계획한일
- 정처기 2번째 책 나머지 보기
- 오늘 배운 내용 정리
- vscode python환경구축
오늘 수업 정리
1교시 : 시험 리뷰_빅데이터 분석
붓꽃데이터를 이용하여 SepalLength를 가로축으로, PetalLength를 세로축으로 하고, Species별로 색이 다르게 나오는 산점도 그리기.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('data_iris.csv')
df_setosa = df[df.Species == 'setosa']
df_virginica = df[df.Species == 'virginica']
df_versicolor = df[df.Species == 'versicolor']
plt.scatter(df_setosa['SepalLength'], df_setosa['PetalLength'], c='g', marker='o', alpha=0.5, label='setosa')
plt.scatter(df_virginica['SepalLength'], df_virginica['PetalLength'], c='r', marker='x', alpha=0.5, label='verginica')
plt.scatter(df_versicolor['SepalLength'], df_versicolor['PetalLength'],c='b', marker='^', alpha=0.5, label='versicolor')
plt.xlabel('SepalLength')
plt.ylabel("PetalLength")
plt.legend()
plt.show()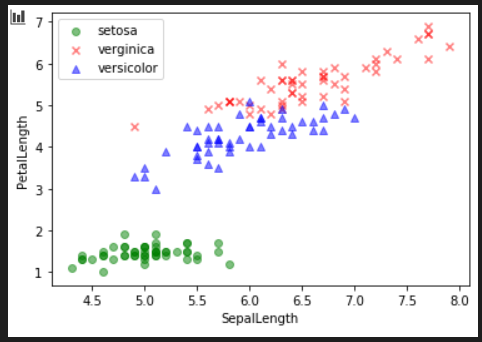
2교시 : 단층퍼셉트론_딥러닝
단층 퍼셉트론 : 일련의 퍼셉트론을 한줄로 배치하여 입력벡터 하나로부터 출력 벡터 하나를 단번에 얻어내는 아주 간단한 신경망 구조이다.
출력의 개수 = 퍼셉트론의 수
출력값은 각 입력값의 가중치와 편향을 함께 계산한다.
파라미터(= 모델 파라미터) : 학습과정 중 끊임없이 변경되어가면서 퍼셉트론의 동작 특성을 결정하는 값(편향, 가중치..)
텐서 : 다차원 숫자 배열. 0차원은 스칼라, 1차원은 벡터, 2차원은 행렬.
같은 문제일지라도 텐서를 이용하여 처리하는 편이 프로그램도 간단하고 처리속도도 빠르다.
딥러닝에서는 텐서연산을 사용하는 것이 매우 중요!
미니배치 : 모든 학습데이터를 잘라서 간단하게 처리하는 방식. 데이터의 효율성을 높여주며, 개별데이터의 특징을 무시하지 않으면서 특징에 너무 휘둘리지 않게 사용가능하여 매우 유용하다.
에폭 : 학습 파라미터 전체에 대한 한차례 처리 즉, 미니배치에서 자른 데이터 하나를 처리하는 과정.
하이퍼 파라미터 : 학습과정에서 변경되지 않으면서 학습결과나 신경망구조에 영향을 미치는 요인.
(에폭, 미니배치의 크기...)
알고리즘 출력의 3가지 방법
- 회귀분석 : 어떠한 특징 값 하나를 숫자로 추정하여 출력.
- 이진판단 : 두개의 값 중 하나를 선택하여 출력.
- 선택분류 : 몇가지의 항목 중 하나를 골라 출력.
=> 이를 반복하거나 혼합하여 출력된다.
3교시 : 자연어처리 개론_자연어처리
natural_join : 같은 키를 찾아서 알아서 조인을 한다. innerjoin과 비슷하지만 직접 키를 지정하지 않는 다는 차이가 있다.
select * from takes natural join course
select * from takes inner join course on takes.course_id == course.course_id- 자연어 처리는 하위 분야가 매우 많고 이 분야들마다 원리가 다르기 때문에 모든 분야를 통찰하기에는 시간이 매우 많이 소요된다.
- 자연어 처리는 언어별로 의미를 형성하는 과정이 다르는 등의 이유로 한계가 존재하며, 다른 분야에 비해 발전 속도가 느리다
<자연어 처리 과정>
1. 문장에서 의미를 가지는 단어들을 추출하는 전처리 과정
2. 추출한 단어들을 의미가 비슷한 것끼리 가까운 위치에 배치.
3. 배치된 단어들을 바탕으로 의미를 찾거나 분류 진행.
4. 분류된 결과를 통해 결과 도출.
4교시 : 시험 리뷰_머신러닝
자리수를 맞추기 위해 사용하는 메소드 zfill()
import random
num = str(random.randint(0, 99)).zfill(2) # 03, 45, 02, 67....한자리가 생성될 경우 앞에 0을 붙여서 2자리로 바꿔준다. 문자열로 생성된다.
<파이썬 유닛 테스트>
import unittest
class AccountTest(unittest.TestCase):
def setUp(self): # 사전준비작업, 각 테스트의 초기화
Account.account_count = 0
def tearDown(self): # 사후처리, 각 테스트의 clean up
pass
def test_withdraw(self):
kim = Account("김민수", 100)
kim.deposit(100)
kim.withdraw(90)
self.assertEqual(kim.balance, 110)
# Jupyter에서 테스트 메서드들의 실행
# 이유: Jupyter의 커널 명이 sys.argv 의 첫 파라미터로 unittest.main에 절달되기 때문
# import sys
# print(sys.argv)
if __name__ == '__main__':
unittest.main(argv=['first-arg-is-ignored'], exit=False)작성한 클래스가 잘돌아가는지 확인하는 데 사용하는 클래스. 기본 제공 클래스이며, 결과를 확인하여 정확한 결과인지 아닌지를 OK, FAILED라고 출력해준다.
unittest 공식문서
<추상클래스>
추상 베이스 클래스인 abc 활용 예시
from abc import *
class Notifier(metclass=ABCMeta): # 추상클래스 정의
@abstractmethod
def notify(self, event_data): #추상메소드를 정의. 상속받는 클래스에서 정의 필요
pass
class SMSNotifier(Notifier):
def notifier(self, event_data):
print(event_data, 'received...')
class EmailNotifier(Notifier): # 에러 발생. Notify메소드 정의필요
def notify_test(self, event_data):
print(event_data, 'received...')추상클래스를 지정해주는 클래스로, 기본 제공된다. 추상클래스를 상속받은 클래스는 추상메소드 정의가 필수적이다.
ABC-추상 베이스 클래스 공식 문서
import pandas as pd
data = pd.read_csv('Traffic_Accident_2017.csv', encoding='euc-kr')
data.T데이터프레임의 데이터를 그냥 출력시 header가 상단에 가로로 위치한다. 하지만 T라는 인자를 붙여 출력하면 전치행렬을 출력하며, 이는 헤더가 세로로 가장 왼쪽에 출력된다.
5교시 : 알고리즘 정의_알고리즘 & 클라우드
알고리즘이란 특정 목적을 이루기 위한 유한한 동작들(의 묶음)이다.
6교시 : 웹개론_웹 애플리케이션
웹은 모든 것이 REQUEST와 RESPONSE로 이루어져 있다.
GET : 서버에 있는 내용을 가져오길 요청하는 것.
POST : 서버에 새로운 내용을 등록하는 것(실제로 많이 사용한다.)
- 200 : 요청에 성공
- 300 : 요청은 성공했으나, 다른 페이지로 떨어짐
- 400 : 클라이언트가 잘못된 요청.
- 500 : 서버가 요청을 수행할 수 없는 상태.
느낀점
생각보다 내용이 어렵다... 특히 딥러닝 부분이 어렵다.
자연어 처리 강사님은 비닮았다. ㅎㅎ
