활성화 함수
딥러닝 네트워크에서 노드에 들어오는 값들에 대해 바로 다음 레이어로 전달하지 않고 비선형 함수를 주로 통과 시킨 후에 전달한다. 이 때 사용하는 비선형 함수를 활성화 함수(activation function)이라고 한다.
비선형 함수를 사용하는 이유는 멀티퍼셉트론을 경우, 선형함수로 값을 계속 전달하면 계속 똑같은 선형함수 식이 된다.
예를 들면,
라는 선형 활성화 함수를 사용하고, 3개의 레이어를 쌓은 멀티 퍼셉트론이 있다고 하자.
이 경우를 식으로 나타내면
결국 같은 선형 함수가 된다.
즉, 은닉층이 없는 네트워크로 표현하게 된다.
따라서 뉴럴 네트워크에서 층을 쌓는 혜택을 얻고 싶다면 활성화 함수로 비선형 함수를 사용해야한다.
비선형 활성화 함수에는 다양한 종류가 있다.
1. 시그모이드 함수(Sigmoid)
가장 대표적인 활성화 함수로 Logistic 함수라고도 부른다.
0~1사이의 값으로 제한되며, 값이 무한히 커지면 1에 수렴하고, 값이 무한히 작아지면 0에 수렴한다.
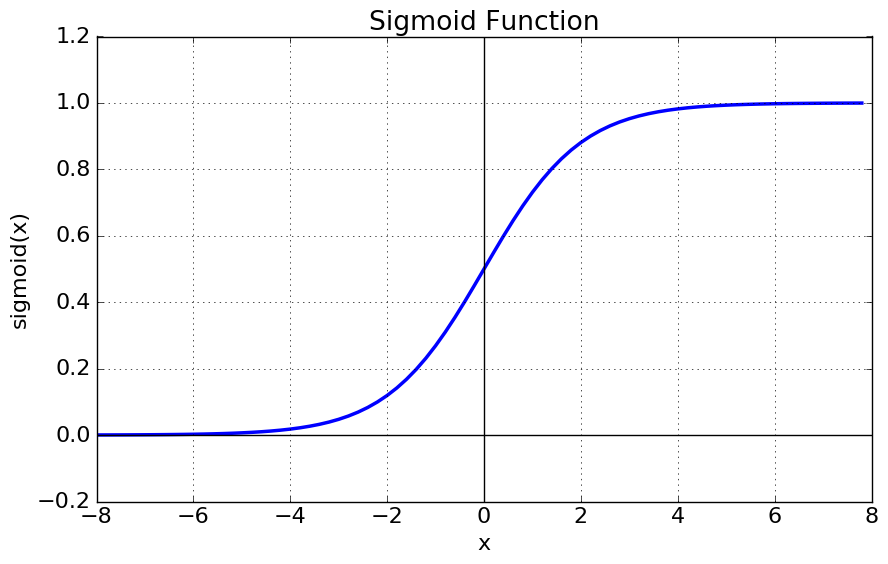
신경망 초기에는 많이 사용했지만, 최근에는 여러 단점들로 인해 잘 사용하지 않는다.
(나는 처음에 배울때 이걸로 배웠던거 같은데...)
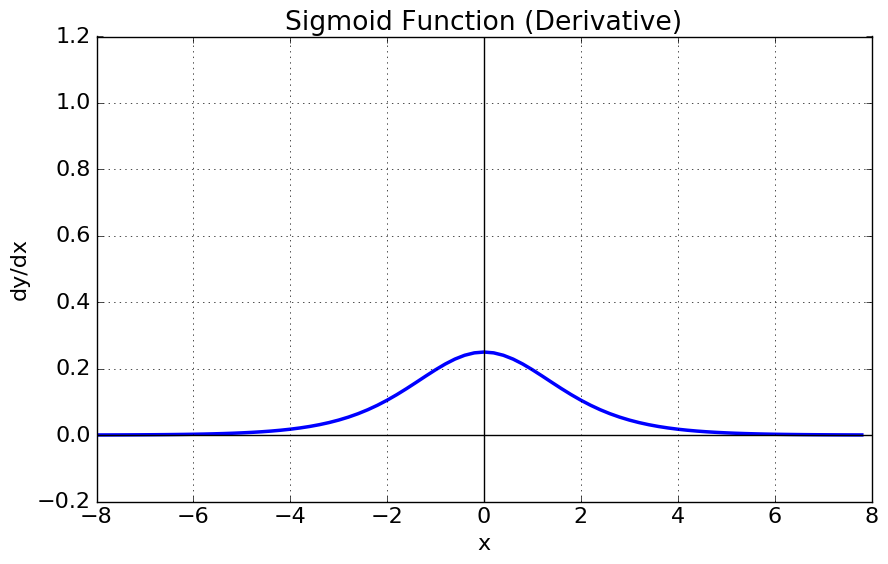
Gradient Vanishing : 미분한 함수를 보면 x=0에서 최대값 1/4을 가지고, input값이 일정 이상 올라가면 미분값이 거의 0에 수렴한다. 이는 |x|이 커질 수록 Gradient Backpropagation시 미분값이 손실될 가능성이 크다.
함수값 중심이 0이 아니어서 학습이 느려질 수 있다
한 노드에 대해 모든 파라미터의 미분값은 모두 같은 부호를 같게 된다. 따라서 같은 방향으로 update되는데 이러한 과정은 최선의 파라미터를 직선으로 찾는게 아니라 지그재그로 찾게 되어 학습이 오래 걸린다.
exp 함수 사용 시 연산이 느리다
2. tanh 함수 (Hyperbolic tangent function)
탄젠트 함수를 -90도 회전시킨 모양의 그래프.
-1~1사이의 값으로 제한되며, 음수의 무한대로 가면 -1에 수렴하고, 양수의 무한대로 가면 1에 수렴한다.
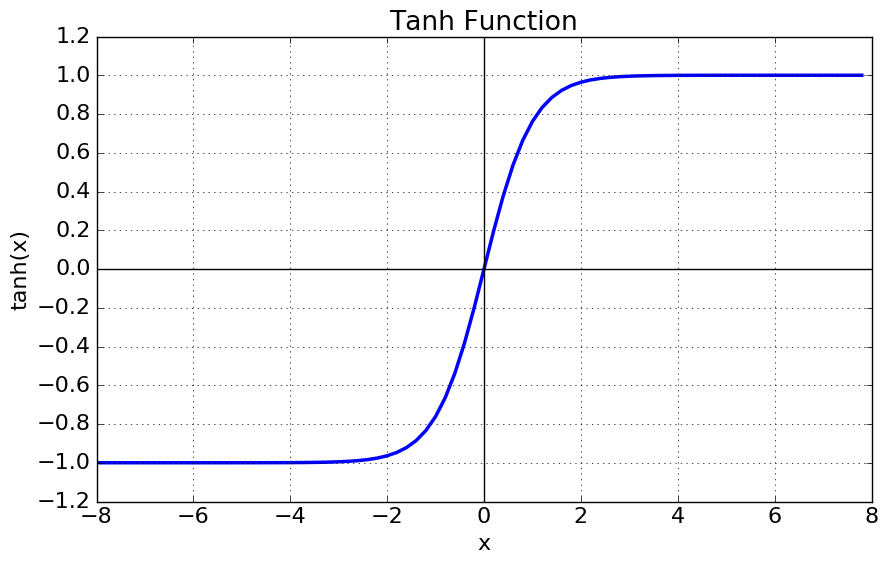
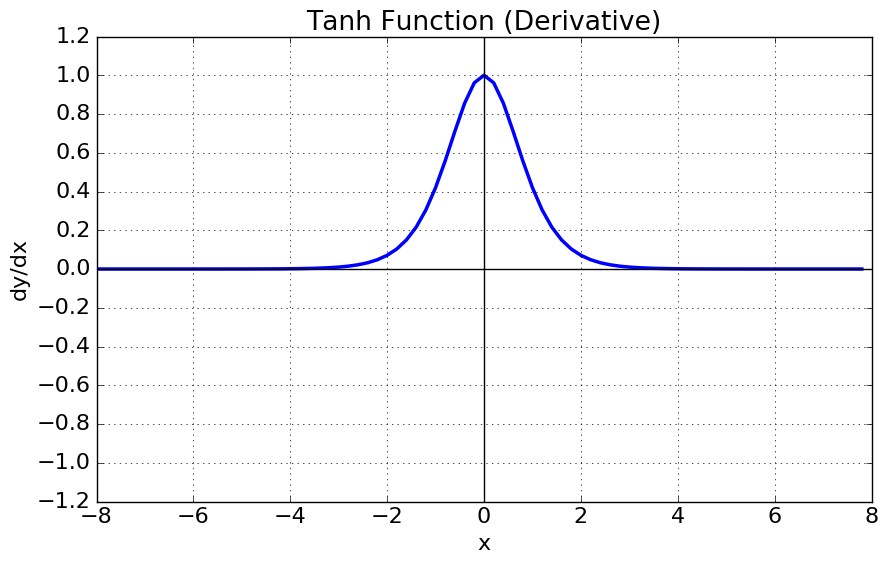
- 미분함수의 중앙값을 0으로 옮김으로써 최적의 파라미터를 찾는 과정에서 학습이 오래걸리는 문제를 해결했다.
- 하지만 양쪽 극한이 0으로 수렴하면서 미분값이 손실되는 gradient vanishing 문제는 여전했다.
3. ReLU 함수(Rectified Linear Unit)
최근에 가장 많이 사용되며, 다음과 같이 정의된다.
x>0이면 기울기가 1인 직선, x<0이면 0이 된다.
연산량이 적어 학습이 빠르고, 구현이 매우 간단하다.
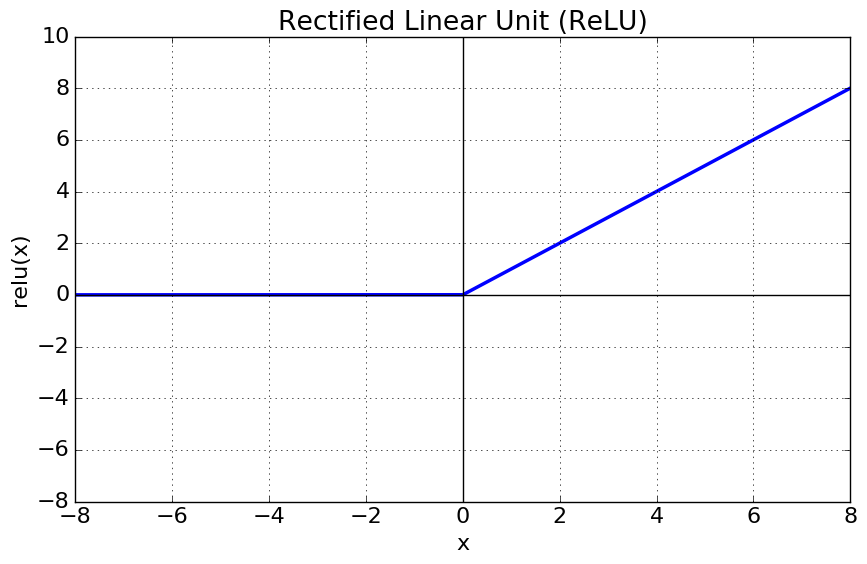
x<0인 값들에 대해서는 기울기가 0이기 때문에 죽었다라고 한다.
4. Leakly ReLU
ReLU의 x<0때, 죽는 현상을 해결하기 위해 나온 함수.
파라미터 a가 이 함수의 Leakly 정도를 결정한다. 보통은 0.01
하지만 a=0.2일때가 0.01일때보다 더 좋은 성능을 보임.
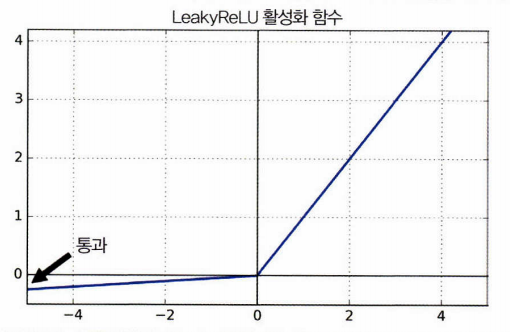
x<0때, 기울기가 0이 되지 않는다는 점을 제외하면 ReLU와 같다.
5. PReLU(Parameter ReLU)
LeaklyReLU와 비슷하나 a값이 훈련하는 동안 학습된다. 즉, 다른 하이퍼 파라미터와 같이 역전파를 통해 학습을 진행.
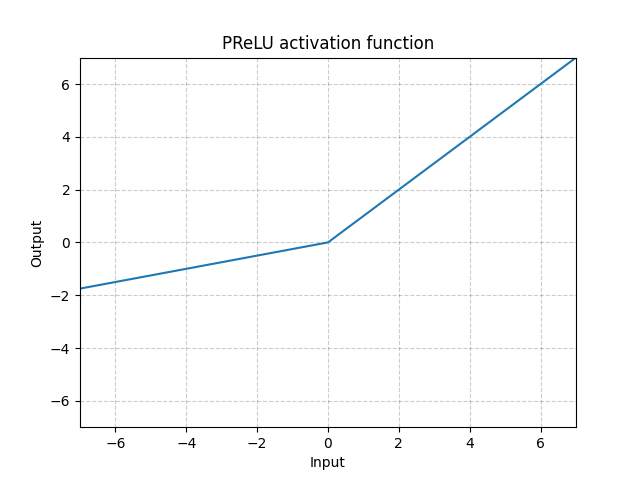
대규모의 데이터에서는 더 좋은 성능을 보이나, 소규모의 데이터에서는 과적합 가능성이 있다.
6. RReLU(Random ReLU)
LeaklyReLU의 a값을 랜덤으로 선택하여 학습하고, 테스트 시에는 평균을 사용한다.
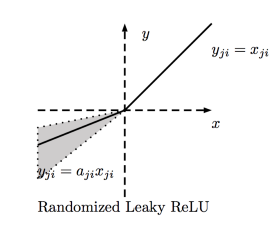
PReLU와 마찬가지로 대규모에서는 좋은 성능을 보이나, 소규모에서는 과적합의 위험이 있다.
7. ELU(Exponential Linear Unit)
이 함수 또한 ReLU의 변형이다. 훈련시간은 줄고 신경망의 테스트 세트 성능도 높았다.
x<0일 때, 지수함수를 이용하여 미분 함수가 끊어지지 않고 이어진 형태이다. 만약 계단과 같은 끊어지는 함수를 사용하면 Loss Func이 울퉁불퉁한 상태로 정의되어 local optima가 발생할 수 있다.
a의 값은 보통 1로 지정한다.
(a가 1이 아닌 값을 가진 경우는 SeLU라고 한다.)
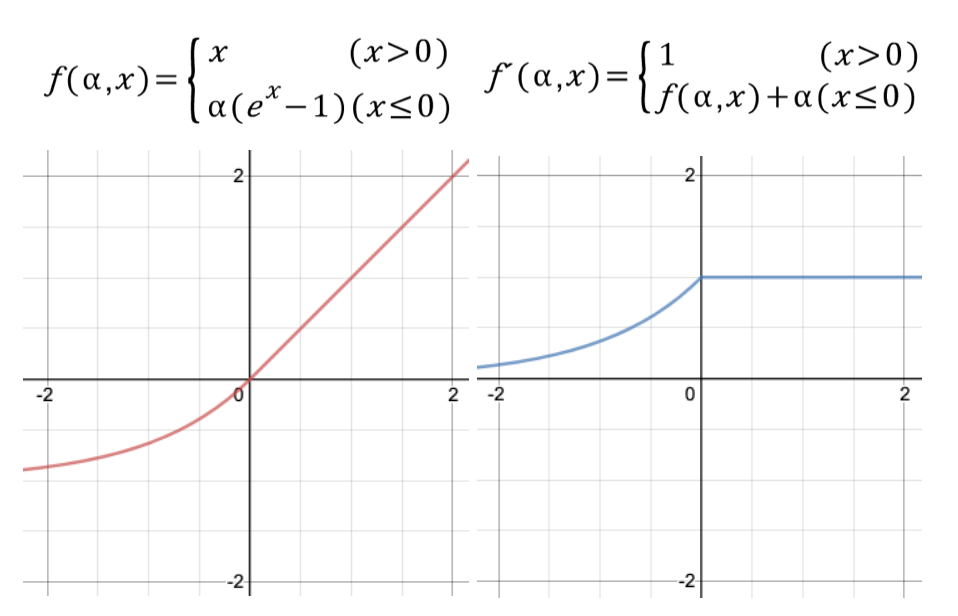
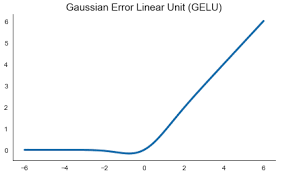
8. GELU(Gaussian Error Linear Unit)
최근 NLP분야의 BERT, ALBERT등에서 많이 사용되고 있다.
베르누이 distribution의 함수와 ReLU의 곱으로 표현한 함수이다.
네트워크가 깊어질수록 더 잘 작동한다.
마지막 정리
- 일반적으로 SELU > ELU > LeaklyReLU > ReLU > tanh > sigmoid순으로 사용한다.
- 네트워크가 자기 정규화가 안되면 SELU보단 ELU
- 실행 속도가 중요하다면 LeaklyReLU
- 시간과 컴퓨팅 파워가 충분하다면 교차 검증을 사용해 여러 활성화 함수 평가
- 신경망이 과적합되었다면 RReLU
- 훈련세트가 아주 크다면 PReLU
- ReLU가 가장 널리 활성화되어 많은 라이브러리가 ReLU에 최적화. 따라서 속도가 중요하다면 ReLU관련을 사용하는 것이 좋다.
