이번주는 개인적인 일도 생기고 정신도 없는 한주였던거 같다.... 주 초에 복습을 하지 못하니 뒤에 내용을 이해하는데 어려움이 있었다.
이번주는 집에서 들었는데, 여기 있으니 확실히 공부를 덜하는....
👩💻이번주 학습 내용
(ㄴ이모지 처음 써봄 ㅎㅎ)
딥러닝
소프트맥스 함수
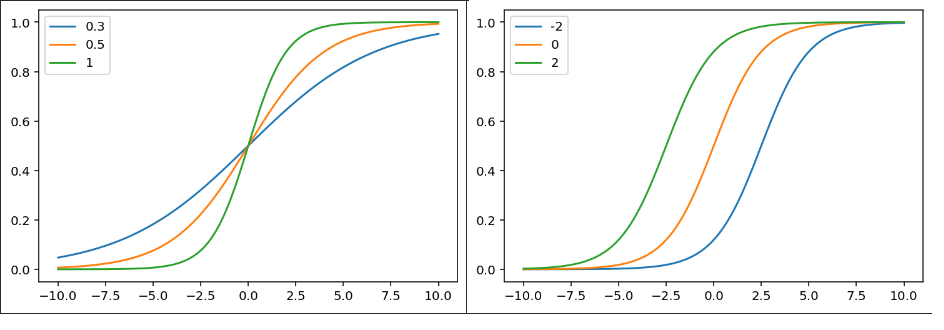
로짓값 벡터를 확률분포 벡터로 변환해주는 비선형 함수
일련의 입력 벡터에 대한 그에 해당하는 확률형 출력 벡터를 출력하는 함수이다.
즉, 이진분류를 위해 출력되는 값을 0과 1사이의 값으로 바꿔주는 함수 중 하나이다.
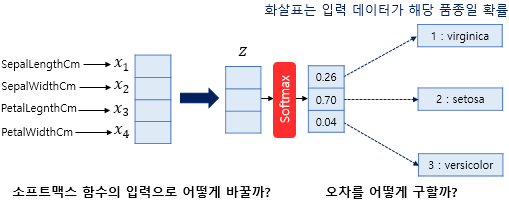
위에 사진과 같이 소프트 맥스 함수를 거치면 0과 1사이의 값이 출력되며 데이터 분류가 가능해진다.
다층 퍼셉트론
중간층인 은닉층이 하나 이상있는 신경망.
다수의 퍼셉트론 계층들을 순서에 따라 배치하여 입력층부터 중간층을 거쳐 출력벡터를 산출한다.
다층 퍼셉트론도 비선형 활성화 함수를 사용하는데, 이는 출력값이 아닌 은닉층에서 출력된 은닉벡터의 값에 함수를 적용한다.
이를 사용하는 이유는 출력값이 단순 선형으로 나오는데 이를 좀 더 복잡하게 출력하기 위해 사용한다.
은닉계층이 무조건 많다고 좋은 것은 아니다.
문제의 규모, 데이터의 양 등을 종합적으로 고려하여 다양한 실험과 축적된 경험을 통해 결정해야한다.
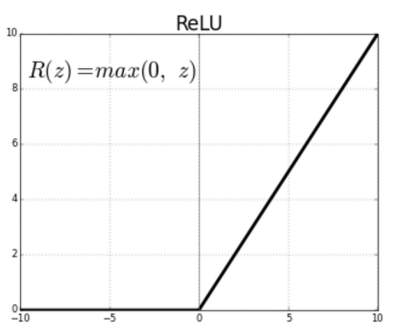
ReLU 함수
기울기 소멸 문제를 해결하기 위해 사용.
음수일 경우 기울기가 0이고 양수일 경우 기울기가 1인 함수이다.
0의 경우 미분이 불능하지만, 이를 강제로 0으로 지정해주었다.
자연어 처리
단어 임베딩
단어를 벡터로 표현한다. 즉, 단어의 의미를 벡터화하는 것이다.
크게 Word2Vector, Glove 2가지 방법을 사용한다.
그 중 Word2Vector에는 CBOW, skip grap방식이 있다.
- CBOW : 주변 단어를 이용하여 중심단어를 예측하는 방법.
- skip grap : 중심단어를 이용하여 주변단어를 예측하는 방법.
Glove
특정 단어가 주어졌을때, 임베딩된 두 단어벡터의 내적이 두 단어의 동시등장확률 간 비가 되도록 임베딩하는 것이다.
즉, 임베딩을 거친 단어 중 2개와 원하는 단어와의 내적을 구한다. 이 구한 값의 비가 두 단어가 동시에 등장할 확률의 비가 같도록 하는 것이다.
머신러닝
규제선형모델(Ridge, Lasso)
선형모델을 사용하다보면 과적합이 발생한다. 이를 방지하기 위해 모델 자체에 규제를 주는 방법이다.
규제의 정도에 따라 L1, L2로 나뉜다. Ridge는 L2규제인데 Lasso는 L1규제로 더 강한 규제이다.
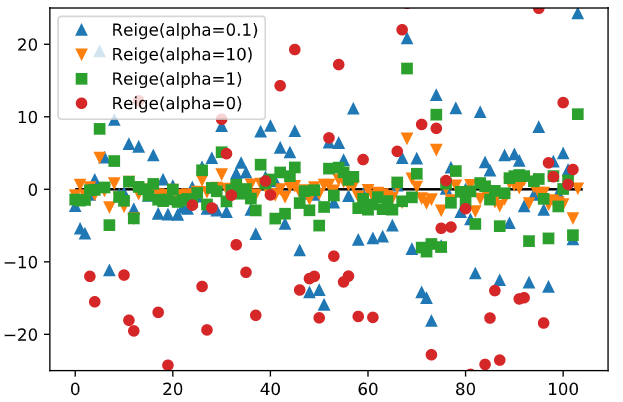
- Ridge는 alpha인자를 통해 규제정도를 정한다. alpha값이 작을수록 가중치값이 넓게 퍼진형태를 보인다.
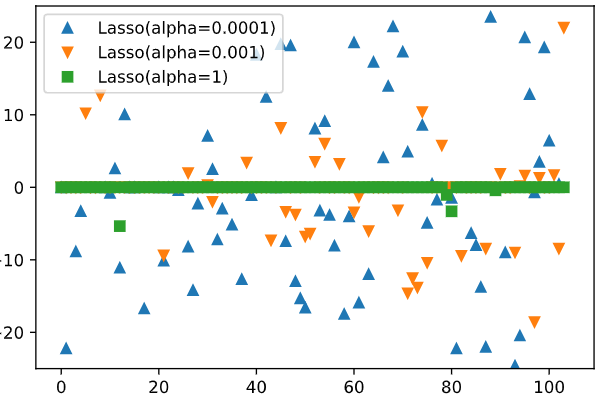
- Lasso도 alpha값으로 규제정도를 정한다. 하지만 규제가 더 강한 Lasso는 alpha값에 따라 사용하는 특성의 수도 정해진다.
LinearClassifier
SGDClassifier모델을 사용한다. 이는 경사하강법 최적화 할고리즘을 사용하여 선형 모델을 작성하는 방법이다.이 또한 alpha값으로 규제정도를 제한한다. alpha값이 클수록 규제가 더 강력해진다.
또 다른 모델로는 Logisitic Regression모델을 사용한다. 이는 이중분류뿐만아니라 다중분류에도 사용할 수 있는 모델이다.
간단하고, 파라미터 수가 적으며 빠르게 예측이 가능하여 많이 사용되고 있다.
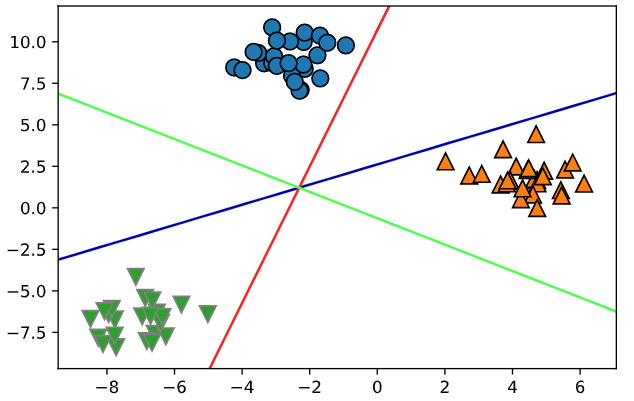
왼쪽 사진은 가중치를 변경하여 여러번 출력한 모습이고, 오른쪽은 편향을 변경하여 출력한 모습이다.
가중치 값이 증가할수록 경사가 가파라지고, 편향은 증가할 수록 왼쪽으로 이동하는 것을 알수 있다.
C값으로 규제를 정하는데 alpha값과 달리 C값이 작아지면 영향력이 떨어지고, 이로인해 스코어 점수가 낮아질수 있다.
다중 분류시에는 정확도가 너무 높게 나오면 의심을 하고 시각화를 통해 확인해라. 영향을 많이 주는 특성들만을 이용해서 시각화하면 더 쉽게 볼 수 있다.
웹
Web Scrapping(Crawling)
버전관리 등을 위해 pipenv라는 가상환경을 사용했다.
pip가 설치되어있는 환경에서 pipenv를 설치하고 내가 원하는 폴더에 가상환경을 실행시킨다.
거기서 requests, bs4를 설치하고 이를 통해 크롤링을 진행했다.
네이버 뉴스 기사제목과 링크를 가져오는 것을 진행했다.
크롤링하고자하는 주소로 request를 보낸후, 받은 내용 중 내가 원하는 정보가 있는 태그까지 select를 이용하여 이동했다.
(이번주는 여기까지..)
