
tensor(텐서)
데이터를 표현하는 단위.
import torch
x1 = torch.tensor([1.])
print(x1)
# tensor([1.])
x2 = torch.tensor([3.])
print(x2)
# tensor([3.])텐서끼리의 사칙연산 모두 가능하며 이를 하기 위해 내장 모듈이 존재한다.
torch.add(x1, x2) # == x1 + x2
# tensor([4.])
torch.sub(x2, x1) # == x2 - x1
# tensor([2.])
torch.mul(x1, x2) # == x1 * x2
# tensor([3.])
torch.div(x1, x2) # == x1 / x2
# tensor[0.3333.])tensor로 벡터, 행렬, 텐서도 가능하며 이 또한 사칙연산이 가능하다(내장모듈도 존재)
x_vector = torch.tensor([1., 2., 3.])
x_matrix = torch.tensor([[1., 2.], [3., 4.]])
x-tensor = torch.tensor([[[1., 2.], [3., 4.], [5., 6.]]])여기서 텐서는 2차ㅣ원 이상의 배열이라고 표현할 수 있다.
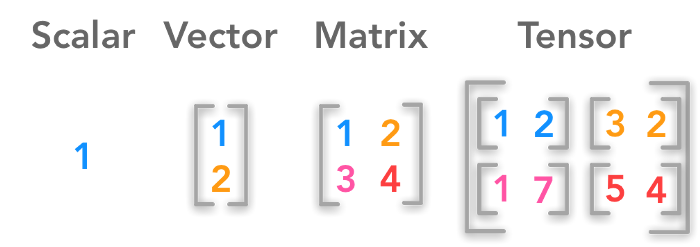
출처 : https://towardsdatascience.com/linear-algebra-for-deep-learning-506c19c0d6fa
Autograd
파이토치로 코드를 작성할 때 역전파를 이용하여 파라미터를 업데이트할 때 사용한다.
import torch
if torch.cuda.is_available():
DEVICE = torch.device('cuda') # use GPU
else:
DEVICE = torch.device('cpu') # use CPU파이토치를 사용할 환경을 확인하고 그에 맞는 환경으로 DEVICE를 설정해준다.
BATCH_SIZE = 64
INPUT_SIZE = 1000
HIDDEN_SIZE = 100
OUTPUT_SIZE = 10BATCH_SIZE
모델에서 파라미터를 업데이트 할 때 계산되는 데이터의 개수이다. 이를 이용하여 output을 계산하고 이 수만큼 출력된 결괏값에 대한 오찻값을 계산하고 이를 이용하여 역전파를 적용한다.
INPUT_SIZE
모델에서 input의 크기이자 입력층 노드의 수를 의미한다. 위에서 선언한 대로 입력데이터의 크기가 1000이고 배치 사이즈가 64이므로 1000크기의 벡터값을 64개 이용한다는 의미이다.즉, (64, 1000)
HIDDEN_SIZE
input을 다수의 파라미터를 이용해 계산된 결과에 한번 더 계산되는 파라미터의 수이다. 즉, 입력층에서 은닉층으로 전달됐을때, 은닉층의 노드의 수이다.
예를 들면, (64, 1000)의 input들이 (1000, 100)크기의 행렬과 행렬 곱을 계산하기 위해 설정한 수이다.
OUTPUT_SIZE
모델에서 최종으로 출려되는 값의 벡터의 크기를 의미한다.
예를 들어 설명해보자.
x = torch.randn(BATCH_SIZE,
INPUT_SIZE,
device = DEVICE,
dtype = torch.float,
requires_grad = False)
y = torch.randn(BATCH_SIZE,
OUTPUT_SIZE,
device = DEVICE,
dtype = torch.float,
requires_grad = False)
w1 = torch.randn(INPUT_SIZE,
HIDDEN_SIZE,
device = DEVICE,
dtype = torch.float,
requires_grad = True)
w2 = torch.randn(HIDDEN_SIZE,
OUTPUT_SIZE,
device = DEVICE,
dtype = torch.float,
requires_grad = True)x는 입력, y는 출력, w1, w2는 중간레이어를 의미한다.
여기서 requires_grad는 Gradient를 계산할지 안할지를 결정하는 것이다.
x = (64, 1000) 크기의 데이터가 생성되며 gradient계산이 필요없기 때문에 이는 False로 설정한다.
y는 출력값이며 배치 사이즈 만큼 결괏값이 필요하다.
w1은 히든사이즈인 100의 크기를 맞추기 위해 (1000, 100)크기의 데이터를 생성해야한다. gradient를 계산해야하기 때문에 requeires_grad = True로 설정했다.
w2는 출력사이즈를 맞추기 위해서 (100, 10)의 크기의 데이터를 생성해야한다. w2 역시 역전파를 통해 업데이트를 해야하므로 requires_grad = True로 설정한다.
