Seq2Seq prediction
훈련때와 다르게 decoder_input이 없다.
그래서 decoder를 문장 대신 단어 하나로 생각하도록한다.
즉, encoder의 마지막 은닉/쉘 상태 값과 <'start'>를 입력값으로 LSTM을 하나만 실행한다.
이때 나온 단어들의 확률값과 은닉/쉘 상태값을 다시 넣어준다.
이를 <'end'>가 나올때까지 반복.
각각의 가장 높은 확률의 단어를 모아서 문장으로 예측을 한다.
Booting
여러개의 분류기가 순차적으로 학습을 하는데, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에 가중치를 부여하면서 학습과 예측 진행
GradientBoosting
여러개의 결정트리를 묶어서 만든 모델이다.
이전 트리의 오차를 보완하는 방식으로 순차적으로 트리를 만든다.
사전 가지치기 방법을 사용하며 학습시간은 좀 길수 있으나, 예측속도가 빠르다.
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(max_depth=1, learning_rate=0.01, n_estimators=1000, random_state=42)
model.fit(X_train, y_train)
# 평가
print(model.score(X_train, y_train), model.score(X_test, y_test))결정트리를 묶어서 사용하는 모델이다 보니 따로 모델을 지정해주지 않고, GradientBoostingClassifier모델만 생성한다.
과적합이 발생할 수 있으며 이는 트리의 최대 깊이를 줄여 사전 가지치기를 강하게 하거나 학습률을 낮춰서 막을 수 있다.
AdaBoost(Adaptive Boosting)
이전의 잘못 분류한 샘플에 가중치를 높여서 학습하는 방법이다.(순차적 진행)
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 평가
model.score(X_train, y_train), model.score(X_test, y_test)트리의 개수와 학습률을 지정할 수 있으며 다른 모델과 같은 방법으로 모델을 생성한다.
이 분류기는 깊이가 1인 결정트리를 사용하므로 각 트리의 결정경계는 직선이 하나이다. 하지만 boosting결과는 꽤 좋은 편이다.
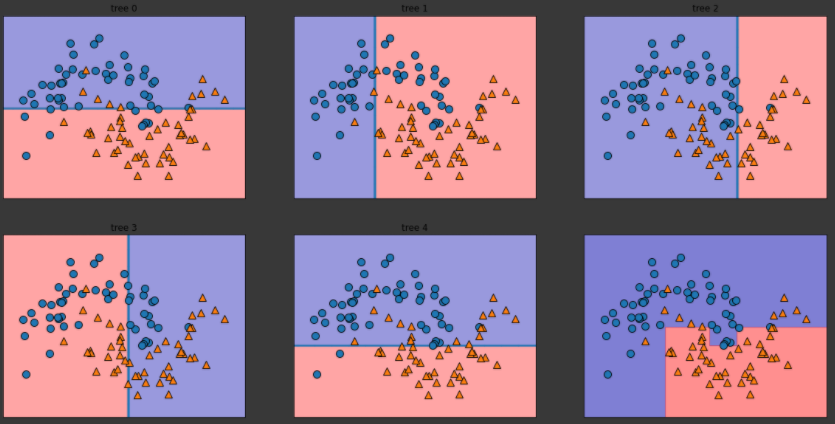
XGBoost(extreme gradient boosting)
GBM을 개선하여 병렬수행이나 다양한 기능으로 속도를 높인 방법이다.
from xgboost import XGBClassifier
model = XGBClassifier(n_estimators=1000, learning_rate=0.1, max_depth=3, random_state=42)
model.fit(X_train, y_train)
# 평가
print(model.score(X_train, y_train), model.score(X_test, y_test))LightGBM
학습시간과 메모리 사용량을 줄인 방법이다. 하지만 과적합 발생이 쉽고, 예측은 큰 차이를 보이지 않는다.
균형 트리분할 방식이 아닌 리프중심 트리분할방식을 사용한다.
즉, 깊이를 줄이기 위한 방식이 아닌 비대칭적이고 깊이가 깊어진 방법을 사용하여 예측 오류 손실을 최소화할 수 있다.
conda install -c conda-forge lightbgm
아나콘다를 이용하여 라이브러리를 설치하고 사용했다.
from lightgbm import LGBMClassifier
model = LGBMClassifier(n_estimators=400, learning_rate=0.1, max_depth=3, random_state=42)
model.fit(X_train, y_train)
# 평가
print("훈련 세트 정확도 : {:.3f}".format(model.score(X_train, y_train)))
print("테스트 세트 정확도 : {:.3f}".format(model.score(X_test, y_test)))Django
서버 역할을 할 수 있는 웹프레임워크이며 파이썬을 사용한다.
Django's 장점
1. 대부분이 라이브러리로 구현되어있어 개발이 간편함
2. 보안을 알아서 처리해주어 매우 안전하다
3. CRUD가 편하게 구현가능하다.
4. 스케일을 키우기에 좋다.
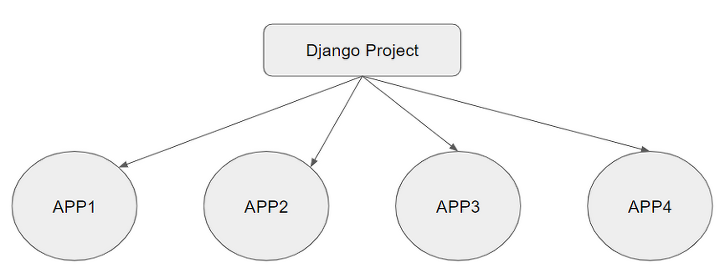
출처 : https://dogfighterkor.tistory.com/4
장고는 하나의 프로젝트 안에 여러개의 앱으로 구성되어 있다.
앱은 큰 분류의 기능을 담당하고 있는 것이다.
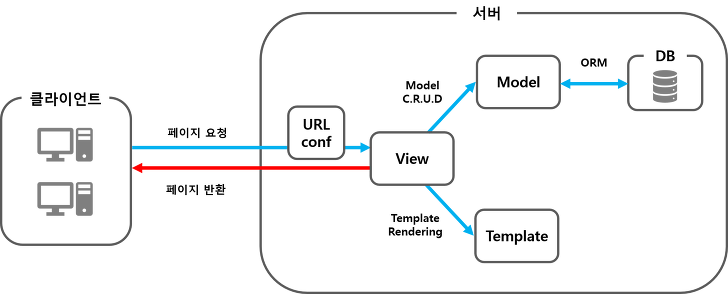
출처 : https://velog.io/@jcinsh/Django-%EC%9E%A5%EA%B3%A0-%ED%94%84%EB%A0%88%EC%9E%84%EC%9B%8C%ED%81%AC-%EC%9D%B4%ED%95%B4
장고의 구조는 위에 그림과 같다.
클라이언트가 요청한 url을 urls.py에서 찾는다. 여기서 찾은 내용과 연결된 views.py에 선언된 함수를 실행시킨다.
실행결과(응답)을 templates에 담은 html 파일이나 models.py.의 데이터를 클라이언트에게 전달한다.
느낀점
- 난 어디로 취직을 하는게 좋을까? 코딩테스트에 대해 공부를 열심히 해야겠다
- 내용이 어렵기도 하면서 흥미롭기도 한데 뭐가 나한테 맞는지 아직 감이 잘 안온다.
가고싶은 회사를 먼저 정해야하는건지 내가 원하는 내용에 맞는 회사를 가야하는지 모르겠다. - 장마가 어서 끝나서 비가 그만왔으면 좋겠다... 무슨 우기도 아니고 이렇게 비가 많이 오는지...
