파이썬과 라이브러리
Matplotlib
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline # mahic commend 이는 주피터 노트북이 이해하는 구문이다시각화를 위해 사용하는 라이브러리를 불러온다.
x = np.array(['A', 'B', 'C', 'D']) # x는 수치형이 아니다
y = [10, 11, 9, 9.5]
plt.bar(x, y, color='green')
plt.title("BAR CHART")
plt.show()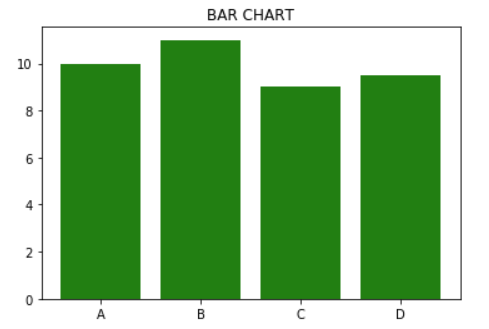
bar차트를 출력하는 방법이다.
bar차트는 유형별 통계치 비교(ex)반별 성적비교)하거나, 명목형(범주형)자료를 요약하는데(ex)여자 남자의 수를 카운트하여 막대로 표현)사용한다.
color로 내가 원하는 색상을 지정해주고, x는 레이블, y는 수치값들의 배열을 입력해주어서 차트를 출력해주었다. 이 그래프는 x, y의 길이가 같아야한다.
(* frequency : 도수)
np.random.seed(123)
x = np.random.randn(10000) # randn은 정규분포로 생성한 랜덤 숫자이다.
y = 2 * np.random.randn(10000) + 2
plt.hist(x, bins=80, color='blue', density=True, alpha=0.3)
plt.hist(y, bins=80, color='red', density=True, alpha=0.3)
plt.title('HISTOGRAM') # 그래프 제목
plt.xlabel("X") # x축 이름
plt.ylabel("Density") # y축 이름
plt.show()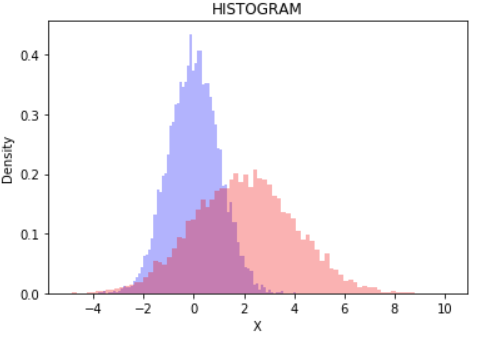
히스토그램을 그리는 방법이다.
이 그래프는 수치형자료의 분포, 이상값이 있는지 확인(이상하게 높게 나와있는 값이나 멀리 떨어진 곳에 값이 있다면, 이 값은 변조의 가능성이 있다.)하는데 사용한다.
bins는 계급(구간)의 개수이다.즉, 막대의 개수를 정해주는 것이다. density가 True이면 상대적인 값을 나타내주고, False면은 실제 개수를 보여준다.(y축 값이) alpha는 투명도를 나타낸다. 0에 가까울수록 투명해진다. 투명도는 두개의 그래프를 그릴경우 중복되는 값을 보기 위해 사용한다.
bins가 너무 크면 스무딩 효과가 사라지고, 너무 작으면 대략적인 값만을 얻을 수 있다. 적절한 bins를 선택하는 것이 중요하다.
(두 개 동시에 그릴때, density값을 다르게 지정하면 False로 지정한 그래프만 출력된다.)
x = np.random.randn(10000)*20-10 #폭에 해당하는 표준편차를 곱해주고 중심에 해당하는 평균을 곱해준다.
y = np.random.randn(10000)*5+20
plt.boxplot([x, y], 0,labels=['A','B'], vert=False)
plt.title("BOX PLOT")
plt.show()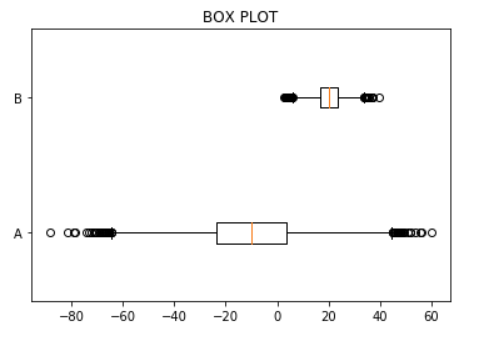
박스 플롯 그래프.
대략적인 통계 분포와 외상치(정상적인 범주에서 벗어난 값)를 파악하기 위해 사용한다.
vert는 가로 세로 방향을 나타낸다.(True는 세로, False는 가로)
이 그래프는 통계에서 많이 사용한다.
x = np.linspace(0, 10, 100)
y = np.sin(x) # x와 y의 길이가 같아야함
z = np.cos(x)
plt.plot(x, y, color='red', linewidth=2, linestyle='-.', label="Sine", alpha=0.7)
plt.plot(x, z, color='blue', linewidth=2, linestyle=':', label="Cosine", alpha=0.6)
plt.xlabel("X")
plt.ylabel("Y")
plt.xlim([-1,11]) # x구간 정의
plt.ylim([-1.5,1.5])
plt.title("LINE PLOT")
plt.legend() #범례 삽입
plt.show() 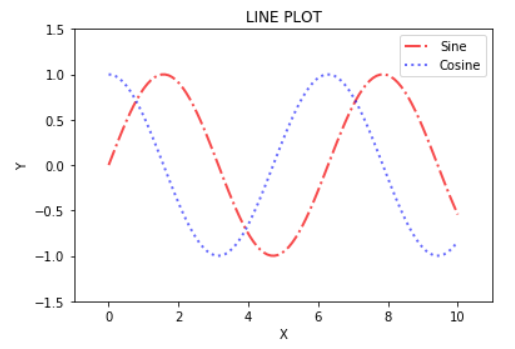
라인 플롯 그래프.
시계열 자료의 추세를 알고자 할때 이 그래프를 사용한다.
x의 값이 정렬된 경우에만 제대로 된 그래프를 얻을 수 있다. x의 값이 많을 수록 스무드한 결과를 얻을 수 있다.
label을 지정해준 다음, legend를 선언해줌으로써 범례를 선언할 수 있다.
x = np.random.randint(0, 100, 1000)/10
y = np.sin(x) # x와 y의 길이가 같아야함
z = np.cos(x)
plt.plot(x, y, color='red', marker='v', linestyle='none', label="Sine", alpha=0.3)
plt.scatter(x, z, c='blue', marker='o', label="Cosine", alpha=0.3)
plt.xlabel("X")
plt.ylabel("Y")
plt.xlim([-1,11]) # x구간 정의
plt.ylim([-1.5,1.5])
plt.title("SCATTER PLOT")
plt.legend() #범례 삽입
plt.show() 
x = np.linspace(0,10,100)
y = np.sin(x)
plt.plot(x,y,marker='o',linestyle='none',markersize=15,markerfacecolor='yellow',markeredgecolor='purple',markeredgewidth=2, label='wow')
plt.xlabel('X')
plt.ylabel('Sin')
plt.title('SCATTER PLOT')
plt.legend()
plt.show()
산점도 그래프
가로와 세로 데이터 사이의 관계를 알아보기 위해서 사용한다. 라인플롯과 비슷하지만, 라인플롯은 x축이 정렬된 데이터에서만 사용하지만, 산점도는 아닌 경우도 사용이 가능하다.
관계의 패턴을 찾아서 이 패턴을 가지고 학습시키는 것이 머신러닝이다. 이 방법을 선형회귀라고 한다.
<시각화의 목적>
- 분석가의 개인의 이해
- 패턴 여부를 눈으로 확인. 패턴이 없으면 학습이 불가하다.
