
CNN
입력값이 많은 이미지에 대해 파라미터 수를 줄이고, 좀 더 빠르고 정확한 방법으로 학습할 수 있도록 만들어진 신경망.
중간층인 은닉층에 convolution, pooling계층이 번갈이 존재한다. 이를 통해 이미지의 픽셀. 즉 입력값이 줄어들기도 한다.
convolution계층에서는 전체 데이터를 이용하지 않고, 일정크기의 데이터만 사용하여 출력값을 계산함으로써 연산속도를 향상시킨다.
일정크기의 데이터 즉, 커널의 크기 중 가운데 값의 위치로 출력 데이터의 위치를 정하는데, 이 경우 사이드에 출력값이 정해지지 않는다.
이를 해결하기 위한 방법으로 padding, valid, 건너뛰기 방식이 있다.
- padding은 입력데이터의 한칸씩을 0으로 채워 모든 데이터를 출력하도록 하는 방법이다.
- valid는 그냥 범위를 넘어가는 값은 출력하지 않아 출력값의 크기가 입력값의 크기보다 작아지게 된다.
- 건너뛰기 방식은 출력값에서 원하는 값만 사용하는 방법으로, 보폭을 정해주면, 그 보폭중에 하나만 출력하도록 한다.
pooling계층은 일정 영역으로 부터 최대값이나 평균값을 구해서 그 값을 출력값으로 사용하는 방법이다. 이 때 일정영역을 잘 정하는 것이 중요하다.
이 때 파라미터가 필요없으므로 이 계층에서는 학습이 이뤄지지 않는다. 오직 정보를 압축. 즉, 해상도를 줄이는데 사용된다.
흑백의 사진의 경우 입력층의 채널이 1개이고 칼라 사진의 경우 채널이 3개로 정해져있지만, (R, G, B) 중간층이나 출력층에서의 채널은 임의로 조정이 가능하다.
채널을 늘려서 안에 특징을 확인하고, 더 많은 정보를 얻을 수 있다.
파라미터를 나타내고 필터 역할을 하는 커널은 4차원 구조로 되어있으며, 출력 채널 수 만큼 존재해야한다.
입력층과 커널을 통해 나온 출력값을 feature map이라고 한다
아담 알고리즘
때에 따라 맞는 학습률을 적용하여 경사하강법의 동작을 보안하고 더 좋은 학습 품질을 나타내는 방법.
모멘텀이라는 정보를 이용하여 학습률을 조정한다.
학습이 이뤄질때마다 학습률을 재계산한다. 즉, 파라미터값들과 모멘텀 정보까지 계산이 이뤄짐으로 계산 부담이 증가한다.
정규화 기법
일부러 제한을 주어 과대적합을 방지하는 방법.
L1
일정하게 정해진 값을 덜어내는 방법으로 파라미터가 작으면 0에 가까운 값으로 바꿔주어 특성의 영향을 제거한다.
L2
L1과 반대로 특성이 큰값에 영향을 주는 방법으로 특성이 클경우 값을 작게 만들어 과적합을 막는다.
Drop out
하나의 네트워크를 작은 여러개의 네트워크로 쪼개서 계산하는 방법으로 각각의 과적합을 방지하고 하나로 합치는 방법이다. 하지만 쪼개서 계산하다보니 계산량이 증가하다.
Batch Normalization
각층의 출력값 분포가 골고루 분포되어 정규분포를 이루도록하여 학습의 불균형을 방지한다.
LSTM
RNN의 경우 장기 메모리가 손실되는 것을 방지하기 위해 나온 방법으로 장기 메모리와 단기메모리를 따로 관리하는 방법이다.
<전체 순서도>
1. 데이터를 불러와서 훈련, 테스트로 나눈다.
2. 스탑워드를 제거하고, 토큰화 진행.
3. 유의미한 단어의 개수를 세어 단어 인덱싱을 진행.
4. 문장의 길이를 통일해주는 패딩 진행.
5. 훈련모델을 정하고 레이어를 쌓아 모델을 훈련
6. 값을 입력하여 테스트 진행.
CNN
이미지 처리시 이용하는 CNN을 자연어처리에서도 좋은 성능을 보인다. 이는 주변의 정보를 이용하여 특정 정보를 얻어내는 방식을 사용한다는 것이 비슷하기 때문이다.
model = Sequential()
model.add(Embedding(7792, 32))
model.add(Conv1D(256, 3, padding='valid', activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))위와 같이 단어를 먼저 임베딩을 하고
convolution계층을 거친다. padding은 vaild방식을 사용한다.
그 후 pooling계층을 거치는데, 이때 최대값을 찾는 방식을 사용한다.
출력계층으로 데이터를 보내기 위해서 feature map을 1차원으로 바꿔주는 flatten계층이다.
지금은 이진분류를 진행하기 때문에 출력값이 1개이며, sigmoid를 통해 값을 0과1사이의 값으로 바꿔준다.
다중분류의 경우 출력값을 정수로 인코딩하는 과정이 필요한데 이를 카테고리라 한다.
category_list = pd.factorize(news_data['category'])[1]
news_data['category'] = pd.factorize(news_data['category'])[0]pandas에 factorize를 이용하여 출력값이 여러개고, 그 값이 정수가 아닐경우 컴퓨터는 인식이 불가하다. 따라서 이를 정수값으로 바꿔주는 과정이다.
Decision Tree
결정트리는 회귀로도 분류문제에도 사용하는 모델이다. 분할과 가지치기를 과정을 반복하며 학습을 한다.
모델을 만드는 방법은 다른 코드들과 똑같으나 이를 트리로 시각화하는 방법은 두가지가 있다.
import graphviz
export_graphviz(model, out_file="tree.dot",
class_names=iris.target_names,
feature_names=iris.feature_names,
impurity=True, filled=True)
# "tree.dot" 파일을 graphviz 가 읽어서 주피터 노트북에 시각화
with open("tree.dot") as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))위와 같이 graphviz를 다운받고 설치한 후에 이를 사용하면 트리를 출력할 수 있다.
impurity는 진위개수를 출력, filled는 색상을 추가하는 인자인다.
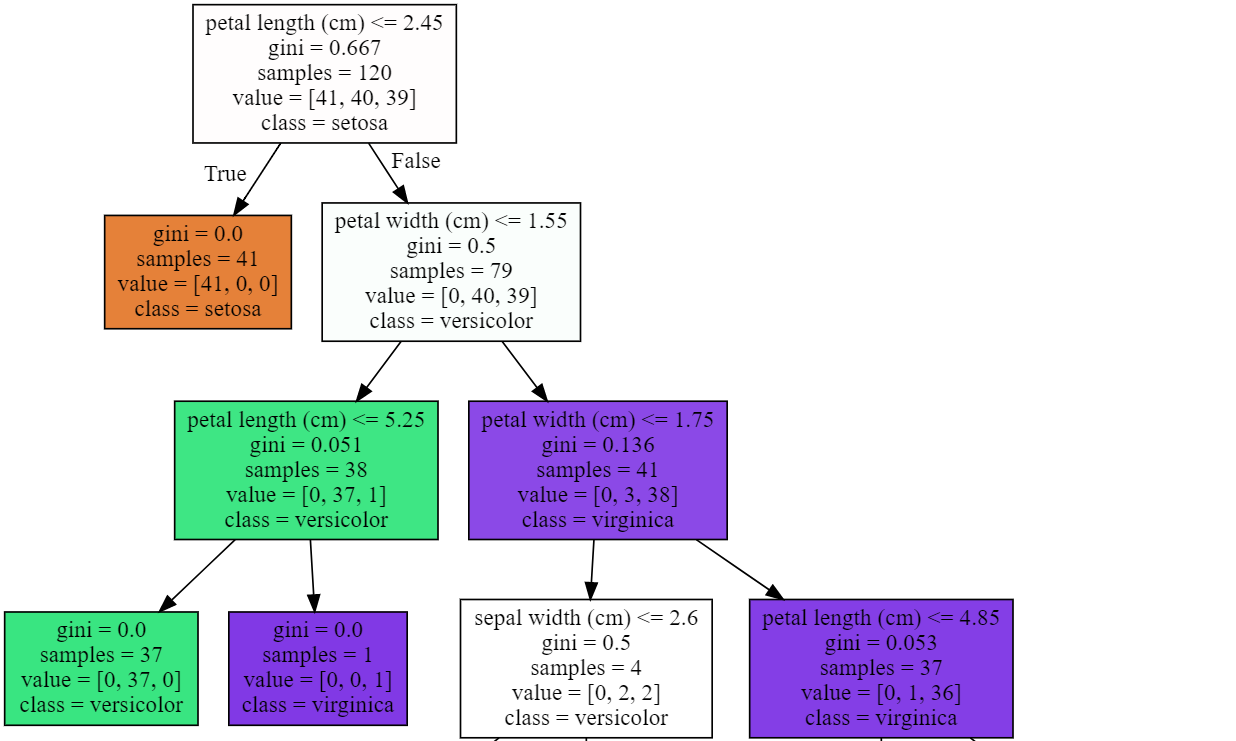
다른 방법으로는 사이킷런 0.21버전 이후에 추가된 방법으로 matplotlib을 이용하여 트리 그래프를 그릴수 있다.
import matplotlib.pyplot as plt
from sklearn import tree
plt.figure(figsize=(20, 15))
tree.plot_tree(model,
class_names=iris.target_names,
feature_names=iris.feature_names,
impurity=True, filled=True,
rounded=True, fontsize=14)위와 같은 방법으로 디자인이 가능하다.
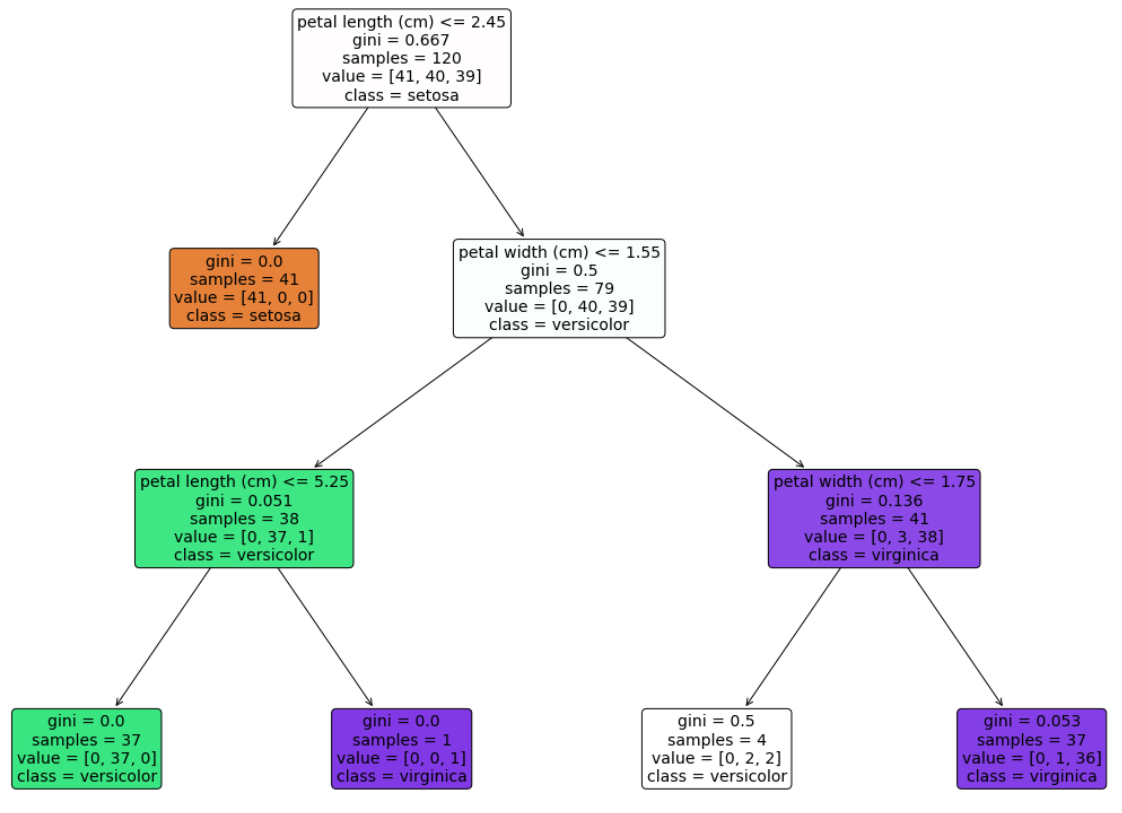
결정트리의 회귀는 훈련데이터의 값은 100%로 예측이 가능하나, 범위 외에 데이터는 예측이 불가능하다.
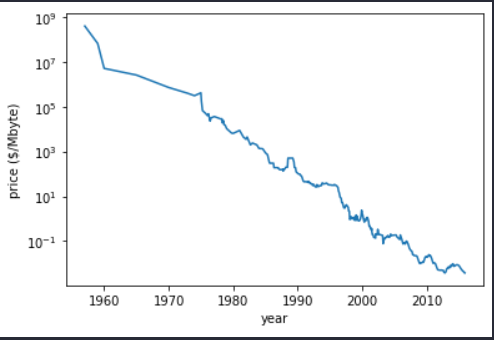
이렇게 그려지는 데이터가 있다.
이를 결정트리 회귀와 선형회귀를 통해 2000이상의 데이터를 예측해보자.
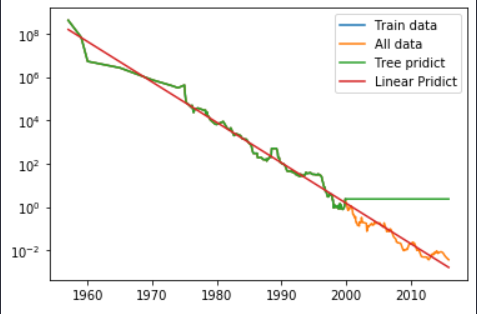
선형회귀인 빨간선은 데이터와 비슷하게 그래프가 그려지는 반면에 초록색인 결정트리 회귀는 예측이 불가능하다는 것을 알 수 있다.
