GPT_3
인터넷의 모든글을 통해 학습을 시킨 모델이며, transformer의 decoder부분을 사용했다.
pretrained language model인데 이는 레이블이 없는 많은 데이터를 비지도 학습 방법으로 학습해서 모델이 언어를 이해할 수 있도록 한 후 특정 task에 적용해서 좋은 성능을 내는 방법이다.
Transformer
이때 transformer모델은 RNN의 처음단어부터 끝단어까지 순차적으로 연산하며 상태값을 전달하는 방법이 속도를 보완하기 위한 모델이다.
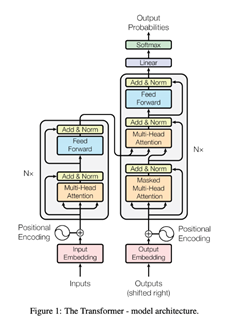
위에 사진은 트랜스포머의 구조이다.
Multi-Head Attention을 사용하는데 이는 단어와 단어 사이의 상관관계를 나타내는 가중치를 말하는 attention들의 합으로 나타낸다.
좀 더 자세히 설명해보자면,
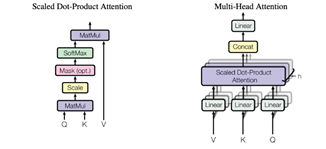
단어 A에 대해서 단어 B가 주는 가중치를 Q(Query), K(key), V(value)로 표현할 수 있다.
이때, Q는 단어 A를 나타내며, K는 단어 B, V는 두 단어 사이의에 가중치를 표현한다.
이를 행렬곱을 통해 연산하여 입력값과 같은 차원의 출력값을 출력한다.
이를 모든 단어에 대해 수행하는데, 이때 모든 단어를 병렬로 처리하여 시간을 매우 단축시킨다.
GPT 구조
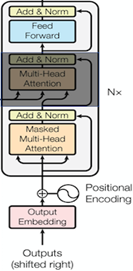
GPT는 이 부분에서 decoder만을 사용하는데 encoder로부터 값을 받는 부분을 제외하고 사용한다.
이전 실행결과와 입력 문장을 이용하여 다음 단어를 예측하는 방식으로 작동된다.
GPT-3 주요 단어
GPT-3의 주요 단어라고 하면 few-shot learning, fine-tuning 선택할 수 있을 것 같다.

3가지의 learning방법이 있는데
zero-shot은 입력값없이 값을 예측하는 것이고,
one-shot은 하나의 입력값으로 예측하는 것
few-shot은 적은 양의 데이터로 예측하는 것이다.
fine-tuning 이미 학습된 모델을 사용하기 위해서는 우리에 입맛에 맞게 중간 파라미터나 중간 층의 수정이 필요하다.
하지만 이 모델의 경우 데이터만 넣어주면 그 데이터에 맞게 원하는 출력값을 얻을 수 있다.
(하지만 fine-tuning을 하면 더 좋은 결과가 나올수 있다고...)
GPT-3는 아직 데모 버전이라 우리가 사용할 순 없지만, 베타버전을 받아서 사용한 사람들은 엄청난 효과에 놀라고 있다.
GPT-3 예시
그 예시들은 내가 설명한것보다 좋은 사이트가 있어 소개한다.
[GPT_3 사례] https://gptcrush.com/
GPT-3 한계
하지만 이는 인터넷의 글들을 이용하여 학습했기 때문에 문제점이 존재한다.
예를 들어 종교적인 문제나 차별적인 발언의 문제가 발생했다.
이를 극복하기 위해서는 모델에게 도덕적이고 올바른 문장만을 학습해야하는데, 이를 구분해 내는 작업을 하는 모델이 나오면 좋겠다.
느낀점
수많은 데이터와 엄청난 학습시간이 필요했겠지만, 이를 통해 자연어 처리분야가 매우 발전했다는 것을 알 수 있었다.
앞으로 더 발전해서 이런 모델의 한국어 버전도 나왔으면 좋겠다.
