
피
곤
해
밥먹고 좀 걸어야겠다.
몸이 피곤피곤~
니 머리는 멍충멍충~
1. 오늘 학습 키워드
오늘은
1. 라이브세션 복습
2. 프로그래머스 2문제 풀기
3. 코드카타 35번까지 풀기
4. SQLD 공부
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
🏃먼저. SQL을 보자.
오늘은 코드카타 35번까지 풀어보았다.
이제 점점 쿼리가 길어진다.
그래도 재미있다.
1. 오랜 기간 보호한 동물(1)
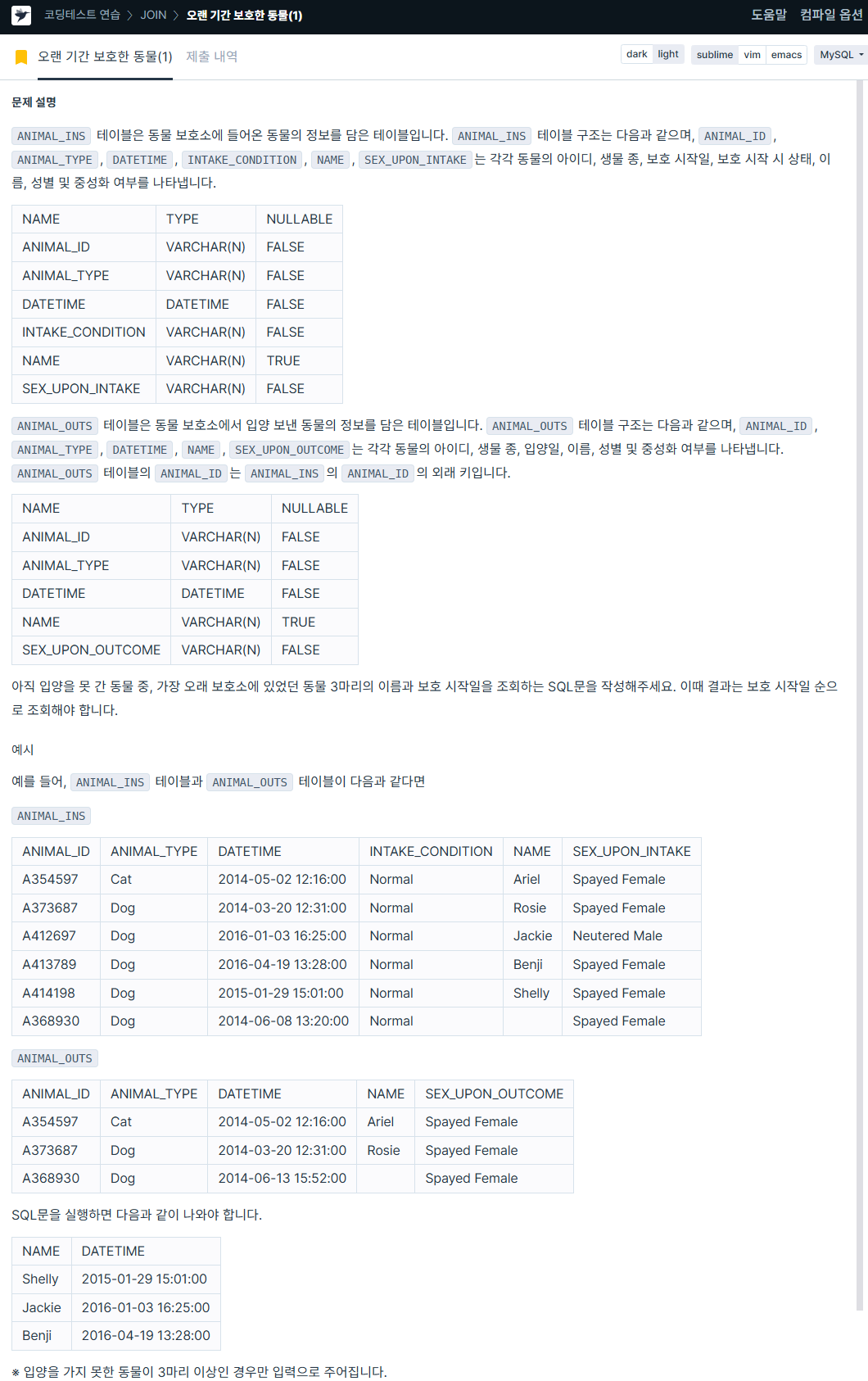
https://school.programmers.co.kr/learn/courses/30/lessons/59044
SELECT i.name AS NAME, i.datetime AS DATETIME
FROM animal_ins AS i LEFT JOIN animal_outs AS o ON i.animal_id = o.animal_id
WHERE o.datetime IS NULL
ORDER BY i.DATETIME ASC LIMIT 3;2. 카테고리 별 도서 판매량 집계하기
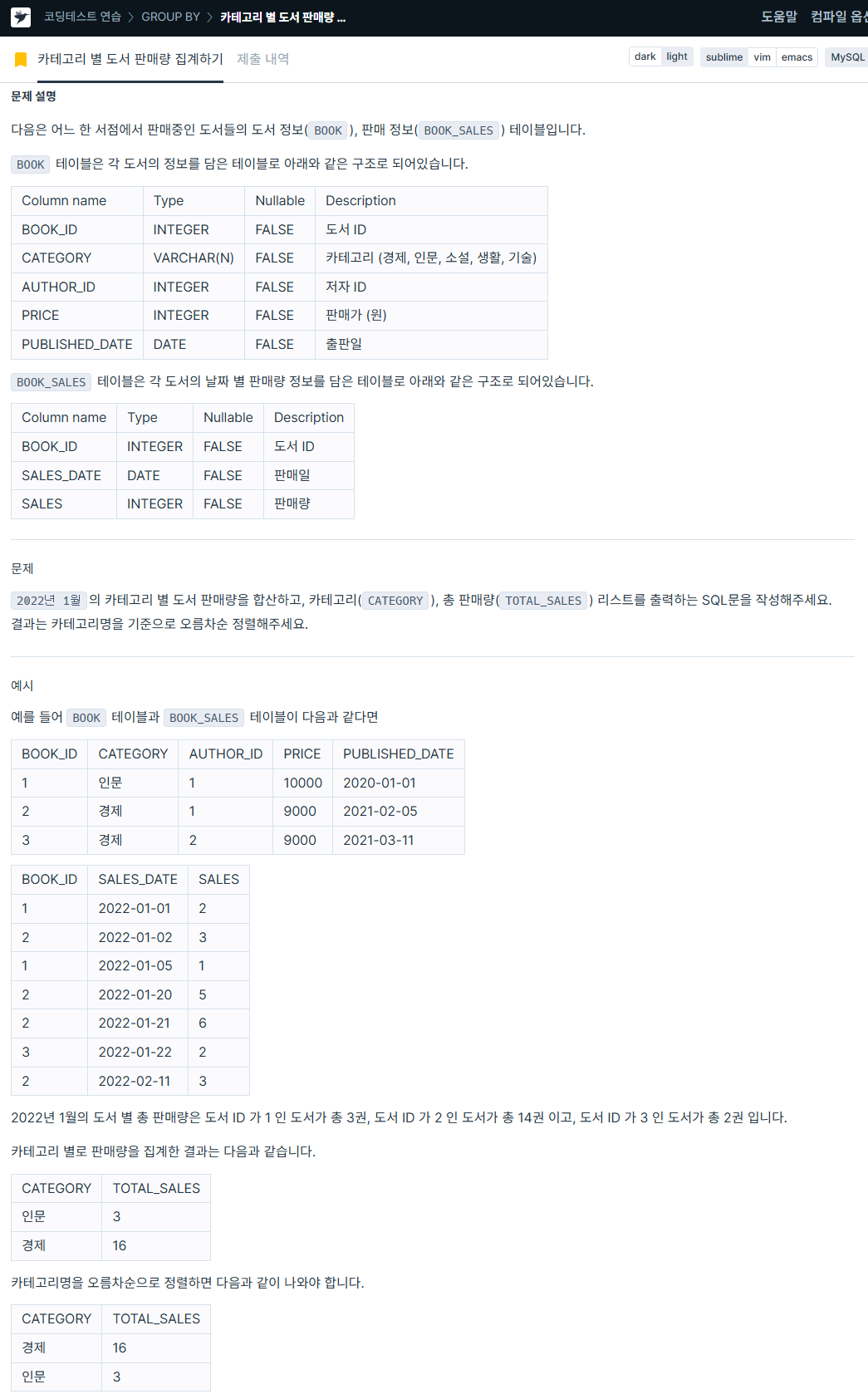
https://school.programmers.co.kr/learn/courses/30/lessons/144855
SELECT b.CATEGORY,
SUM(s.SALES) AS TOTAL_SALES
FROM BOOK AS b JOIN BOOK_SALES AS s ON b.BOOK_ID = s.BOOK_ID
WHERE s.SALES_DATE >= '2022-01-01' AND s.SALES_DATE < '2022-02-01'
GROUP BY b.CATEGORY
ORDER BY b.CATEGORY ASC;3. 상품 별 오프라인 매출 구하기
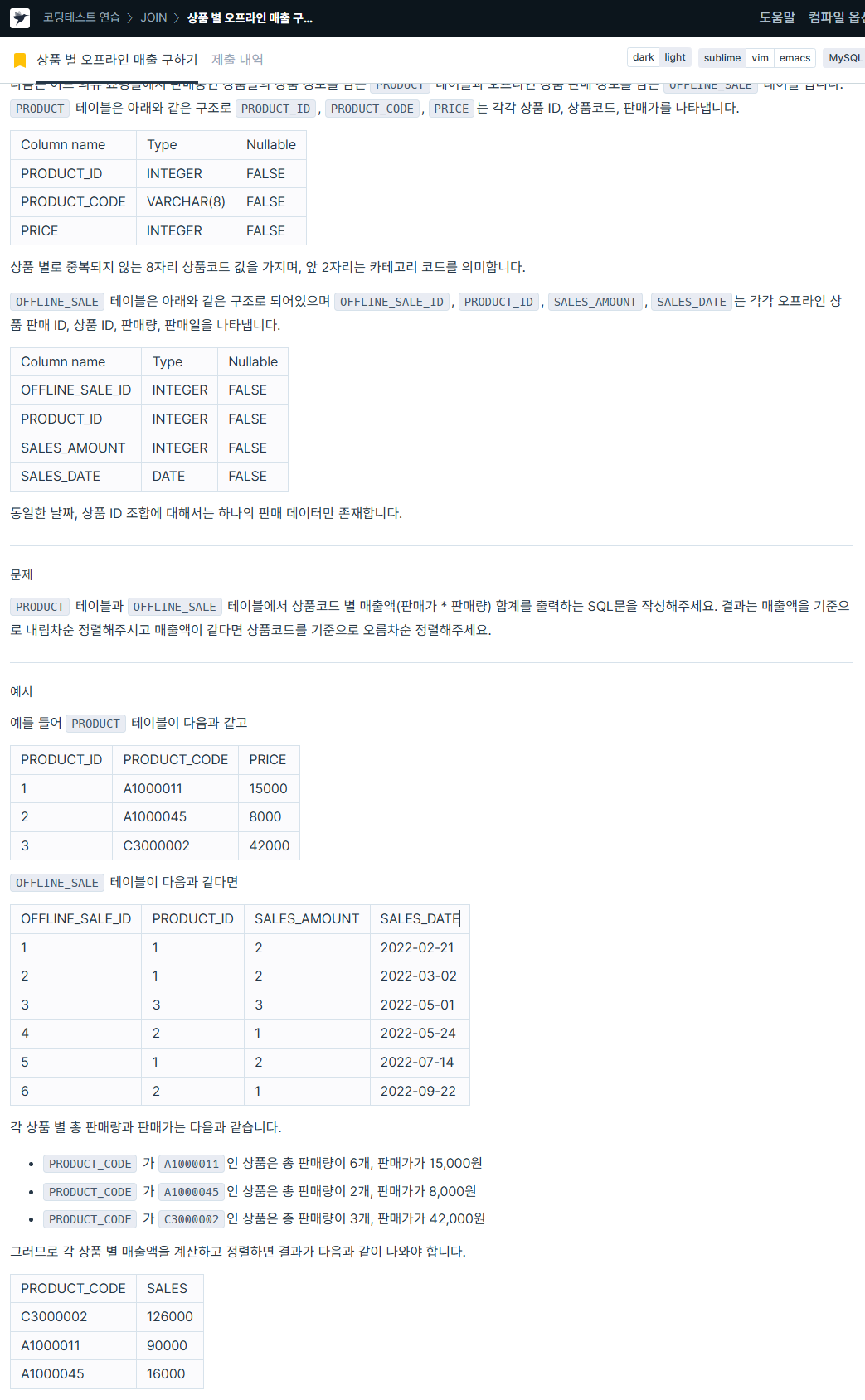
https://school.programmers.co.kr/learn/courses/30/lessons/131533
SELECT t.product_code AS PRODUCT_CODE,
(t.price * t.total_amount) AS SAELS # 서브쿼리에서 미리 구한 총 판매량 * 가격 곱해서 총 매출액 구하기
FROM(
SELECT p.product_code,
p.price,
SUM(o.sales_amount) AS total_amount # 필요한 컬럼 불러오고, SUM이용해서 그룹별 총 판매량 미리 구하기
FROM product p JOIN offline_sale o ON p.product_id = o.product_id # PRODUCT_ID로 JOIN하기
GROUP BY p.product_code) as t
GROUP BY PRODUCT_CODE
ORDER BY (t.price * t.total_amount) DESC, PRODUCT_CODE ASC; # 총 매출액 내림차순, 상품코드 기준 오름차순 정렬
4. 있었는데요 없었습니다
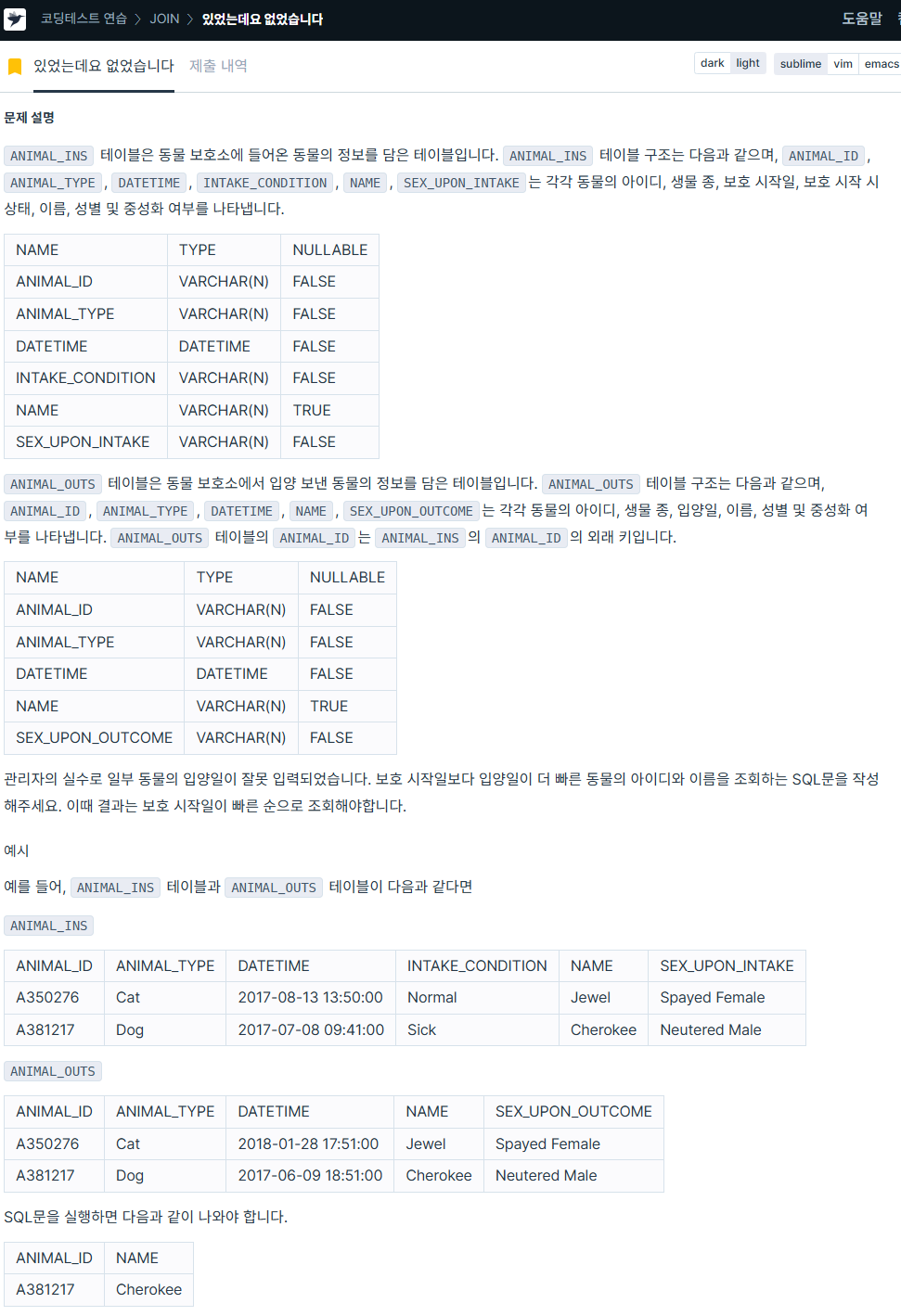
https://school.programmers.co.kr/learn/courses/30/lessons/59043
SELECT i.animal_id AS ANIMAL_ID,
i.name AS NAME
FROM animal_ins i JOIN animal_outs o ON i.animal_id = o.animal_id
WHERE i.datetime > o.datetime # 보호 시작일 > 입양일 조건 고려 작성
ORDER BY i.datetime ASC; # 보호 시작일 5. 오랜 기간 보호한 동물(2)
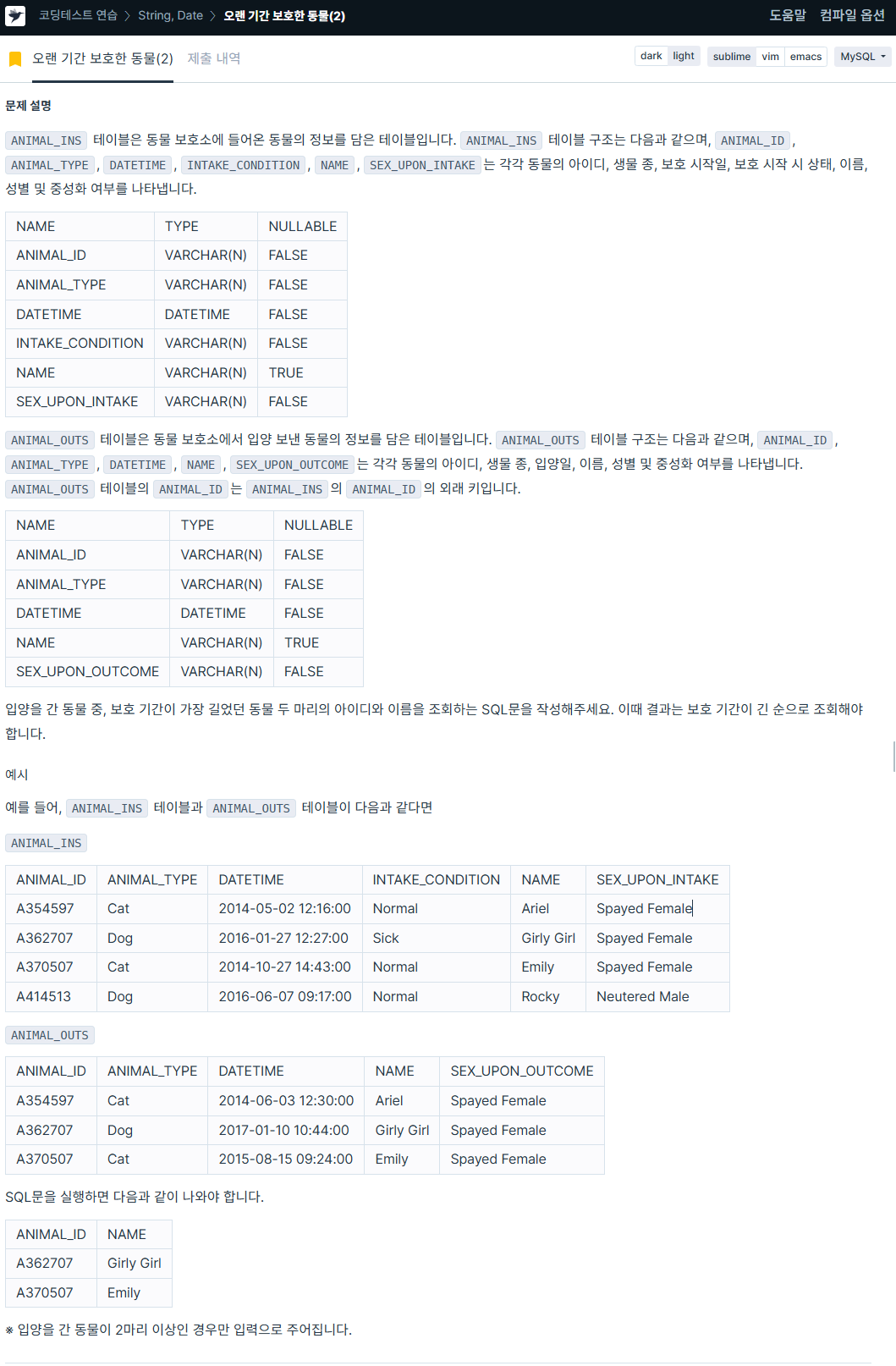
https://school.programmers.co.kr/learn/courses/30/lessons/59411
SELECT a.animal_id AS ANIMAL_ID,
a.name AS NAME
FROM (
SELECT i.animal_id,
i.name,
DATEDIFF(o.datetime, i.datetime) AS period # 서브 쿼리 이용해서 보호기간 미리 구하기
FROM animal_ins i JOIN animal_outs o ON i.animal_id = o.animal_id) AS a
ORDER BY a.period DESC LIMIT 2; # 보호기간 가장 길었던 동물 2마리 구하기🏃자자. 이제 파이썬을 보자.
# csv 파일, 데이터 불러오기
import csv
# with open~
with open("school_scores.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f) # 첫 행 : 키 - 나머지 : 값
for row in reader:
print(row["name"], row["kor"])
# 다른 것
import csv
with open("school_scores.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f) # 첫 행 : 키 - 나머지 : 값
students = list(reader)
print(students)
#[{'name': 'Hannah', 'kor': '90', 'eng': '95', 'math': '85'},
# {'name': 'Minjun', 'kor': '80', 'eng': '88', 'math': '92'},
# {'name': 'Yujin', 'kor': '75', 'eng': '85', 'math': '100'},
# {'name': 'Dohyeok', 'kor': '100', 'eng': '70', 'math': '88'},
# {'name': 'Suyun', 'kor': '88', 'eng': '90', 'math': '93'},
# {'name': 'Jiwon', 'kor': '95', 'eng': '97', 'math': '99'},
# {'name': 'Hojun', 'kor': '65', 'eng': '75', 'math': '60'},
# {'name': 'Yuna', 'kor': '78', 'eng': '82', 'math': '85'},
# {'name': 'Taeyang', 'kor': '92', 'eng': '89', 'math': '91'},
# {'name': 'Seojin', 'kor': '55', 'eng': '70', 'math': '68'}]
# 데이터를 먼저 확인 -> 어떤 처리를 해줄 것인가?
# 문자열 -> 숫자 int(input()) 형변환
# 1. 리스트 안에 하나의 원소에 우선 접근하자 student[i] = {'name': 'Hannah', 'kor': '90', 'eng': '95', 'math': '85'}
# 2. 딕셔너리에서는 000["key"]
for i in students:
# 1번째 순회 : i = {'name': 'Hannah', 'kor': '90', 'eng': '95', 'math': '85'}
# 2번째 순회 : i = {'name': 'Minjun', 'kor': '80', 'eng': '88', 'math': '92'}
i["kor"] = int(i["kor"])
i["eng"] = int(i["eng"])
i["math"] = int(i["math"])
print(students)
# 한 과목의 점수가 여러 개 있을 때,
# num = [1, 2, 3]
# 평균
# kor + eng + math / 3
# 리스트 한 줄씩 접근 -> 점수들의 평균
for i in students:
avg = (i["kor"] + i["eng"] + i["math"]) / 3 # 평균
i["avg"] = avg
print(students)
"""
[{'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85, 'avg': 90.0},
{'name': 'Minjun', 'kor': 80, 'eng': 88, 'math': 92, 'avg': 86.66666666666667},
{'name': 'Yujin', 'kor': 75, 'eng': 85, 'math': 100, 'avg': 86.66666666666667},
{'name': 'Dohyeok', 'kor': 100, 'eng': 70, 'math': 88, 'avg': 86.0},
{'name': 'Suyun', 'kor': 88, 'eng': 90, 'math': 93, 'avg': 90.33333333333333},
{'name': 'Jiwon', 'kor': 95, 'eng': 97, 'math': 99, 'avg': 97.0},
{'name': 'Hojun', 'kor': 65, 'eng': 75, 'math': 60, 'avg': 66.66666666666667},
{'name': 'Yuna', 'kor': 78, 'eng': 82, 'math': 85, 'avg': 81.66666666666667},
{'name': 'Taeyang', 'kor': 92, 'eng': 89, 'math': 91, 'avg': 90.66666666666667},
{'name': 'Seojin', 'kor': 55, 'eng': 70, 'math': 68, 'avg': 64.33333333333333}]
"""
# 합격 여부
# 합격 (>=80) / 불합격
# 리스트 한 줄에 접근 -> 딕셔너리에서 평균에 접근
# 조건문
for i in students:
# 1: i = {'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85, 'avg': 90.0}
if i["avg"] >= 80:
i["status"] = "합격"
else:
i["status"] = "불합격"
print(students)
"""
[{'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85, 'avg': 90.0, 'status': '합격'},
{'name': 'Minjun', 'kor': 80, 'eng': 88, 'math': 92, 'avg': 86.66666666666667, 'status': '합격'},
{'name': 'Yujin', 'kor': 75, 'eng': 85, 'math': 100, 'avg': 86.66666666666667, 'status': '합격'},
{'name': 'Dohyeok', 'kor': 100, 'eng': 70, 'math': 88, 'avg': 86.0, 'status': '합격'},
{'name': 'Suyun', 'kor': 88, 'eng': 90, 'math': 93, 'avg': 90.33333333333333, 'status': '합격'},
{'name': 'Jiwon', 'kor': 95, 'eng': 97, 'math': 99, 'avg': 97.0, 'status': '합격'},
{'name': 'Hojun', 'kor': 65, 'eng': 75, 'math': 60, 'avg': 66.66666666666667, 'status': '불합격'},
{'name': 'Yuna', 'kor': 78, 'eng': 82, 'math': 85, 'avg': 81.66666666666667, 'status': '합격'},
{'name': 'Taeyang', 'kor': 92, 'eng': 89, 'math': 91, 'avg': 90.66666666666667, 'status': '합격'},
{'name': 'Seojin', 'kor': 55, 'eng': 70, 'math': 68, 'avg': 64.33333333333333, 'status': '불합격'}]
"""
# 한꺼번에 순회 돌기
for i in students:
i["kor"] = int(i["kor"])
i["eng"] = int(i["eng"])
i["math"] = int(i["math"])
avg = (i["kor"] + i["eng"] + i["math"]) / 3 # 평균
i["avg"] = avg
if i["avg"] >= 80:
i["status"] = "합격"
else:
i["status"] = "불합격"
print(students)
"""
[{'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85, 'avg': 90.0, 'status': '합격'},
{'name': 'Minjun', 'kor': 80, 'eng': 88, 'math': 92, 'avg': 86.66666666666667, 'status': '합격'},
{'name': 'Yujin', 'kor': 75, 'eng': 85, 'math': 100, 'avg': 86.66666666666667, 'status': '합격'},
{'name': 'Dohyeok', 'kor': 100, 'eng': 70, 'math': 88, 'avg': 86.0, 'status': '합격'},
{'name': 'Suyun', 'kor': 88, 'eng': 90, 'math': 93, 'avg': 90.33333333333333, 'status': '합격'},
{'name': 'Jiwon', 'kor': 95, 'eng': 97, 'math': 99, 'avg': 97.0, 'status': '합격'},
{'name': 'Hojun', 'kor': 65, 'eng': 75, 'math': 60, 'avg': 66.66666666666667, 'status': '불합격'},
{'name': 'Yuna', 'kor': 78, 'eng': 82, 'math': 85, 'avg': 81.66666666666667, 'status': '합격'},
{'name': 'Taeyang', 'kor': 92, 'eng': 89, 'math': 91, 'avg': 90.66666666666667, 'status': '합격'},
{'name': 'Seojin', 'kor': 55, 'eng': 70, 'math': 68, 'avg': 64.33333333333333, 'status': '불합격'}]
"""
# 누락 데이터
'''
name,kor,eng,math
Hannah,90,95,85
Minjun,80,,92
Yujin,abc,85,100
Dohyeok,100,70,88
'''
# for i in students:
# # 한 번 순회할 때마다 다 해결하기
# i["kor"] = int(i["kor"])
# i["eng"] = int(i["eng"])
# i["math"] = int(i["math"])
# avg = (i["kor"] + i["eng"] + i["math"]) / 3 # 평균
# i["avg"] = avg
# if i['avg'] >= 80:
# i['status'] = "합격"
# else:
# i['status'] = "불합격"
# print(students)
'''
Traceback (most recent call last):
File "day8.py", line 122, in <module>
i["eng"] = int(i["eng"])
ValueError: invalid literal for int() with base 10: ''
'''
# students["없는키"] -> 오류 발생
# .get("") -> None
# 예외처리
for i in students:
# 한 번 순회할 때마다 다 해결하기
try:
i["kor"] = int(i["kor"])
i["eng"] = int(i["eng"])
i["math"] = int(i["math"])
# except ValueError as ve:
# # 오류가 발생했을 때 실행할 코드
# print(f"값 오류가 발생했습니다. 이 값을 건너뜁니다.: {ve}") # 오류가 발생했습니다.: invalid literal for int() with base 10: 'abc'
# continue
except Exception as e:
print(f"오류가 발생했습니다: {e}")
print(students)
# [{'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85}, {'name': 'Minjun', 'kor': 80, 'eng': '', 'math': '92'}, {'name': 'Yujin', 'kor': 'abc', 'eng': '85', 'math': '100'}, {'name': 'Dohyeok', 'kor': 100, 'eng': 70, 'math': 88}]
# 예외 처리 형태
# try: except:
# 데이터를 가져와서 -> 전처리(숫자로 만들기) -> 분석(평균, 합격여부판단)
# 하나의 함수로
# print()
# 함수 import datetime
# 효율적 -> 반복 피하기 -> 재활용 용의
# def 함수이름():
# return
# {}
# 평균을 구해서 합격 불합격 판단을 해주는 함수
def analyze_socres(scores):
# 숫자값으로 바꿔주기
try:
kor = int(scores["kor"])
eng = int(scores["eng"])
math = int(scores["math"])
avg = (kor + eng + math) / 3
if avg >= 80:
status = "합격"
else:
status = "불합격"
except Exception as e:
print("에러 발생")
# 평균 구하기
# 합격 여부 판단
return {"name": scores["name"], "avg": avg, "status": status}
# 이름, 평균, 합격여부
results = []
for s in students:
# 1: s - {'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85}
r = analyze_socres(s)
if r:
results.append(r)
print(results)
# [{'name': 'Hannah', 'avg': 90.0, 'status': '합격'},
# {'name': 'Minjun', 'avg': 86.66666666666667, 'status': '합격'},
# {'name': 'Yujin', 'avg': 86.66666666666667, 'status': '합격'},
# {'name': 'Dohyeok', 'avg': 86.0, 'status': '합격'},
# {'name': 'Suyun', 'avg': 90.33333333333333, 'status': '합격'},
# {'name': 'Jiwon', 'avg': 97.0, 'status': '합격'},
# {'name': 'Hojun', 'avg': 66.66666666666667, 'status': '불합격'},
# {'name': 'Yuna', 'avg': 81.66666666666667, 'status': '합격'},
# {'name': 'Taeyang', 'avg': 90.66666666666667, 'status': '합격'},
# {'name': 'Seojin', 'avg': 64.33333333333333, 'status': '불합격'}]
# 파일로 출력하기
# json 파일로 출력하기
import json
with open("reuslts.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=4)
print("파일이 완성되었습니다.")
# 데이터 불러오기
# 데이터 전처리
# 데이터 분석(평균, 합격)
# 예외 처리
# 데이터 출력3. 학습하며 겪었던 문제점 & 에러
🖥️프로그래머스 문제를 풀어보자.
1. 연간 평가점수에 해당하는 평가 등급 및 성과금 조회하기
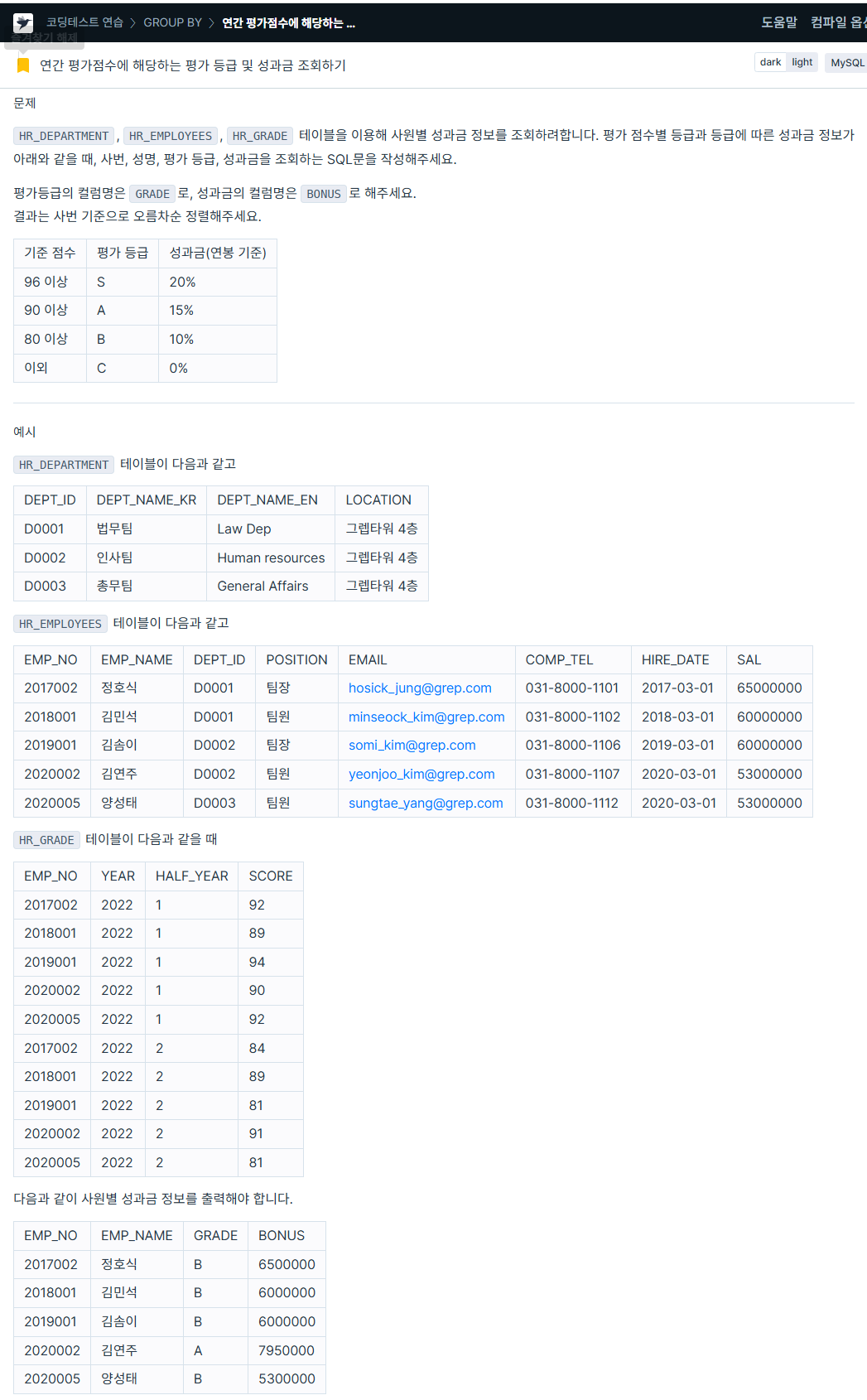
https://school.programmers.co.kr/learn/courses/30/lessons/284528
# 초기 작성 쿼리
SELECT a.emp_no AS EMP_NO,
a.emp_name AS EMP_NAME,
a.grade AS GRADE,
CASE WHEN a.grade = 'S' THEN (a.sal * 0.2)
WHEN a.grade = 'A' THEN (a.sal * 0.15)
WHEN a.grade = 'B' THEN (a.sal * 0.1)
ELSE (a.sal * 0) END AS BONUS
FROM (
SELECT CASE WHEN g.score >= 96 THEN 'S'
WHEN g.score >= 90 THEN 'A'
WHEN g.score >= 80 THEN 'B'
ELSE 'C' END AS grade,
e.emp_no,
e.emp_name,
e.sal
FROM hr_employees e
JOIN hr_grade g ON e.emp_no = g.emp_no) AS a
ORDER BY a.emp_no ASC;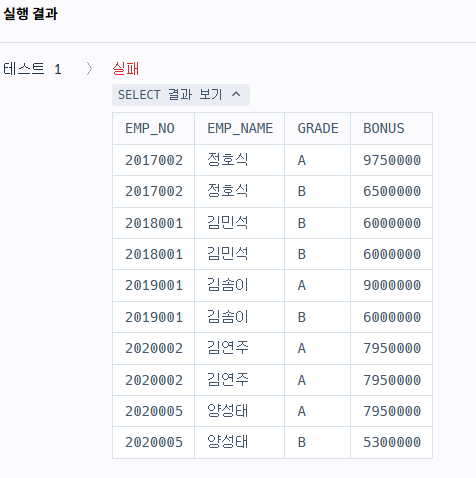
초기 쿼리 작성은 이렇게 했었고, 전략은 이러했다.
1. subquery에서 grade를 미리 계산, 그런다음 hr_grade와 hr_employees와 join
2. 메인 쿼리에서 case when 사용하여 보너스 금액 산정
3. 정렬
근데 실행 결과를 보니까 이름이 2개씩 나온다....
그래서 원인을 분석해보니까
1. hr_grade 테이블에서 반기별로 점수를 산정하였다.
2. 그래서 반기별로 점수가 매겨지고, 보너스가 정해졌다.
이를 해결 하기 위해서는 뭘 해야하냐,
바로 avg(), group by를 이용해서 올해 평균 점수를 구하는 것이다.
# 수정 후 쿼리
SELECT a.emp_no AS EMP_NO,
a.emp_name AS EMP_NAME,
a.grade AS GRADE,
CASE WHEN a.grade = 'S' THEN (a.sal * 0.2)
WHEN a.grade = 'A' THEN (a.sal * 0.15)
WHEN a.grade = 'B' THEN (a.sal * 0.1)
ELSE (a.sal * 0) END AS BONUS
FROM (
SELECT CASE WHEN g.avg_score >= 96 THEN 'S'
WHEN g.avg_score >= 90 THEN 'A'
WHEN g.avg_score >= 80 THEN 'B'
ELSE 'C' END AS grade,
e.emp_no,
e.emp_name,
e.sal
FROM hr_employees e
JOIN
(SELECT AVG(score) AS avg_score,
emp_no
FROM hr_grade
group by emp_no) AS g # 성과 점수를 반기 간격으로 맞추었기에, avg(), group by 이용해서 사번 별 평균 점수 산출
ON e.emp_no = g.emp_no) AS a # hr_employees, hr_grade join
ORDER BY a.emp_no ASC;
쿼리 흐름을 보게 되면,
- g subquery에서 성과 점수를 반기별이 아닌, 년단위로 하여 구해야 하므로, avg(), group by를 이용해서 사번 별 평균 점수를 낸다
- a subquery에서 조인을 하고, case when을 이용해서 grade 나눈다
- 메인 쿼리에서 case when을 이용하여 보너스 금액을 산출한다.
- 사번으로 오름차순 정렬
2. 조건에 맞는 개발자 찾기
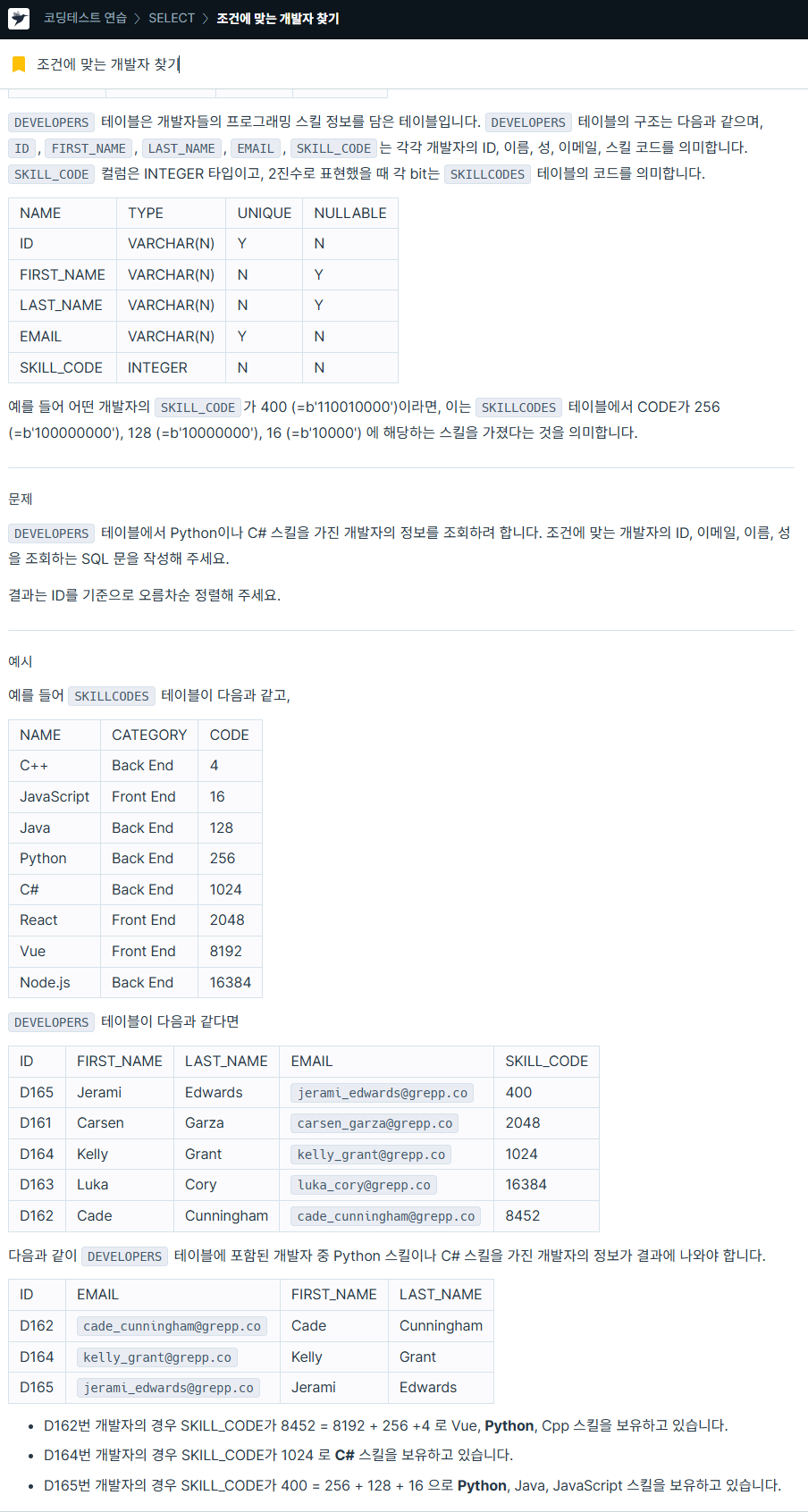
https://school.programmers.co.kr/learn/courses/30/lessons/276034
SELECT ID,
EMAIL,
FIRST_NAME,
LAST_NAME
FROM DEVELOPERS
WHERE SKILL_CODE & (
SELECT SUM(CODE)
FROM SKILLCODES
WHERE NAME IN ('Python', 'C#'))
ORDER BY ID ASC;🖥️백준 문제도 보자.
주말에 풀 예정....SQLD로 정신 없네요...
4. 내일 학습 할 것은 무엇인지
내일도 내일도
난 똑같이 이렇게 문제 풀고,
라이브 세션 복습하고,
SQLD 공부할 것이다.
힘내자 반복적인 생활



