
SQLD 시험이 끝났다.
끝나고 오랜만에 사람들과 만나서,
교류를 하였다.
정말 재미있었다.
1. 오늘 학습 키워드
오늘은
1. 라이브세션 복습
2. 백준, 프로그래머스 2문제씩 풀기
3. 코드카타 45번까지 풀기
2. 오늘 학습 한 내용을 나만의 언어로 정리하기
🏃먼저. SQL을 보자.
오늘은 코드 카타를 45번까지 풀어보았다.
1. 조건에 맞는 도서 리스트 출력하기
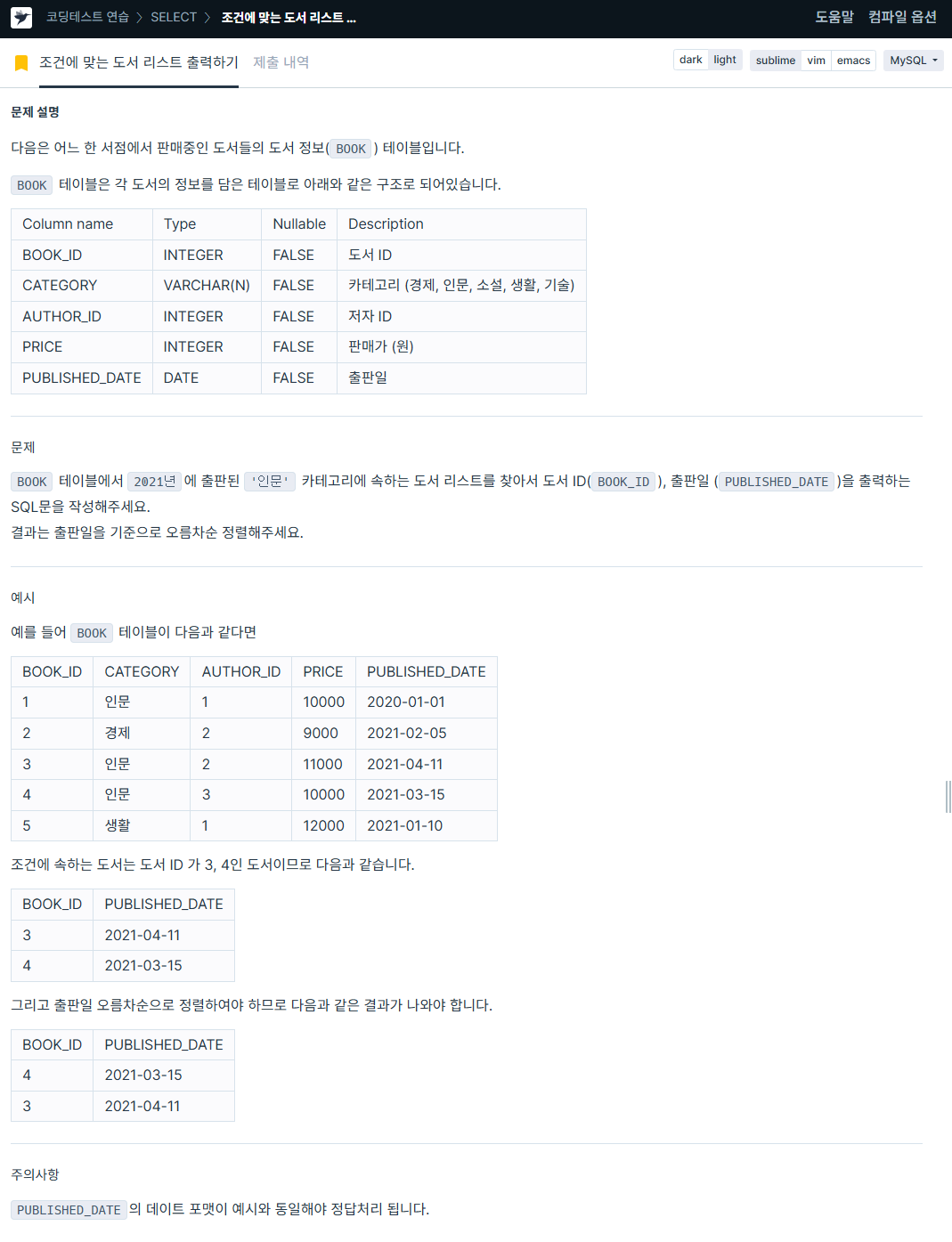
https://school.programmers.co.kr/learn/courses/30/lessons/144853
SELECT BOOK_ID, DATE_FORMAT(PUBLISHED_DATE, '%Y-%m-%d') AS PUBLISHED_DATE
FROM BOOK
WHERE PUBLISHED_DATE BETWEEN '2021-01-01' AND '2021-12-31'
AND CATEGORY LIKE "%인문%"
ORDER BY BOOK_ID DESC;2. 평균 일일 대여 요금 구하기
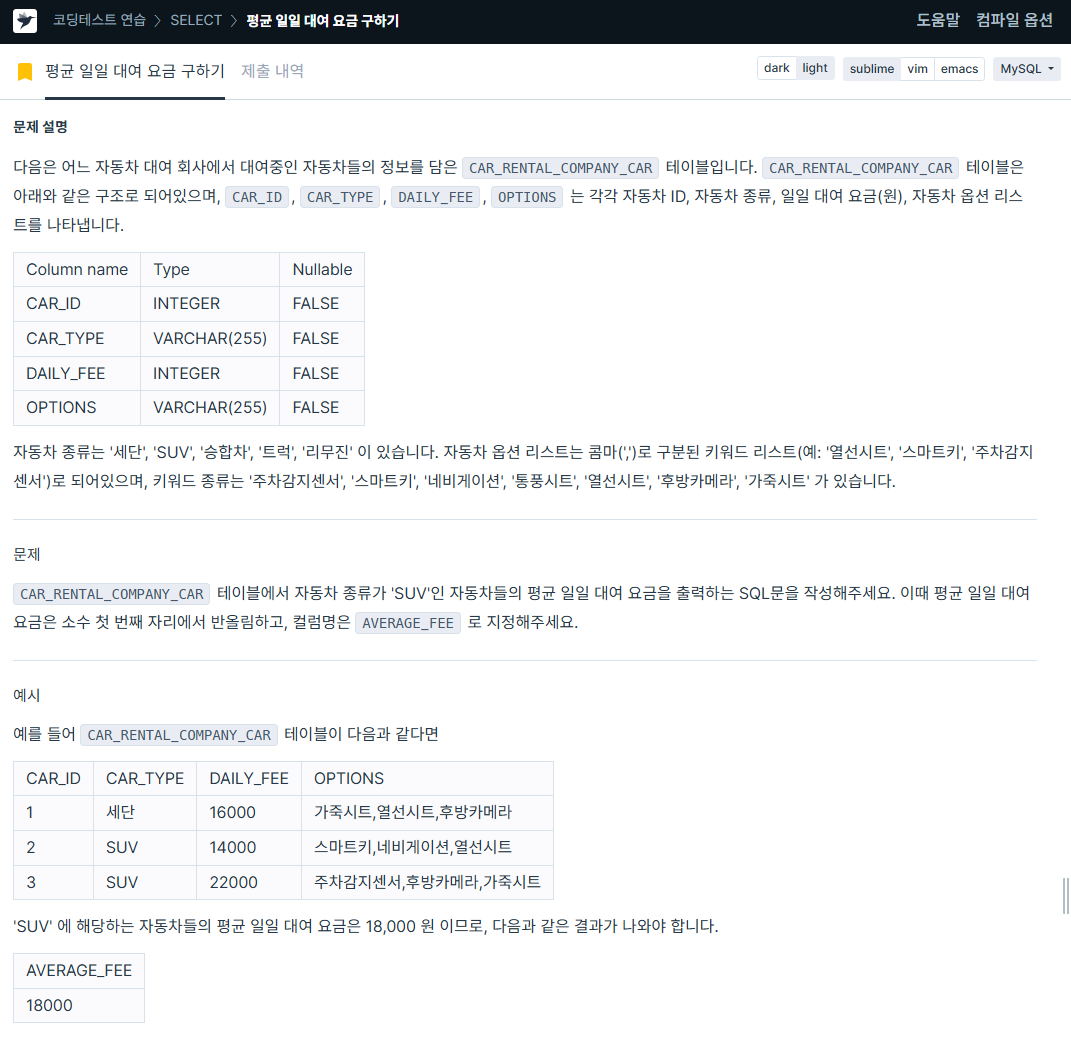
https://school.programmers.co.kr/learn/courses/30/lessons/151136
SELECT ROUND(AVG(DAILY_FEE), 0) AS AVERAGE_FEE
FROM CAR_RENTAL_COMPANY_CAR
WHERE CAR_TYPE LIKE '%SUV%';3. 조건에 맞는 사용자와 총 거래금액 조회하기
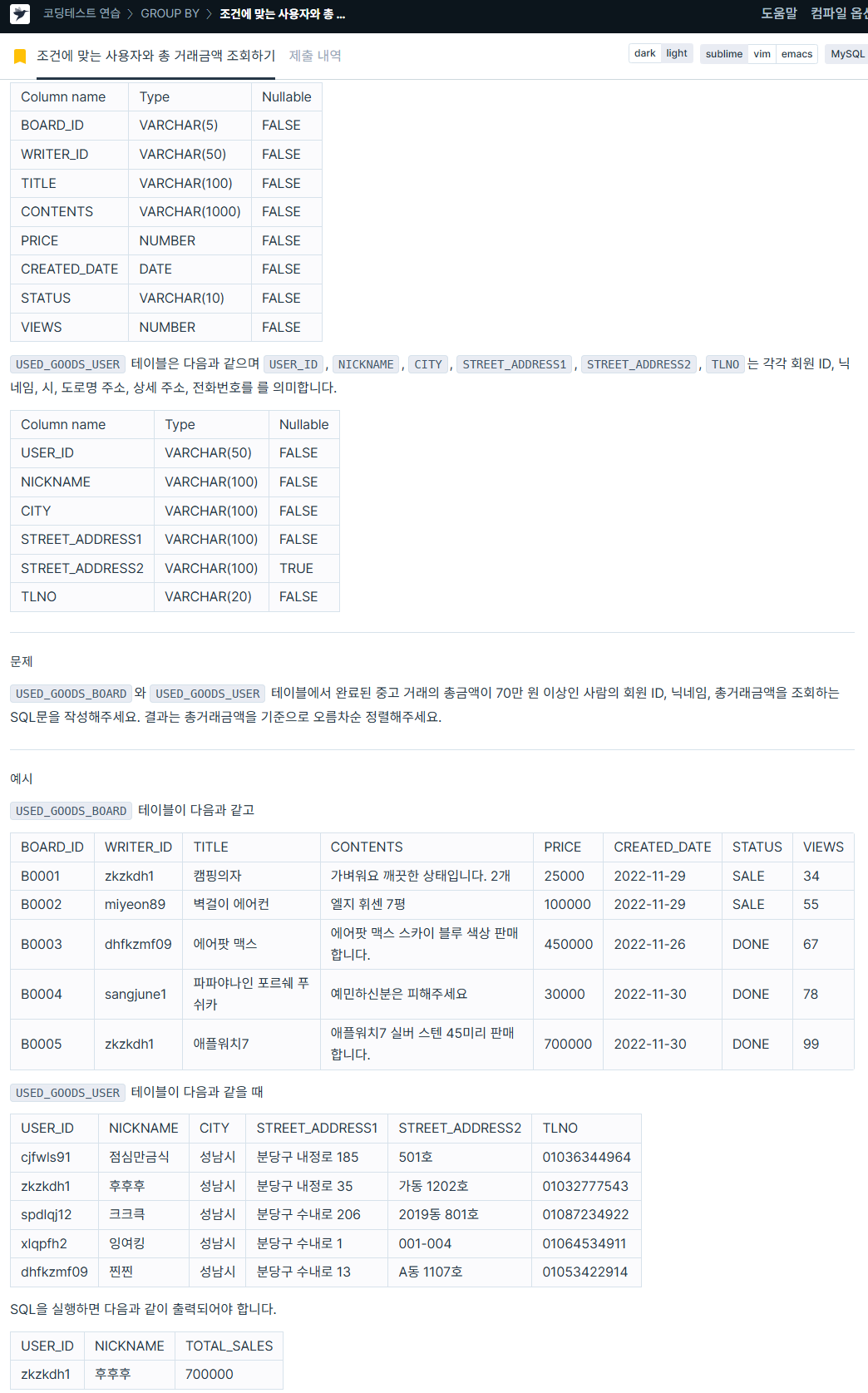
https://school.programmers.co.kr/learn/courses/30/lessons/164668
SELECT b.writer_id AS USER_ID,
u.nickname AS NICKNAME,
b.TOTAL_SALES
FROM ( SELECT writer_id, SUM(price) AS TOTAL_SALES
FROM used_goods_board
WHERE status = 'DONE'
GROUP BY writer_id
HAVING SUM(price) >= 700000) AS b
INNER JOIN (
SELECT user_id, nickname
FROM used_goods_user) AS u
ON b.writer_id = u.user_id
ORDER BY b.TOTAL_SALES ASC;4. 가격대별 상품 개수 구하기
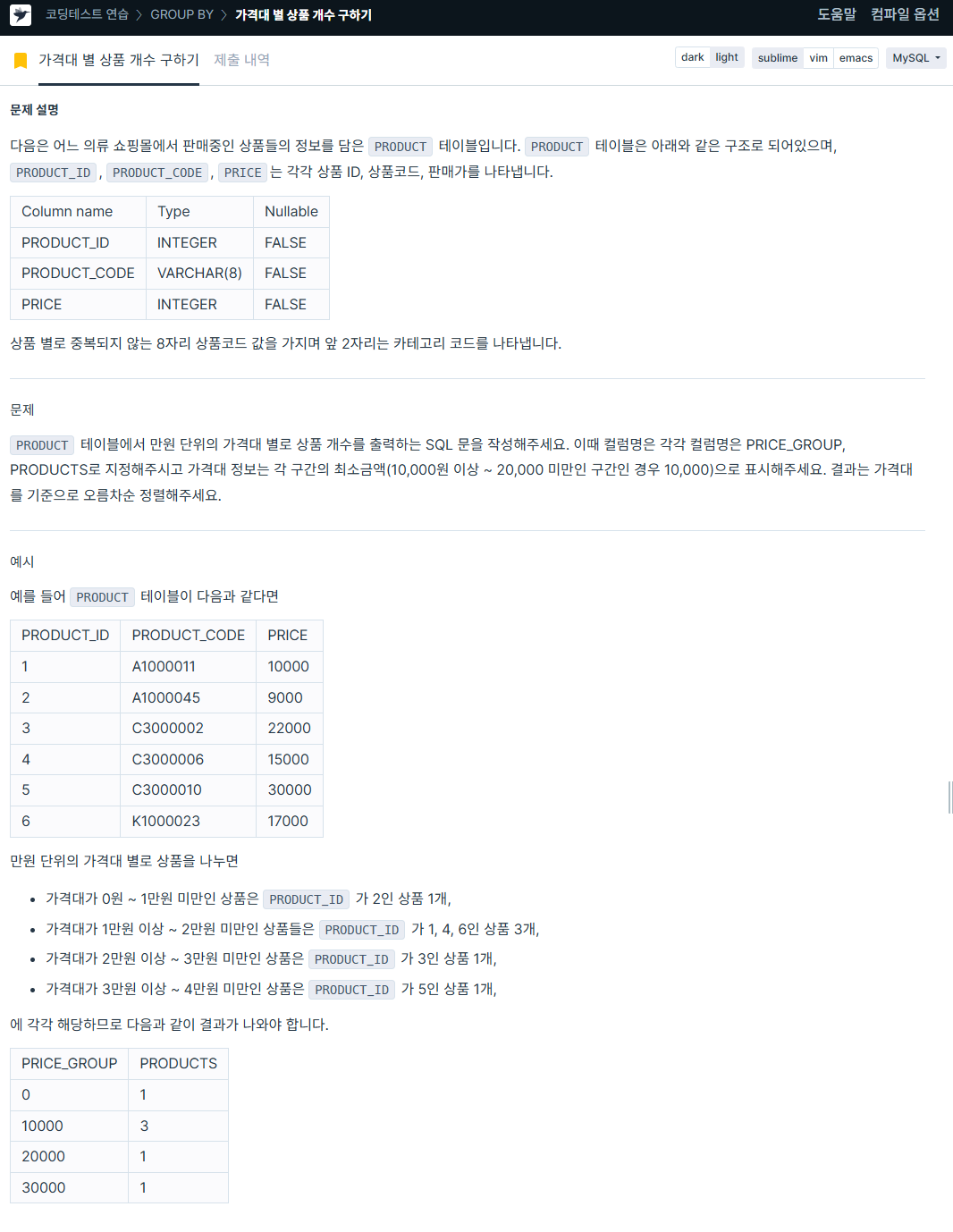
https://school.programmers.co.kr/learn/courses/30/lessons/131530
SELECT CASE WHEN price >=0 AND price <10000 THEN '0'
WHEN price >=10000 AND price <20000 THEN '10000'
WHEN price >=20000 AND price <30000 THEN '20000'
WHEN price >=30000 AND price <40000 THEN '30000'
WHEN price >=40000 AND price <50000 THEN '40000'
WHEN price >=50000 AND price <60000 THEN '50000'
WHEN price >=60000 AND price <70000 THEN '60000'
WHEN price >=70000 AND price <80000 THEN '70000'
ELSE '80000' END AS PRICE_GROUP,
COUNT(*) AS PRODUCTS
FROM product
GROUP BY PRICE_GROUP
ORDER BY PRICE_GROUP ASC;이 쿼리는 좀 더 간단하게 할 수 있을 것 같다.
다시 시도를 해봐야겠다.
5. 3월에 태어난 여성 회원 목록 출력하기
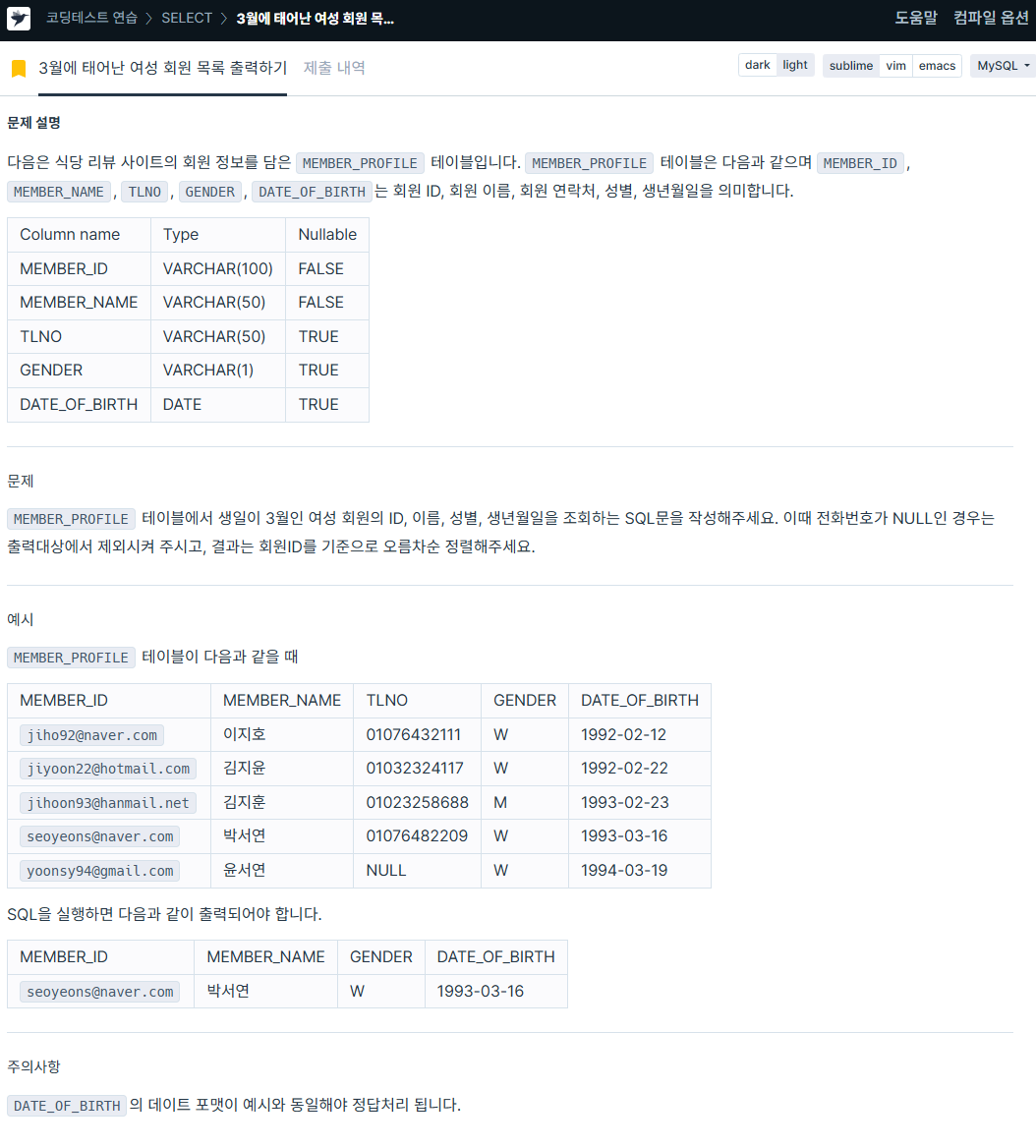
https://school.programmers.co.kr/learn/courses/30/lessons/131120
SELECT MEMBER_ID,
MEMBER_NAME,
GENDER,
DATE_FORMAT(date_of_birth, '%Y-%m-%d') AS DATE_OF_BIRTH
FROM member_profile
WHERE DATE_FORMAT(date_of_birth, '%Y-%m-%d') LIKE '%03%'
AND GENDER = 'W'
AND TLNO IS NOT NULL
ORDER BY MEMBER_ID ASC;🏃자자. 이제 파이썬을 보자.
오늘은 중요한 것들을 배워보았다,
python에서도 join이 있었다... 하지만 join보다 더 중요한 merge가 있어서,
이를 먼저 보고 다음에 join을 보도록 하자.
# 라이브러리 호출
import pandas as pd
import numpy as np
import time
from PIL import Image
# pandas 라이브러리를 활용한 csv 파일 읽기
df = pd.read_csv("product_details.csv") # product_details.csv
df2 = pd.read_csv("customer_details.csv") # customer_details.csv
df3 = pd.read_csv("E-commerece sales data 2024.csv") # E-commerece sales data 2024.csv
# 컬럼명이 같은 경우의 예시를 보여주기 위해 컬럼명을 임의로 변경해 줌
df3['Customer ID']=df3['user id']
merge_df = pd.merge(df2,df3)
#위 코드와 동일한 기능입니다. on 절을 사용할 수 있어요.
merge_df = pd.merge(df2,df3, how='inner', on='Customer ID')
merge를 보게 되면 pandas의 함수 중 하나로, 공통컬럼을 기준으로 테이블을 병합하여, SQL 구문의 JOIN과 가장 유사함을 보여준다.
주요 옵션(파라미터)으로는
- on: 조건 컬럼이 한개인지 여러개인지
- how: 어떤 조인 방식을 사용할 것인지 (inner, outer, left, right)
- left on / right on : 열기준 병합 시 기준으로 할 열의 양측 이름이 다르다면, 각각 어떤 열을 기준으로 할 지 지정합니다.
- sort: 병합 후 인덱스 정렬 여부(True/False)
- suffixes: 중복된 컬럼 이름의 처리
- indicator: True 로 할 경우, 마지막 열에 병합 정보를 출력해줍니다.
가 있다.
그리고 merge를 보게 되면 inner, left 등의 join 유형과, 공통컬럼 기준도 세울 수 있다.
# 기준열 이름이 다를 때
merge_df = pd.merge(df2,df3, how='inner', left_on = 'Customer ID', right_on = 'user id')
# 공통컬럼을 개별로 출력하고 싶을 때
merge_df = pd.merge(df2,df3, how='inner', on='Customer ID', suffixes=('_left','_rihgt'))그리고 기준열 이름이 서로 다를때는 left_on, right_on을 사용해서 하면 되고,
공통컬럼을 개별로 출력하고 싶을 때는 suffixes를 이요하여 중복된 컬럼 이름으로 처리를 한다.
다음으로 join을 보자
join은 인덱스 기준으로 테이블을 병합하는데,
여기서 인덱스는 축을 의미한다.
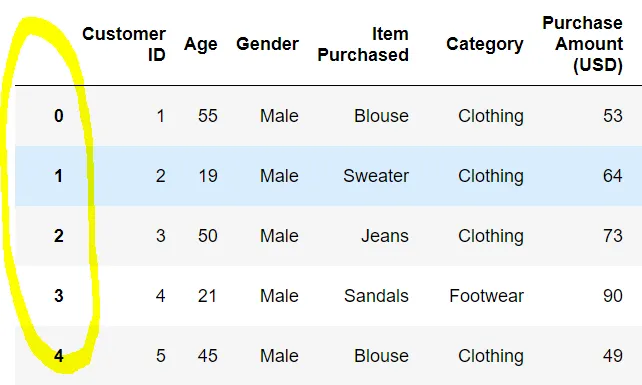
데이터프레임을 보게 되면 노란색 원 영역이 인덱스이다.
주요 옵션으로는
- how: 어떤 조인 방식을 사용할 것인지 (inner, outer, left, right)
- lsuffix / rsuffix: 이름이 같은 컬럼이 있을 경우, 문자열 지정하여 부여
- sort: 인덱스 정렬여부(True / False)
가 있으며,
단순하게 조인을 하고 싶다면,
# 단순 조인
# 이름이 겹치는 컬럼이 없을 때
# 축을 기준으로 합집합
df.join(df3)이와 같은 양식의 코드를 입력하게 되면
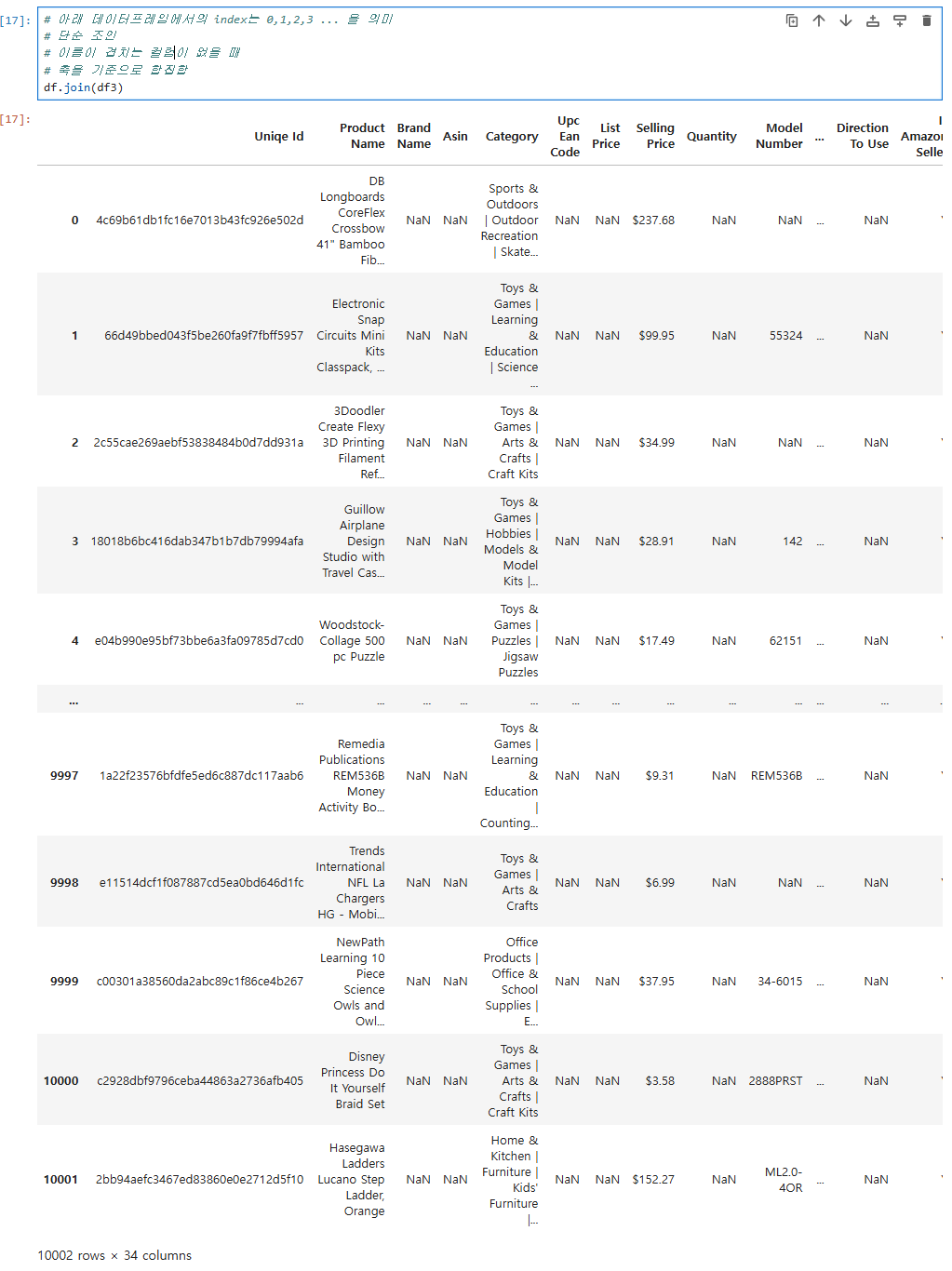
데이터프레임과 같이 축을 기준으로 합집합의 테이블을 보여준다.
# join 방식 설정
df.join(df3, how='right')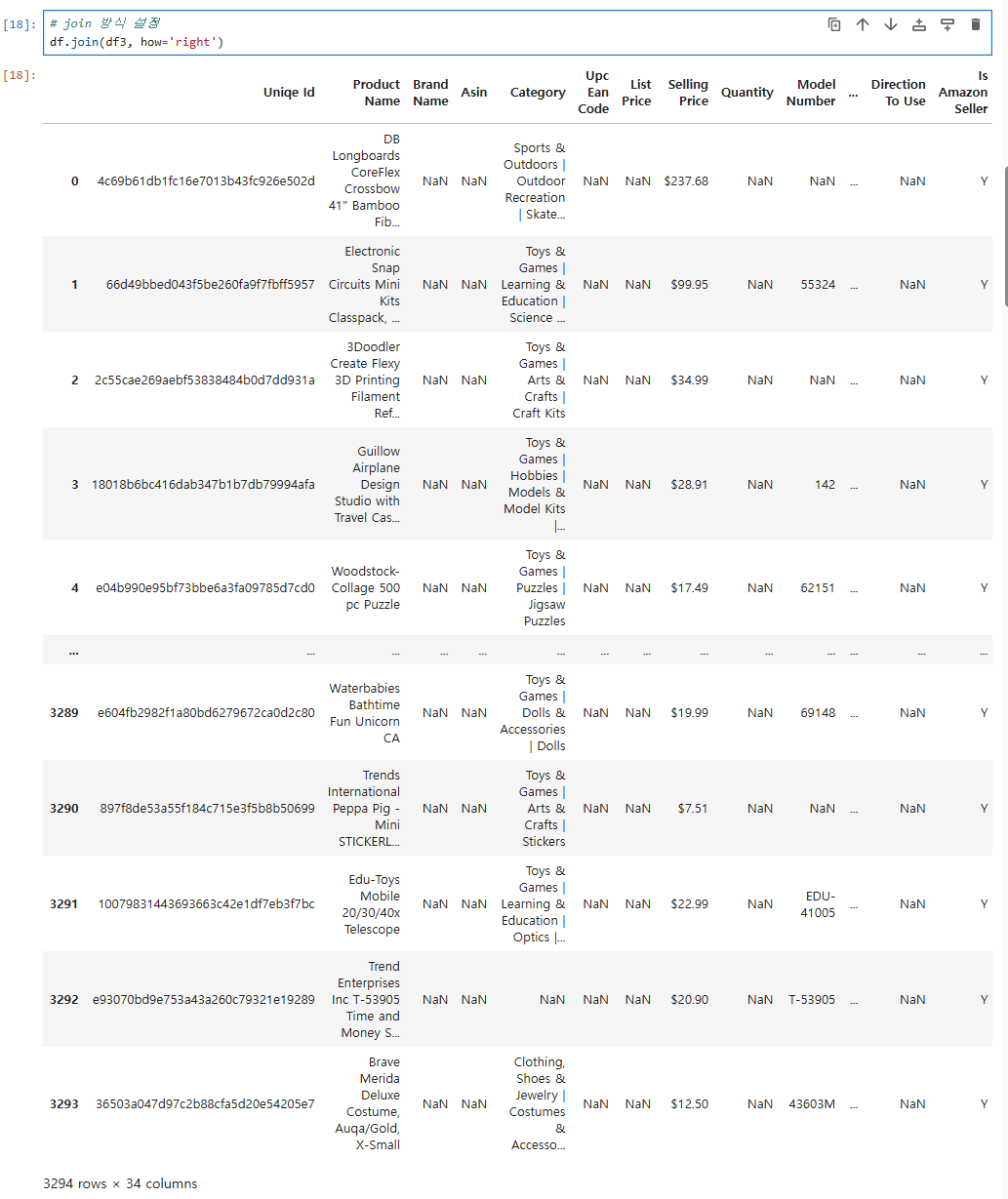
그리고 right, left로 join 방식을 설정할 수 있으며,
# join시 이름이 같은 컬럼이 있을 경우, 옵션으로 설정하여 조인 가능
#df.join(df2)
df.join(df2,how='left', lsuffix='이햐', rsuffix='바보')
join할 때 이름이 같은 컬럼이 있으면, lsuffix, rsuffix을 이용해서 옵션 설정 후 join이 가능하다.
# join 이후, 인덱스 정렬하기
df.join(df2,how='left', lsuffix='1', rsuffix='2', sort=True)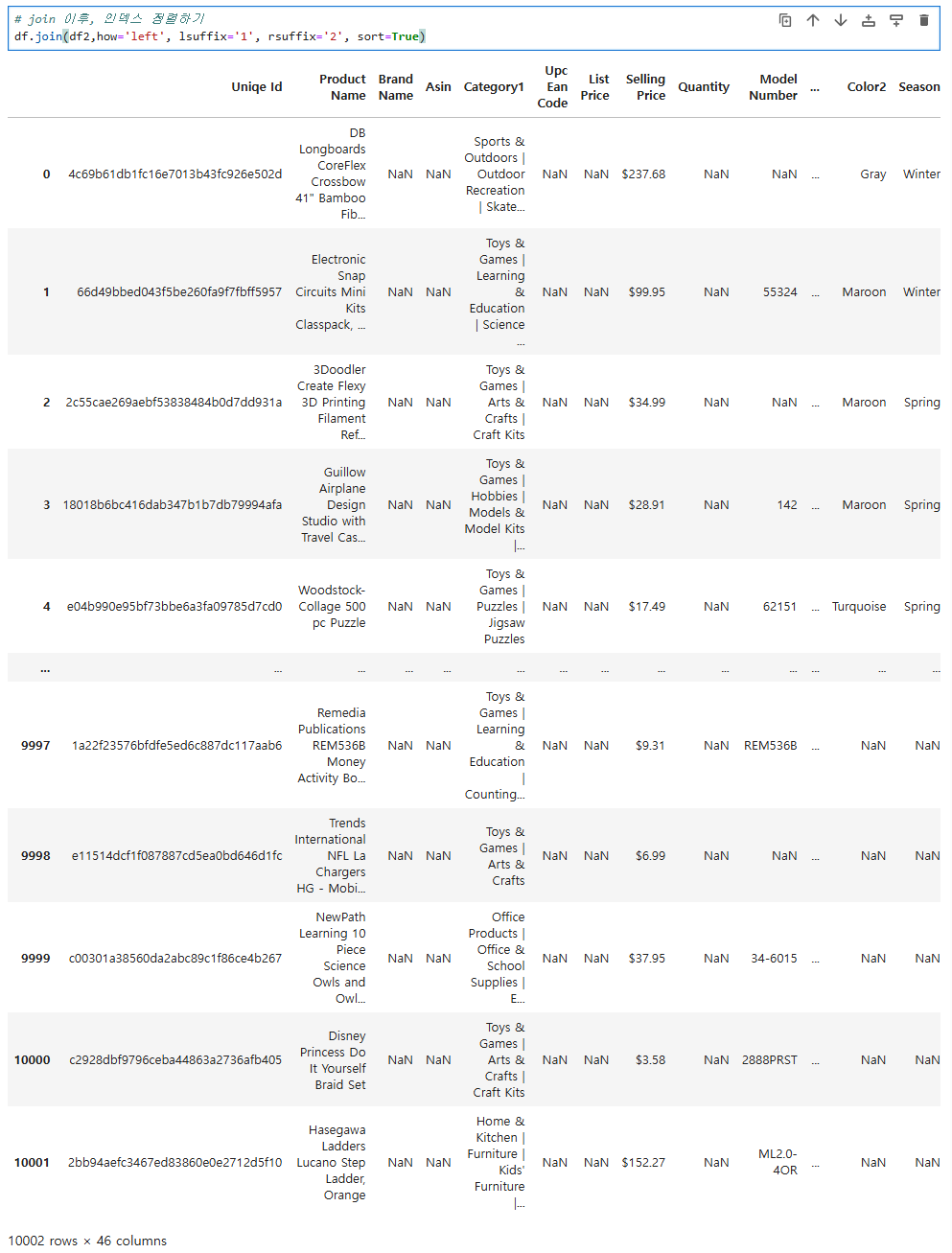
그 다음으로 join 이후 인덱스를 정려하고자 하면,
sort를 이용하여 정렬여부를 True, False로 하여금 정렬한다.
다음으로 concat을 보자.
concat은 여러 데이터프레임 또는 시리즈를 특정 축을 따라 연결하는데 사용한다.
주요 옵션은
- axis: 수직결합인지, 수평결합인지( axis=0: 수직결합(기본값) / axis=1: 수평결합)
- join: 어떤 조인 방식을 사용할 것인지 (inner, outer, left, right)
- join_axes : 조인 축 지정
- keys: 데이터프레임 축이름 지정
- ignore_index=True : 인덱스 재배열
가 있으며,
# 디폴트 값: 수직결합
# axis=1 수평 / axis=0 수직
#ignore_index=True : 인덱스 재배열
#join='inner' : null값(행과 열 등이 맞지 않아 생기는 NaN)을 제외한 교집합
pd.concat([df2, df3])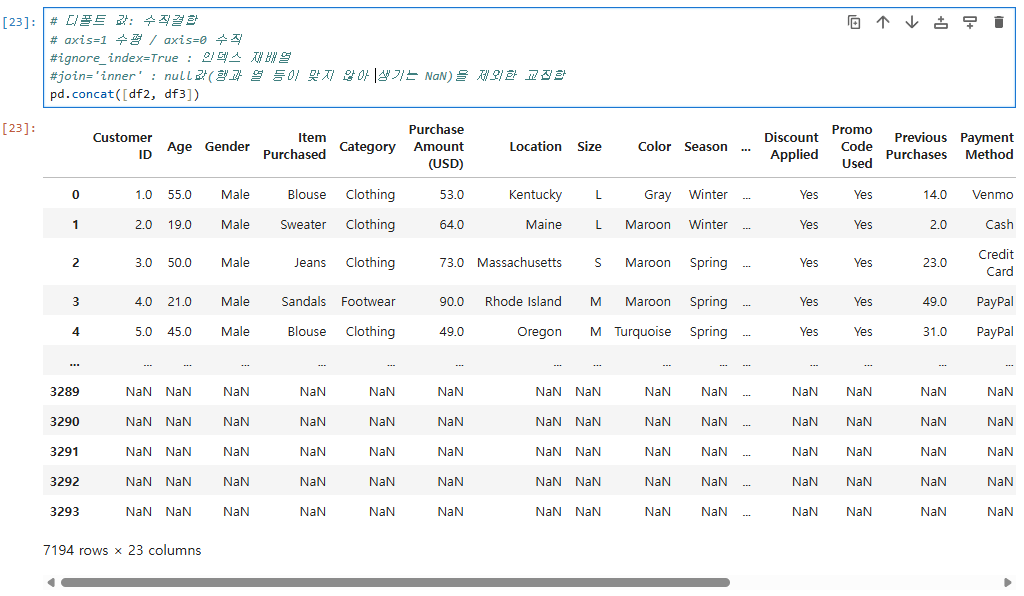
디폴트 값으로는 수직결합을 하며,
axis가 1일때는 수평, 0일때는 수직으로 결합을 한다.
# 세로로 결합
# inner join
pd.concat([df2, df3], axis=0, ignore_index=True, join='inner')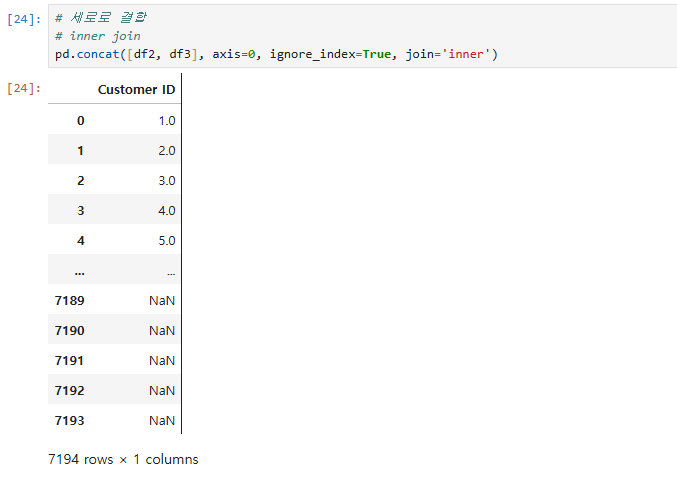
# 가로로 결합
pd.concat([df2, df3], axis=1, ignore_index=True, join='inner')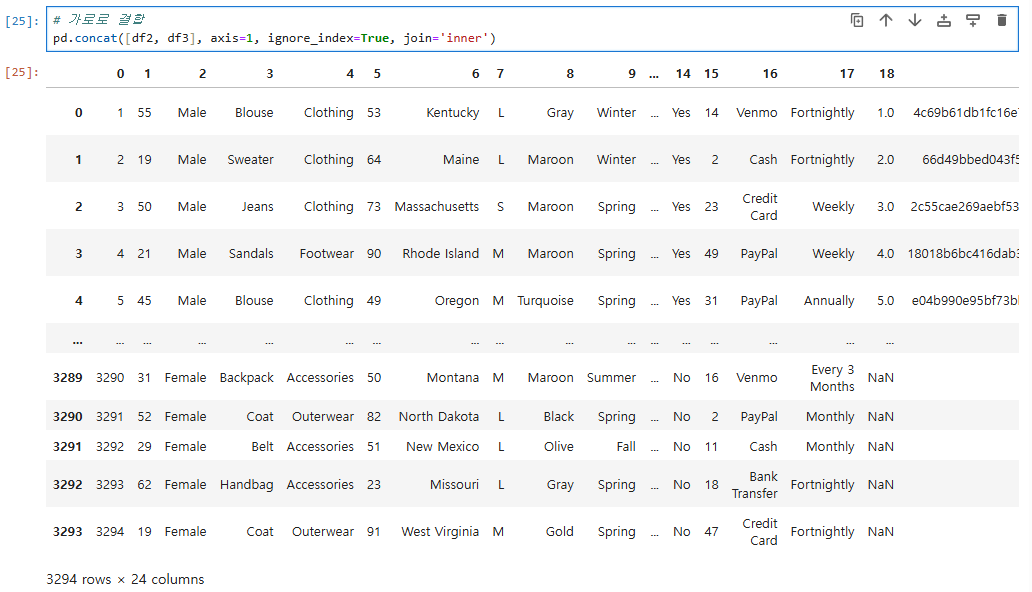
다음으로 자주 쓰이지는 않고, 곧 없어질 append를 알아보자.
append도 데이터프레임에 행을 추가하는 method로, 두 데이터프레임을 행 기준으로 결합한다.
# 기능이 없어질 예정으로 아래와 같이 concat 으로 변경하여 실행해주시면 됩니다.
# 에러가 아닌 경고메시지로, 이를 무시하고 싶다면 아래와 같은 코드를 입력해주시면 됩니다.
# import warnings
# warnings.filterwarnings('ignore')
# 단순 결합, 없는 건 NaN으로 처리되고 결합
# df2 가 df 의 아래로 붙음
df.append(df2)다음으로는 pivot table을 보자.
pivot table은 데이터의 열을 기준으로 피벗테이블로 변환시키는 함수로,
내가 원하는 컬럼들로 새로운 데이터프레임을 만들고, 이를 계산할 수 있다.
# age 라는 축을 기준으로 카테고리별 고객id 카운트
pd.pivot_table(df2, index='Subscription Status', columns='Category', values='Customer ID', aggfunc='count')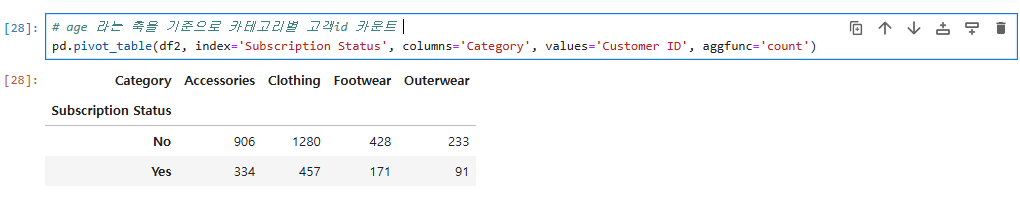
이렇게 age축을 기준으로 카테고리별 고객 id 카운트를 보는 pivot table을 작성할 수 있고,
# age, Category 라는 축을 기준으로 성별 Previous Purchases 최소, 최대값 구하기
pd.pivot_table(df2, index=['Age','Category'],columns='Gender', values='Previous Purchases', aggfunc=['min','max','mean','median'])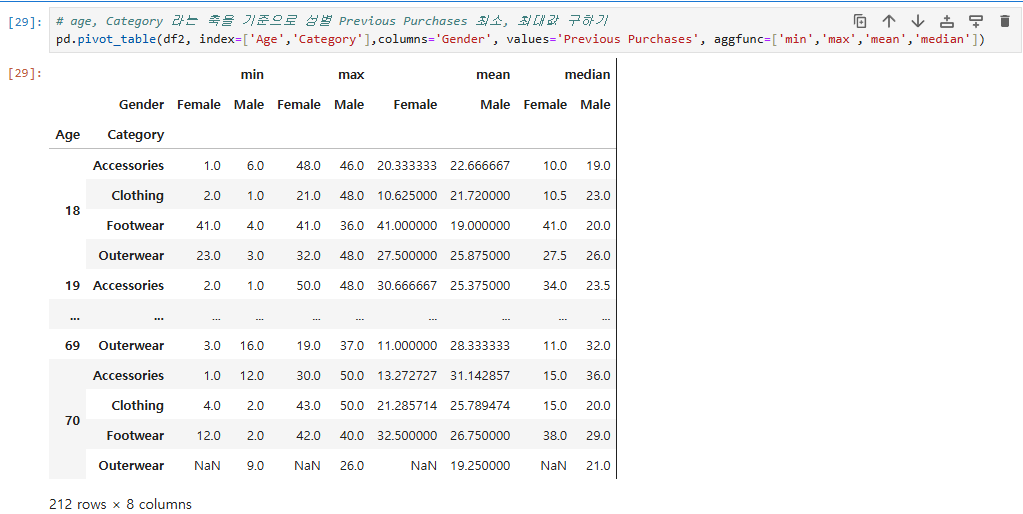
두 개의 축을 기준으로 성별, previous purchases 최소, 최댓값을 구할 수 있다.
# 성별을 축으로 하고, 사이즈, 나이별 고객id 고유하게 카운트
pd.pivot_table(df2, index=['Gender'],columns=['Size','Age'], values='Customer ID', aggfunc='nunique')이 코드도 보게 되면, 성별을 축으로 하고, 사이즈, 나이별 고객 id를 고유하게 카운트 할 수 있다.
그 외 유요한 method들을 보자.
#lambda 함수를 이용한 홀수 출력하기
mylist = [1, 2, 3, 4, 5]
mylist2 = list(filter(lambda x: x % 2 == 1, mylist))
mylist2lambda는 이름이 없는 함수로, 일반적으로 함수를 한 번만 사용하거나,
함수를 인자로 전달해야 하는 경우에 매우 유용하게 사용한다.
#lambda 함수를 이용한 정렬
# sorted 는 python 내장함수입니다.
mylist = ['apple', 'banana', 'cherrycherry','kiwi','orange','watermellon']
mylist2 = sorted(mylist, key=lambda x: len(x))
mylist2예시를 보게 되면, lambda 함수를 이용해서 정렬을 하게 되는 코드이다.
split은 하나의 값으로 묶여있는 데이터를 문자열 기준으로 나눌 때 사용한다.
특정 문자나 패턴으로 나눌 수 있다.
주요 옵션은
- sep: 문자열을 나눌 구분자 기입
- maxsplit: 최대 split 횟수 (디폴트: 모두 다 나눔)
가 있다.
# 예시 문자열 선언
s = "aa.bb.cc.dd.ee.ff.gg"
# '.' 구분자를 기준으로 데이터를 나눔
# 아래 두 코드 결과 동일
s.split('.')
s.split(sep='.')
# '.' 구분자를 기준으로 데이터를 나누고 컬럼으로 받음
# lambda 함수와 결합하여 사용하는 경우
# 7번 반복, a 를 컬럼 구분자로 받아주고, format 함수를 통해 a0, a1, a2 ... 로 표기
# lambda 함수를 통해 '.' 로 구분. 단, len(x.split('.') 즉 7 보다 i 가 작을 때 수행
# 중요
for i in range(i):
df2["a{}".format(i)] = df2['x'].apply(lambda x: x.split('.')[i] if len(x.split('.'))>i else None)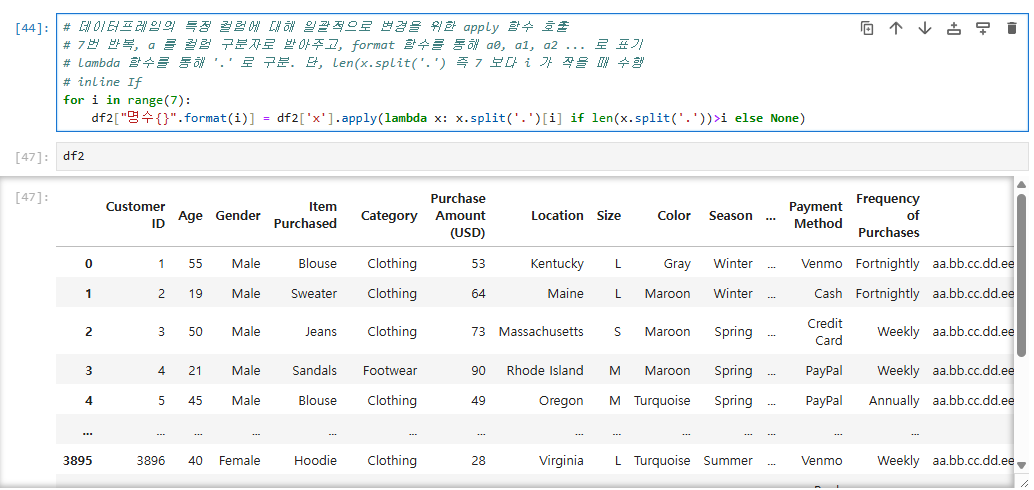
rrule은 dateutill 라이브러리에 속한 함수로,
날짜 데이터를 원하는 기준에 따라 ouput으로 가져올 수 있다.
주요 옵션으로는
- freq : 반복 주기를 나타내는 파라미터로, SECONDLY, MINUTELY, HOURLY, DAILY, WEEKLY, MONTHLY, YEARLY
- dtstart: 반복이 시작하는 날짜와 시간을 나타냅니다.
- interval: 주기적으로 반복되는 간격을 나타냅니다.
- count: 생성할 날짜의 최대 수를 나타냅니다.
- until: 반복이 끝나는 날짜와 시간을 나타냅니다.
# 라이브러리 불러오기
from datetime import datetime
from dateutil.rrule import rrule, WEEKLY
# 시작 날짜, 종료날짜
start_date = datetime(2023, 2, 1)
end_date = datetime(2023, 3, 1)
# 2023-02-01 부터 2023-03-01 까지 strf 사용하여 원하는 데이터 형식으로 출력.
daily_rule = rrule(WEEKLY, dtstart=datetime(2023, 2, 1), until=datetime(2023, 3, 1))
# 생성된 날짜 출력
for date in daily_rule:
print(date.strftime('%Y:%m-%d'))자 데이터 프레임에서 특정 날짜기간에 해당하는 데이터만 슬라이싱을 해보자.
# 2023-02-01 부터 2023-03-01 까지 strf 사용하여 원하는 데이터 형식으로 출력.
from dateutil.rrule import rrule, DAILY
weekly_rule = rrule(DAILY, dtstart=start_date, until=end_date)
# 빈 리스트 생성 후 날짜를 담아주기
a=[]
for date in weekly_rule:
a.append(date.strftime('%Y-%m-%d'))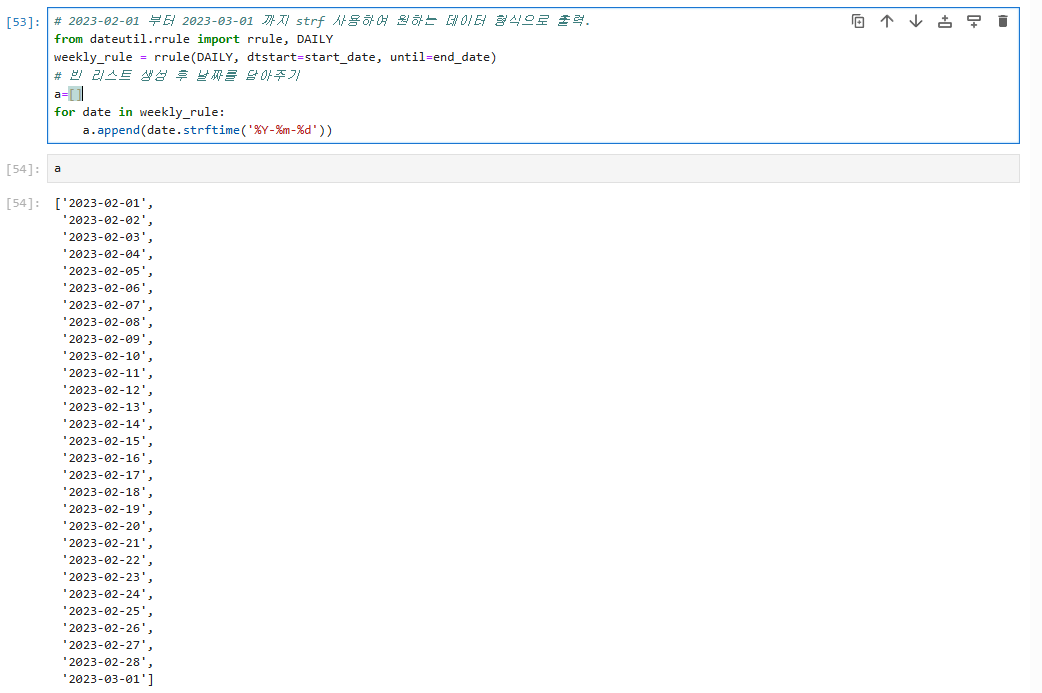
위 코드를 보게 되면 rrule, strftime, append를 이용하여 빈 리스트 생성 후 날짜를 담아준다.
# df3 에 있는 날짜 데이터는 string
# string -> datetimd -> string 의 형태로 변환
# 위에서 받은 리스트에 해당하는 데이터만 필터링하기 위함
df3['Time stamp2'] = pd.to_datetime(df3['Time stamp']).dt.strftime('%Y-%m-%d')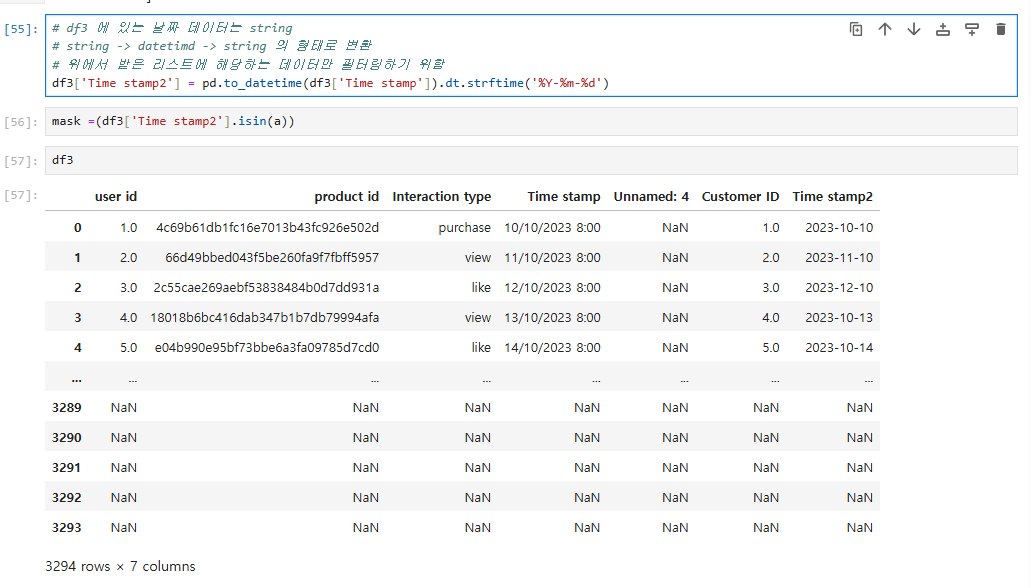
그리고 위에서 받은 리스트에 해당하는 데이터만 필터랑 하기 위해,
위 코드를 이용해서 진행을 한다.
3. 학습하며 겪었던 문제점 & 에러
🖥️프로그래머스 문제를 풀어보자.
코드 카타로 대체!
🖥️백준 문제도 보자.
낼 풀게요..
4. 내일 학습 할 것은 무엇인지
SQLD도 끝났으니,
강의에 좀 더 집중해보자.



