.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
print(row["name"],row["math"])
# CSV 파일 쓰기
import csv
data = [
["name", "kor", "eng", "math"],
["Hannah", 90, 95, 85],
["Minjun", 80, 88, 92],
]
with open("scores.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(data)
# write 옵션을 사용해서 작성할 때, 중복 데이터 처리하는 방법이 있을까? -> 잡담방에 올리기
# json -> JavaScript Object Notation
# 딕셔너리와 비슷 (키-값)
import json
student = {
"name": "Hannah",
"scores": [90, 95, 85],
"average": 90.0
}
with open("student.json", "w", encoding="utf-8") as f:
json.dump(student, f, ensure_ascii=False, indent=4)
import json
with open("student.json", "r", encoding="utf-8") as f:
data = json.load(f)
print(data["name"])
print(data["average"])3. 학습하며 겪었던 문제점 & 에러
🖥️프로그래머스 문제를 풀어보자.
1. 물고기 종류 별 대어 찾기
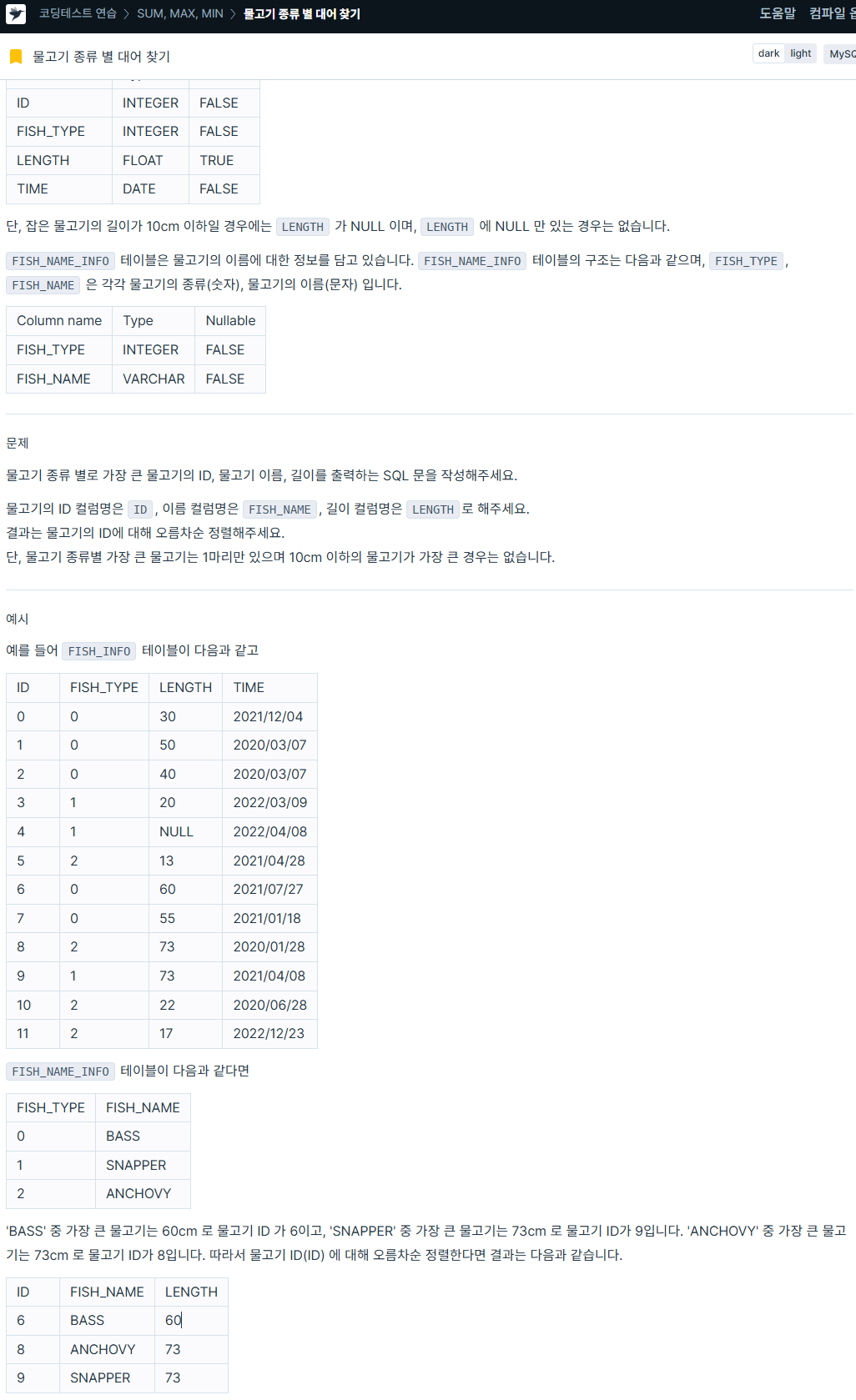
https://school.programmers.co.kr/learn/courses/30/lessons/293261
SELECT ID,
FISH_NAME,
LENGTH
FROM (
SELECT a.id AS ID,
b.fish_name AS FISH_NAME,
a.length AS LENGTH,
ROW_NUMBER() OVER (PARTITION BY b.fish_name ORDER BY a.length DESC, a.id ASC) AS max_len # 윈도우 함수로 fish_name별 group 만들고 length가 큰 순서로 각 그룹에서 순위 매기기
FROM fish_info a
JOIN fish_name_info b
ON a.fish_type = b.fish_type) AS sub # subquery에서 fish_type으로 join
WHERE max_len = 1 # subquery에서 계산된 max_len에서 각 fish_name 별 1등만 필터링
ORDER BY ID ASC;쿼리 흐름을 보자.
- FROM + JOIN
- fish_info a와 fish_name_info b를 fish_type으로 조인해, 각 행에 이름(FISH_NAME) 를 붙임
- 윈도우 함수로 랭킹 매기기
- ROW_NUMBER() OVER (PARTITION BY b.fish_name ORDER BY a.length DESC, a.id ASC)
- 이름별(FISH_NAME별) 그룹을 만들고
- 길이 length가 큰 순서로 정렬(동률이면 ID가 작은 순)
- 각 그룹에서 순위를 매김
- 최대 길이 행만 선택
- 바깥 쿼리에서 WHERE max_len = 1로 각 이름별 1등(=최대 길이, 동률 시 가장 작은 ID) 만 남김
- 정렬
- 최종 결과를 order by id asc로 정렬
🖥️백준 문제도 보자.
4. 내일 학습 할 것은 무엇인지
내일도 SQLD 공부 위주로 하고,
라이브 세션 놓치지 않게 하고,
코드카타 잘 풀고 있자.
피곤하지만,
늘 TIL 적으면서 말했듯이,
그냥 해.
어쩔수 없어.
견뎌 그냥.



